[论文阅读] Look Closer to Supervise Better: One-Shot Font Generation via Component-Based Discriminator
1. pre
title: Look Closer to Supervise Better: One-Shot Font Generation via Component-Based Discriminator
paper: https://arxiv.org/abs/2205.00146
code: https://github.com/kyxscut/CG-GAN
ref: https://www.bilibili.com/video/BV13Y411w7yL
ref: https://zhuanlan.zhihu.com/p/366993073
ref: https://zhuanlan.zhihu.com/p/38485843
关键词:字体生成、One-Shot、组件信息
阅读理由: one-shot效果吸引人,而且开源
注:2023-1-17翻新
针对问题
FFG任务困难,推理时数据少,难以维持局部风格或字形结构细节,总结前人经验,粗粒度判别器不足以监督字体生成。为此提出了Component-Aware Module (CAM)。

图1 三个不同字体风格的同一文本(采用了视频里的截图,比原论文图1更丰富些)
看图1,人类评判字体风格更注重局部细节,如端点形状、笔锋、笔画粗细、连笔等等(endpoint shapes, corner sharpness, stroke thickness, joined-up writing pattern)。虽然组件体现不出倾斜度、长宽比等字体风格属性,但作者觉得比整个字的形状更能决定字体风格。此外人类学写字时先学一个个组件,组件都学会自然就会写字,藉由以上两点提出了组件引导的生成网络,即CG-GAN。
FFG两个意义:减轻字体设计负担、创建跨语言字库。
核心思想
本篇是一种 one-shot 的字体生成方法,也是基于对汉字进行组件分解。绿色的生成器G基于SAGAN,经典双编码器解耦风格、内容特征,采用AdaIN在Mixer中混合风格和内容并得到生成图片\(I_g\)。\(I_g\)一方面送入橙色的D计算对抗损失,另一方面经过蓝色CAM里的特征编码器F得到特征H。H通过注意力解码器预测出每个组件,并与target计算交叉熵,同时也得到了注意力图,后续通过CLS跟\(D_{comp}\)计算其他损失。
相关研究
Image-to-Image Translation
Pix2pix是I2I任务第一个通用框架,基于对条件对抗网络跟有监督学习,缺点是需要配对数据。UNIT是CoGAN的扩展,结合GAN跟VAE学习域之间的联合分布。CycleGAN使用循环一致损失做无监督图片转换,与此同时还有DiscoGAN跟DualGAN也是用循环一致性约束做非配对I2I转换。
但上述都仅限于在两个类别之间转换图片。后面有一些做多类别无监督的I2I,能在多个已知类别间转换。FUNIT进一步扩展了生成能力,通过学习分别编码内容和类别图片可以处理未知类别。
Few-shot Font Generation
早期方法基于I2I框架,如Rewrite就是用的pix2pix,它只能学习一种风格映射,要学新风格就必须重新训练。zi2zi通过预训练的风格类别嵌入实现多个风格的学习。DC-Font使用特征重建网络在深度空间学习两个字体间的转换关系,但这些都无法泛化到未知风格。
之后EMD和SA-VAE提出解耦风格内容得以泛化到未知风格,但无法捕捉局部风格样式,而且EMD由于损失函数的设计有问题,结果不好。
