Master笔记 22-9-18 @MLP @结构重参数化 @RepLKNet @Depthwise Separable Convolution
MLP-Mixer: An all-MLP Architecture for Vision
pre
ref: https://zhuanlan.zhihu.com/p/369970953
ref: https://zhuanlan.zhihu.com/p/373070779
ref: https://zhuanlan.zhihu.com/p/371667365
paper: https://arxiv.org/abs/2105.01601
code(pytorch): https://github.com/d-li14/mlp-mixer.pytorch
code: https://github.com/google-research/vision_transformer
MLP(multi-layer perceptrons),多层感知机,几十年前、最基础的那个
Abstract
虽然卷积和注意力可以取得良好的性能,但它们并都不是必要的。
本文提出了MLP-Mixer,一个基于多层感知器(MLPs)的体系结构。MLP-Mixer包含两种类型的层:一种是MLPs独立应用于每一个图像patch(即“混合”每个位置的特征),另一种是MLPs应用于不同patches之间(即“混合”空间信息)。
MLP-Mixer在大型数据集或现有正则化方案上进行训练时,可以在图像分类基准上获得有竞争力的结果,其预训练和推理成本可与最先进的模型相媲美。这是一种在概念和技术上都很简单的替代方案,不需要卷积或自注意力机制。
Conclusions
我们描述了一个非常简单的视觉架构。实验表明,在训练和推理所需的准确性和计算资源之间的权衡方面,它与现有的最先进的方法一样好。
我们希望我们的研究结果能激发进一步的研究,超越基于卷积和自我关注的既定模型领域。看看这样的设计是否适用于NLP或其他领域将是特别有趣的。
原理
输入
跟ViT一样,将\(p\times p\times 3\)图片分块后,每块展平为\(3p^2\)向量,分成\(S=\frac{HW}{p^2}\)块,得到\((S, 3p^2)\)的张量,线性映射为\((S, C) = patches\times channels\)的张量,一共S个\(1\times C\)向量,每个这种向量称为1个token。
架构
1x1卷积只能结合不同channels的信息,而MLP-Mixer即可以靠channel-mixing MLPs层结合不同channels的信息,也可以靠token-mixing MLPs层结合不同空间位置的信息。
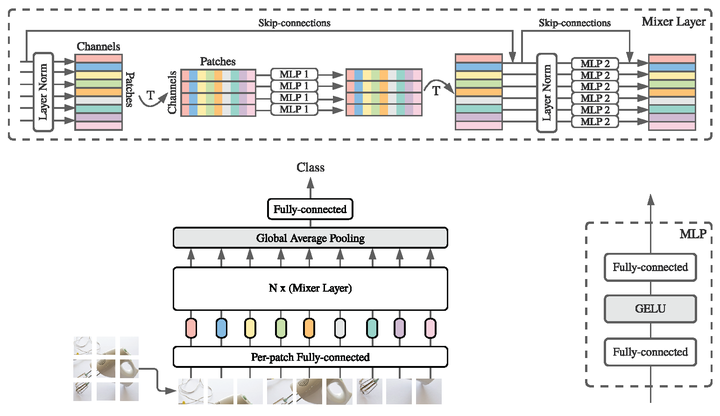
如图所示,Mixer由大小相同的多个层(Mixer Layers)和一个分类头组成。每个层由 2 个 MLP 块组成,其中,第一个块是 token-mixing MLP 块,第二个是 channel-mixing MLP 块。其中分类头就包括Global Average Pooling和一个全连接层。
每个MLP块如右下角小图所示,包含2个全连接层和中间一个GELU激活函数,给模型融入非线性成分
注:Mixer用到LayerNorm, 残差连接, GELU, 和全连接
注意
- 只有MLP层,所以MLP-Mixer的计算复杂度与序列长度S是线性相关的;而基于Transformer的ViT等模型的计算复杂度与S是平方相关的