近来一些方法利用了组合式的思想,但仍有严重缺陷。CalliGAN基于学过的组件标签跟风格标签嵌入来产生字形图片,因此无法用于其他未知的风格或组件。RD-GAN使用组件抽取模块(radical extraction module)以one-shot方式生成未知字形,但只能迁移到固定的目标字体风格。
LF-Font和DM-Font通过组件级风格改进了生成质量。DM-Font用双存储器架构,需要包含了所有组件的参考集来抽取存储的信息,对于FFG场景是无法接受的(推理时没有那么多字,覆盖不了所有需要的组件)。LF-Font用低秩矩阵分解,基于组件级的风格特征可以扩展到未知风格,但视觉质量在one-shot场景严重下滑。
这些基于组件的方法成功编码多样的局部风格,但它们显式依赖组件类别输入以抽取风格特征,因此跨语言字体生成任务就无法胜任(另一种语言的组件没见过)。MX-Font利用多头编码器,每个头抽取不同局部特征,以弱组件监督方式。上述方法都需要大量的配对数据来做像素级别的强监督。
DG-Font虽然是无监督的,利用可变形跳跃连接实现,但生成结果存在伪影(characteristic artifacts),总之,SOTA的表现仍然无法让人满意。
方法(模型)流程
Overview
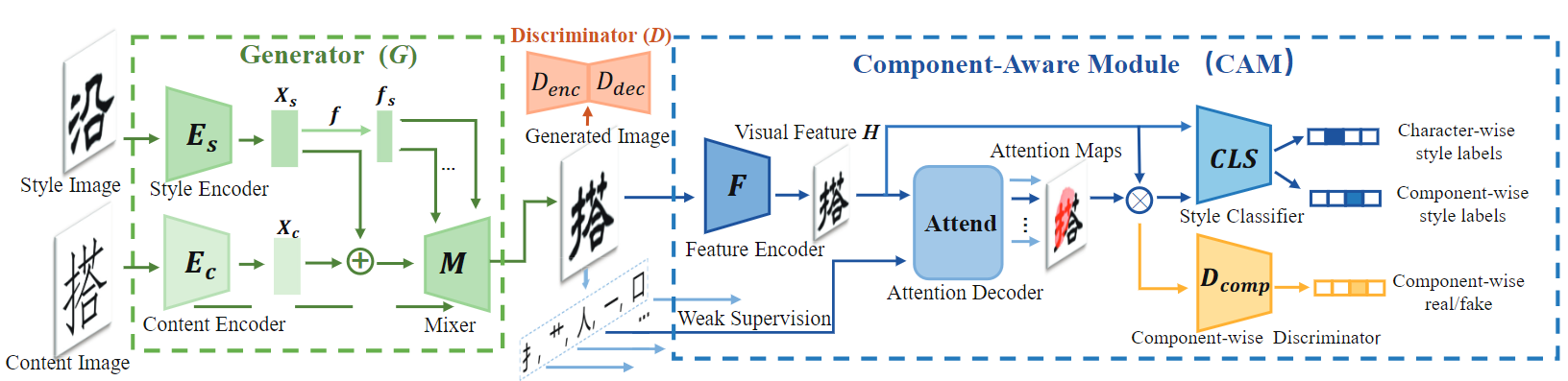
图2 所提模型总览
看图2,模型主要分成生成器G、CAM跟判别器D三个部分
方法亮点
- 性能提升是通过给予生成器更细粒度的监督信息
- 生成器能够捕捉局部风格样式,而不显式依赖于预定义的组件类别,one-shot汉字生成和跨语言字体生成效果很好
- 使用部件级监督是一种human-like方法,克服了以往方法使用成对训练数据进行像素级强监督的局限性
- CAM仅在训练阶段使用,推理时不用,没有额外计算时间
- 灵活地扩展到其另两个不同任务:手写词(英文)生成(handwriting word generation)、场景文本编辑(scene text editing)
之前的工作都是增加生成器的复杂度,这里给简单生成器更有效的监督信息,以此激发生成器的所有潜能,使其更细粒度地解耦内容和风格,这对字体生成来说是一个新视角。通过结合组件监督和对抗学习,框架效果很好,因此叫做Component-Guided GAN, 也就是CG-GAN。
Generator
如图2所示,生成器G(绿色部分)包含风格编码器\(E_s\)和内容编码器\(E_c\),以及一个mixer。输入的风格、内容图片分别记为\(I_s, \; I_c\)。注意\(E_s\)输出是风格特征图\(X_s\),跟内容特征图\(X_c\)具有相同维度。之后\(X_s\)进一步通过映射网络转换为风格潜变量\(f_s\),随后通过AdaIN将\(f_s\)注入混合器Mixer的上采样块进行全局风格渲染,这一步跟StyleGAN的操作非常像。
输入Mixer前\(X_s\)和\(X_c\)会在通道维进行拼接,同时\(E_c\)每个下采样块的输出拼接到Mixer对应分辨率上采样块的输入,即二者具有跳跃连接。随后Mixer进行特征融合并输出生成图像\(I_g\),将\(I_g\)送入判别器D(橙色部分)跟CAM(蓝色部分),得到监督信息。
设计部件感知模块CAM模仿人类学习,为生成器提供多尺度的风格和内容监督,促使其实现部件级别的风格内容解耦,引导生成器保持多尺度风格一致,字形正确性和图像真实性,使它更多地关注字形的局部细节。
Component-Aware Module
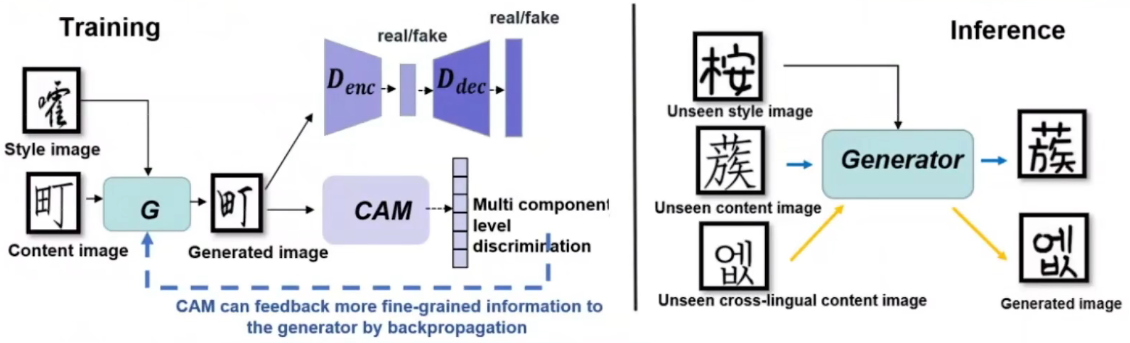
ref视频的训练/推理示意图
左图是训练示意图,CAM得到的信息将通过反向传播反馈给生成器,能够端到端进行训练(各模块都不用预训练)
右图说明生成器不显式依赖组件类别输入情况下能捕捉局部风格特征,实现跨语种字体生成
CAM是整个网络的重点,主要思想是充分利用组件信息更好地引导字体生成过程,在组件级别上监督生成器,使用如下策略:
Component extraction 每个汉字都可以遵循深度优先阅读顺序(depth-first reading order)从而拆分成一个独特的组件集,将组件抽取过程视作序列问题。
如图2CAM最左边,特征编码器F先对\(I_g\)进行特征提取\(H = F(I_g)\),其中H的维度是CxHxW,可以看成\(L = H\times W\)个元素的特征向量,每个元素\(h_i\)都是C维的向量,代表输入图片中相应的区域,记为\(H = \{h_1, h_2, \ldots, h_L\}\)
比起其他序列学习方法,如CTC和Transformer,注意力机制尤其适合,因为高效且易收敛,因此用基于注意力的解码器A来生成组件序列,记为\(Y = \{y_1, y_2, \ldots, y_T\}\),其中T是组件序列的长度,它是可变的。该解码器一次预测输出序列的一个标记,直到输出结束token EOS,对于每个时间步t输出一个组件(字符形式):
其中\(x_t\)是时间步t的输出向量,它跟着隐状态\(s_t\)更新:
其中\((g_{t},y_{p r e v})\)是 glimpse向量\(g_t\) 和 前一个输出\(y_{t-1}\)的嵌入向量 的拼接,而\(g_t\)通过注意力机制得到:
其中\(W_{o},b_{o},W_{s},W_{y},b\)都是可学习的。这个Attention Decoder将字符拆分成多个部件并借助注意力机制进行识别,相当于加入了部件级的内容监督。
H可看做输入,它是编码后的图片特征,保持不变。而\(\alpha_t\)采用加型注意力由上一步隐状态\(s_{t-1}\)、上一时间步的组件\(y_{t-1}\)得到,根据可视化结果,每个\(\alpha\)关注一个组件。根据公式6,当前时间步关注的信息\(g_t\)可以看作是根据注意力对H不同部分(组件)的汇总,体现了“注意”这个词。而\(x_t\)是中间输出,由\(g_t\)跟上一步的\(s_{t-1},\; y_{t-1}\)共同决定,它再经过线性层就得到了当前输出\(y_t\)。
这里原本放的是 Structure Retention Loss 的介绍,不过统一起见移到了Loss部分
Multi component-level discrimination
图2最右边有风格分类器 (CLS)跟组件级判别器(\(D_{comp}\)),执行组件级判别。直观上,当人类辨别不同字体风格时更注意局部组件,而不是整体形状(但形状也很重要)。这里利用特征图\({\bf A} = \{\alpha_{1},\alpha_{2},\ldots,\alpha_{T}\}, \bf \alpha_t \in \mathbb{R}^{H\times W}\)作为组建区域的标签进行风格分类跟真实性判别。
具体来说就是监督输入图片的全局和局部风格一致性:style matching loss(\(L^{CAM}_{sty}、L^{G}_{sty}\))。将代表全局信息的原始特征图和代表局部信息的加权特征图输入CLS,用识别出的风格id跟groundtruth计算交叉熵。CLS将引导生成器的\(E_s\)获得更好的特征表达能力,能够在不显式依赖组件类别输入的情况下捕捉局部风格特征。
Component-wise Discriminator \(D_{comp}\) 用于对每个component patch进行一个真假判别(输入是加权特征图),用于引导生成器更好地捕捉局部特征:Component Realism Loss \(L_{comp}\)
Loss Function
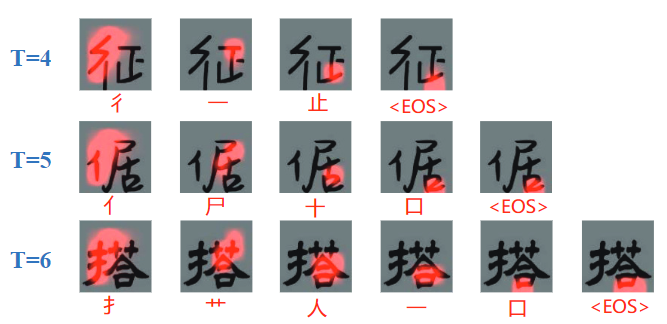
图3 不同组件序列长度的注意力图可视化。图片下面的是预测的组件
对Attention Map进行可视化,decoder能够较好地关注到部件区域,将每个时间步得到的attention map(输出是部件序列,那么一个map就对应了一个部件)跟特征图H相乘得到的加权特征图代表了对应的部件信息,可以用于后续的判别
Structure retention loss 只用组件标签作为弱监督,A通过最小化结构维持损失能集中于每个组件(localize every component),注意F跟A都只用\(I_s\)进行优化:
其中\(\hat{y}_{t}\)是时间步t相应的真值组件标签。如图3所示,每个时间步A都能集中于相应的区域,因此如果组件预测结果有误,G就会因不正确的结构转换受惩罚:
总之用A预测的部件序列计算交叉熵,\(L^{CAM}_{strc}\) 用于训练CAM,\(L^{G}_{strc}\) 则是对G的约束。通过将数量较多的字符拆分成数量较少的部件的序列,加速收敛,并引导\(E_c\)在组件级别从\(I_c\)解耦内容表达,促使\(E_c\)更加关注字形结构,保持字形一致性。
Adversarial loss 判别器基于U-Net,编码器部分\(D_{enc}\)和解码器部分\(D_{dec}\)分别负责逐图片和逐像素的判别,对抗损失如下:
其中 \([D_{d e c}(I_{s})]_{i,j}\) 表示位置(i, j)的判别器输出,实验中设置\(\lambda_{dec}=0.1\),公式看起来就是通常的对抗损失,加入\(D_{dec}\)可能是为了更精细地监督,然而代码中并没有用上
Style matching loss 除了上面提到的结构维持损失,生成图片还得保持全局和局部风格一致性,于是用CLS对整张图片进行分类,确保全局风格一致,然后再逐个组件去分类以评估局部风格一致。给定时间步t的2D注意力图\(\alpha_t\),和\(I_s\)相应的风格标签w,风格匹配损失定义如下:
这里⊗表示逐元素乘法,注意CLS也仅使用真实样本进行优化,这里应该也是个交叉熵,希望CLS能学会根据F编码的特征输出对应的风格标签。前半部分是整个字的,后半部分针对该字的每个组件,它们拥有同一个真实标签w,作者希望让G合成跟\(I_s\)高度相似的图片。相应地,G优化下面的损失:
该损失迫使\(E_s\)在组件级解耦风格表达,让它在捕捉多样局部风格时维持全局风格一致性,因此也能根据任意参考风格样本\(I_s\)准确地编码局部风格样式,而不需要相应的组件标签(应该指的是训练完在推理的时候)
Component realism loss 判别器 \(D_{comp}\) 用于对每个component patch进行真假分类,进一步在组件级监督\(I_g\)的逼真程度,感觉跟对抗损失一样,只是这里针对的是组件。这点跟Style matching loss一样,对整张图片、各个组件都进行损失计算,让生成器更注重局部细节,很符合标题的"look closer",总之损失如下:
Identity loss 此外还引入了一个 Identity Loss \(L_{idt}\)来保证网络对目标域的恒等映射,即将同一个字形给生成器,输出图像应当与输入一模一样,计算二者的L1损失:
该identity loss一定程度上能稳定训练过程,因为它避免过度的风格转换。
Content loss 使用内容损失确保抽取的组件表达\(X_c\)风格不变,也就是合成结果的内容特征应该跟内容字的内容特征一样:
Full objective 最终各部分如下进行优化:
整个框架以端到端方式从头训练,实验中设置\(\lambda_{cnt}=10\)
实验
将宋体作为源字体,因为CycleGAN不能同时学习到多个域的映射,因此训练了399个。因为LF-Font做one-shot效果太差(毕竟是few-shot的模型),于是多做了eight-shot(其论文原始设置)的实验。所有模型都是用官方代码从头训练的,但没提到训练设置、用的数据集,应该也都一样吧。
数据集
Chinese font generation: 423种字体,其中随机选399种作为训练集,每个字体取800个字(seen characters),这800字能被385个部件覆盖。评估则基于两个数据集:399种见过的字体,每个字体取150个没见过的字;另一个是剩下的24种没见过的字体,每个取200个没见过的字。此外还额外加入韩文测试集,24种字体,每个取200个字。
Handwriting generation:IAM手写数据集,由9862个文本行和62857个手写单词组成,共500个不同的人写的。实验中将training和validate集用作模型训练,测试集则留作评估
指标
使用了SSIM、RMSE、LPIPS, FID
此外还从中文测试集随机选了30个已知字体跟20个未知字体做用户调查,每次都定一个字体,让参与者从n个模型生成结果中选最好的。总之共48个参与者,收集了2400份结果。
Chinese font generation
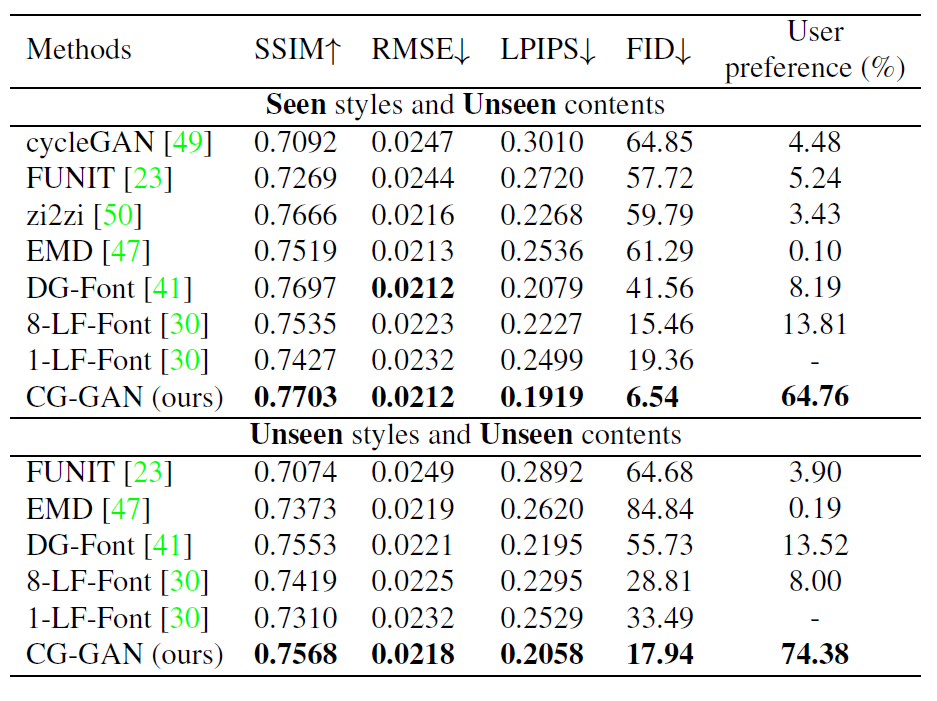
表1 整个数据集上的定量评估

图4 跟SOTA方法生成结果的比较
看表1,除了表明8-shot的LF-Font,其他都是做one-shot。可以看到CG-GAN各项指标都远超其他模型。特别是one-shot时就能超越8-shot的LF-Font(AAAI 2021),尤其是FID。跟FsFont一样,可能注意力机制确实更好。
看图4a,b,分别是在Unseen styles and unseen contents数据上的生成结果,和Cross lingual font generation上的生成结果,CG-GAN特别是在风格一致性跟结果准确度上很出色,图中各个彩色框处是作者给出的模型差距,蓝色展示了其他模型的缺陷。而图4c则是对未知组件的泛化性,说明跨语言生成性能也很优异。
Handwriting generation
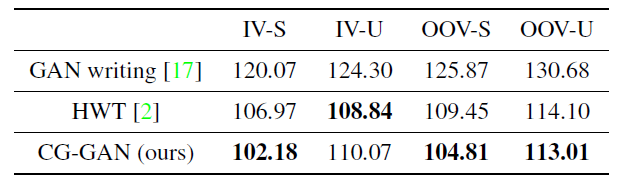
表2 Writer-relevant手写生成质量比较,共4种设置:In-Vocabulary words and seen style(IV-S), In-Vocabulary words and unseen style (IV-U), Out-of-vocabulary words and seen styles (OOV-S), Out-of-vocabulary words and unseen styles (OOV-U)

表3 Writer-irrelevant手写生成质量比较,计算FID时忽略写者身份。
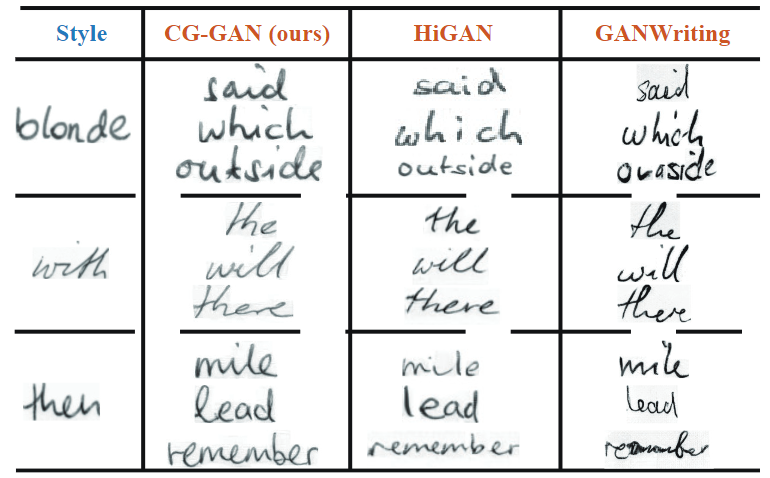
图5 合成手写单词的可视化比较。
通过耦合组件级监督跟新型框架设计,CG-GAN可以直接用于手写字体生成任务,无需任何调整。实验公平起见在下列两个场景进行比较:
Writer-relevant 手写生成。 对于每个写者单独计算相应生成样本跟真实样本之间的FID,然后取平均,能评估生成质量跟风格模拟能力。使用HWT跟GANwriting作为baseline,它们能根据参考风格合成图片。HWT是基于Transformer的,可合成任意长度的文本。GANwriting可合成不超过10个字母的短单词图片。以4种设置分别对模型进行评估:IV-S, IV-U, OOV-S, OOV-U
如表2所示,CG-GAN展现了跟SOTA有竞争力的结果,在3种设置下超越了第二好的HWT。这里作比较的两个baseline都是15-shot,训练时也需要15个风格参考,而CG-GAN仍然one-shot。
Writer-irrelevant 手写生成。 该场景下计算FID时忽略写者身份(应该是区别于按writerID分别计算再平均,这里所有图片混在一起计算FID)。使用 HWT, ScrabbleGAN 和 HiGAN作为baseline。ScrabbleGAN可以用随机风格合成长文本,但无法模拟参考风格。HiGAN可以合成任意长度的文本,使用随机或参考风格。如表3所示,CG-GAN仍然取得相对SOTA有竞争力的结果。可视化比较见图5,比较有趣的一点是模型无需其他改动,就可以直接应用到英文手写体合成任务上。
Ablation study
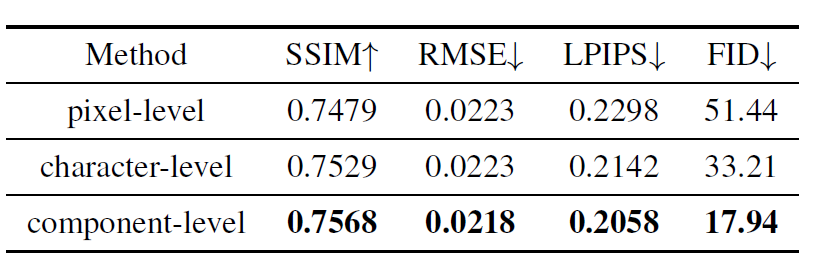
表4 组件级监督的有效性
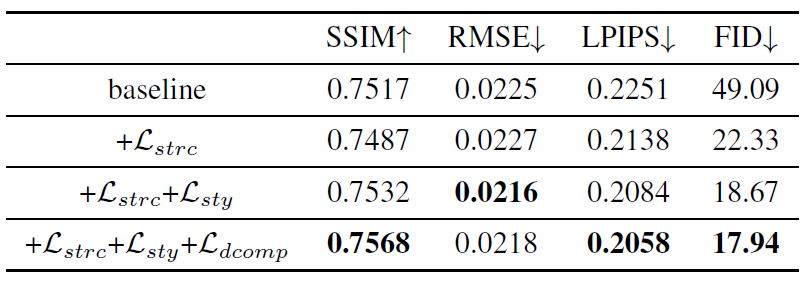
表5 CAM的有效性
进行了多个消融实验来验证CAM对one-shot中文字体生成的有效性,结果使用未知风格测试集进行测试
Effectiveness of the Component-level supervision 如表4,比较了三个层次的监督:
- 组件级监督:完整CG-GAN模型
- 像素级监督:去掉CAM模块,并用L1损失替换组件级目标函数,使用配对数据,其参考风格图片跟未配对数据设置同样
- 字符级监督:用字符标签替换组件标签
可以看出用组件监督效果最好,而且在FID指标上有显著优势
Effectiveness of the Component-Aware Module 如表5所示,将CAM换成图片级的风格分类器,将其作为baseline,这样去掉了所有组件级的监督,然后逐步加入多组件级监督的不同部分并分析影响。可以看到\(\mathcal{L}_{dcomp}\),应该是Component realism loss(\(\mathcal{L}_{c o m p}\)),用处不大,甚至掉点,这也契合了后面对判别器UNet结构的分析
Extension

图6 场景文本编辑结果
额外做了个场景文本合成(scene text editing (STE)),该任务字体风格、文本形状和背景多变,具有挑战性。现存的STE方法都是两阶段的:先渲染目标文本内容得到前景,再去掉原始文本得到背景,二者结合得到目标图片。但这种两阶段的方法对现实图片泛化性不好,因为背景前景具有强相互干扰(mutual interference)。
而本文的模型去掉了低效的多阶段渲染,借助组件级监督缓解了干扰问题。如图6所示,本文框架产生了超出预期的结果,展示了所提方法的强大潜力,实现细节见附录A。
总结
文章对于one-shot字体生成任务提出了一种简单但有效的CG-GAN,特别是引入了CAM去监督生成器,CAM更加细粒度地解耦风格内容,即在组件级别上,去指导生成器取得更好的表现能力,在one-shot字体生成取得了SOTA性能。
更进一步,CG-GAN是第一个能扩展到手写词(英文)生成handwriting word generation跟场景文本编辑scene text editing任务上的FFG方法,展现了它良好的泛化能力。
Supplementary Material
A. Implementation
A.1. Training details
模型使用Adam优化,\(\beta_1=0.5, \beta_2=0.999\),卷积和线性层权重根据高斯分布\(\Nu(0, 0.02)\)初始化。实验基于PyTorch,并且在单张1080Ti上训练,batch size=16
Chinese font generation 所有图片大小都是128x128,学习率只有0.0001,并且经过 40 epochs 训练后衰减至0,但看代码是经过30个epoch就衰减到0
Handwriting generation 图片高度都是64,宽度根据比例缩放,最大384。最初15个epoch保持学习率0.0001,然后经过30个epoch线性衰减到0。
Scene text editing 该任务的训练数据为合成的,评估时采用实际(real-world)的图片。使用SynthTiGER合成了1.4M数据 \((I_s,I'_s)\),这俩有不同的文本内容 \((T,T')\),而其他属性如背景、字体等都是一样的。训练时选\(I_s\)为风格参考输入,将\(T'\)渲染为图片,作为内容参考输入。
因为该任务缺少一个风格标签,因此将 style retention loss(前文也没提到啊,感觉是Style matching loss)设置为0,并在原训练目标基础上添加感知损失(perceptual loss)和空间相关损失(spatially-correlative loss)。
测试集采样自 IIIT5k, SVT, IC03, IC13, SVT-P, CUTE80, IC15,总共9350个图片,全都缩放到64x256,模型以0.0001学习率训练了20epoch
A.2. Network architectures
Generator architecture 生成器基于SAGAN的ResNet架构,一种编码器解码器架构,将原本编码器作为作为风格、内容编码器,使用原本解码器作为mixer,使用 channel multiplier \(ch = 64\)。
确切的说,风格跟内容编码器是一样的,都是5个ResNet下采样块组成,总的下采样率为32。mixer中编码的特征再通过5个ResNet上采样块,恢复图片原始分辨率。为了产生\(3\times H \times W\)的图片,在mixer最后一层使用 InstanceNorm-ReLU-conv2d 模块,输出通道为3。同时去掉了所有ResNet块里面的自注意力层,并在mixer每个上采样块都加入了AdaIN作为规范层(normalization layer)。
CAM architecture CAM详细架构见表6
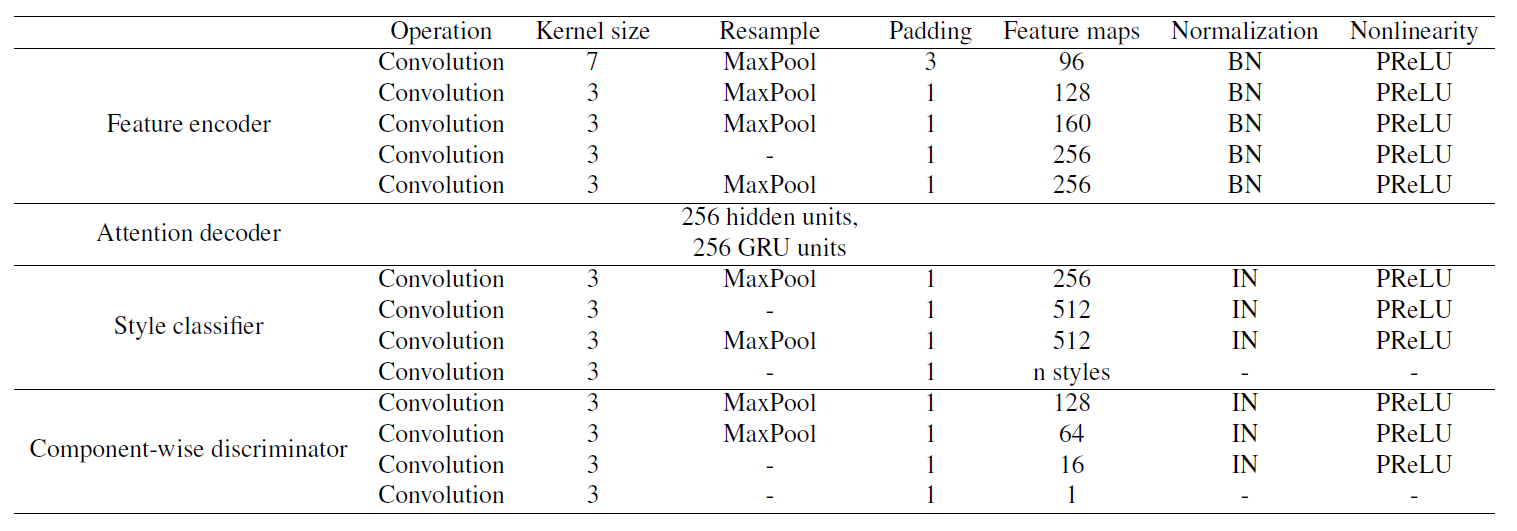
表6 CAM架构
Discriminator architecture 采用U-Net判别器架构,分辨率128x128,channel multiplier \(ch = 16\)。
B. Additional qualitative results
B.1 One-shot font generation

图7 中文one-shot字体生成,已知风格的未知内容

图8 中文one-shot字体生成,未知风格的未知内容

图9 跨语言字体生成
图7图8有更多的生成样本,这些是从两个汉字测试集里随机选30个已知字体跟20个未知字体,每个又随机采样10个未知目标字形进行的定性评估。注意这些都是one-shot进行的测试。图9展示明星能扩展到跨语言字体生成,中文字体训练用去生成韩文字体库。
B.2. Latent space interpolations

图11 两个不同风格之间的插值

图10 合成手写单词的视觉比较
如图11,展示了IAM数据集上对两个随机风格隐向量进行线性风格插值,得到良好的过渡效果,得到更多的生成样本,或许也能作为文本识别的数据增广手段。这表明CG-GAN可以泛化到风格隐空间,而不是仅记住一些特定的风格样式。
此外在图10还展示了不同书写风格的合成单词图片,每行的风格一样,内容多样。更多手写体生成效果表示模型能够很好学到局部书写风格特征,如这里字符间的连笔。仔细看会发现背景也会被学习并生成,如倒数第二行的with的灰暗背景,跟后面的场景文本编辑挺像的
B.3. Scene text editing

图12 额外场景文本编辑结果
场景文本编辑,可以看到效果很不错,会根据字数的多少自动安排字符间距,对复杂背景、倾斜、连笔(curved texts)都有较好效果
B.4. Additional ablation results
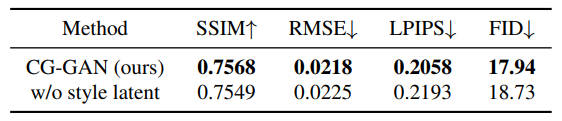
表7 风格隐向量对中文字体生成任务的影响
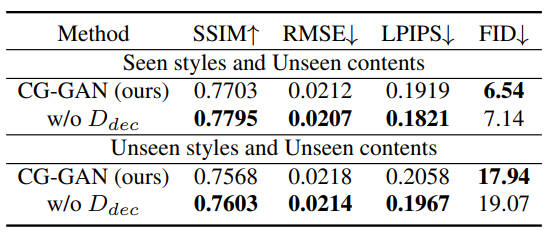
表8 判别器U-net架构对中文字体生成任务的影响
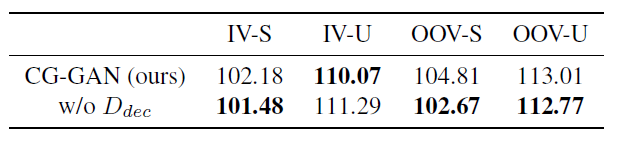
表9 判别器U-net架构对写者相关的手写生成任务的影响
Influence of the style latent vector 表7去掉了风格隐向量\(f_s\)跟AdaIN注入,可以看到没啥影响,甚至还好了一些,说明\(f_s\)不怎么必要,作者解释这就是他们主要的目的,即模型性能不取决于复杂的网络结构。但实际上代码中生成器相比判别器是复杂许多的,大概有3倍的参数差距。
Influence of the U-net Discriminator 如表8所示,去掉了判别器的U-net结构,准确来说是去掉了上采样部分的结构,只留编码器\(D_{enc}\)。作者说对于字体生成跟手写生成,分别把channel multiplier 设置为\(ch=16、64\)。
该变体在字体生成上仍然超过所有其他baseline,在手写生成上也很有竞争力,如表9所示。这表示解码器部分\(D_{dec}\)对性能没啥影响,作者猜测可能是由于数据集背景简单,许多像素值都是(255,255,255),因此像素级判别器的\(D_{dec}\)不怎么有效。实际上代码中作者已经注释掉了U-net的\(D_{dec}\)部分,却保留了\(f_s\)跟AdaIN。
评价
虽然用的都是已有的模块搭建,但注意力的运用挺有新意的,效果也不错。只是关键的 Attention Decoder 感觉不够清晰,若像其他论文单独把里面的模块再画出来就更好了。另一方面模型稍显有些大了,事实上消融实验也能看出并非所有东西都是必要的,这么多的loss有没有可能精简些效果反而更好呢?
文章组织跟一般的不大一样,多了个Extension,做的任务感觉跟字体生成关系并不大,尤其是本文的卖点在组件级监督,而场景文本编辑感觉更接近I2I,英文字母也很难说有组件。而且用的是AdaIN,这是否说明它更擅长那种纹理的、全局风格的转换任务呢?
此外虽然开源,但代码很乱,缝合感明显,逻辑奇怪而且缺乏注释,阅读/训练都很艰难。
待解明
- 一些组件应该很少出现,模型接触的少会不会影响效果?
- 字的组件序列用于计算交叉熵,为何称为弱监督?