- MLP-Mixer没有使用位置编码信息,因为token-mixing MLP把不同空间位置的信息融合起来了,所以对输入的顺序敏感,可以自动地学习到位置信息
- MLP-Mixer每一层的输入和输出的维度是一致的,与Transformer保持一致,而不是像CNN那样是pyramidal structure,即越深的层的输入分辨率越低。
实验结果
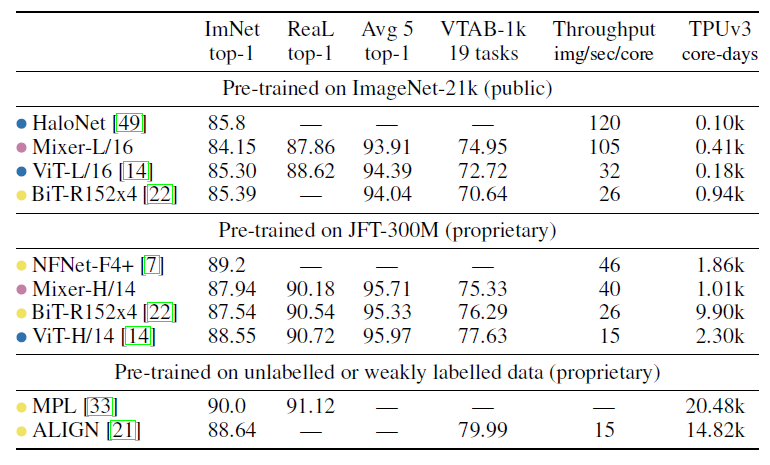
在大型数据集JFT-300和ImageNet-21k上的不同类型模型的性能对比
总结
本文提出MLP-Mixer对标CNN和Transformer,它仅仅依赖基础矩阵乘法运算、数据的布局变换 (reshapes and transpositions) 以及非线性层来完成复杂数据集的分类任务。同时结果具有竞争力(性能并非最优,但随着模型增大、数据集增大而增强,同时运行速度更快)
CNN的特点是inductive bias,ViT靠大量数据 (JFT-300数据集)使性能战胜了CNN,说明大量的数据是可以战胜inductive bias的,这个MLP-Mixer也是一样。卷积相当于是一种认为设计的学习模式:即局部假设。能够以天然具备学习相邻信息的优势,但长远看来,在数据和算力提升的前提下,相比于attention甚至MLP,可能成为了限制。因为不用滑窗,也不用attention的方法其实是CNN的母集。
早起人们放弃MLP而使用CNN的原因是算力不足,CNN更节省算力,训练好模型更容易。现在算力资源提高了,就有了重新回到MLP的可能。MLP-Mixer说明在分类这种简单的任务上是可以通过算力的堆砌来训练出比CNN更广义的MLP模型 (CNN可以看做是狭义的MLP)。
最后,channel-mixing MLPs层相当于1×1 convolution,而token-mixing MLPs层相当于广义的depth-wise convolution,只是MLP-Mixer让这两种类型的层交替执行了。
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
ref: https://zhuanlan.zhihu.com/p/344324470
ref: https://zhuanlan.zhihu.com/p/361090497
ref: https://zhuanlan.zhihu.com/p/375422742
ref: https://zhuanlan.zhihu.com/p/369970953
ref: https://zhuanlan.zhihu.com/p/373070779
paper: https://arxiv.org/abs/2105.01883
paper: https://arxiv.org/abs/2112.11081 (论文最新版本, Accepted by CVPR2022)
code: https://github.com/DingXiaoH/RepMLP
结构与参数
模型中的一个卷积层、一个block等都可以称为一个结构。我们所说的参数主要指的是
- 学得的参数(learnable params)。
- 其他在训练过程中得到的参数,如batch norm(BN)累积得到的均值和标准差。
我们主要考虑那些带参数的结构,并从参数的视角来看待这些结构。例如,一个input_channels=C, output_channels=O, kernel_size=KxK的卷积层,参数为一个OxCxKxK的四阶张量,记这个张量为W。这样我们就将W和这个卷积层建立了一一对应的关系。
既然一组参数和一个结构是一一对应的,我们就可以通过将一组参数转换为另一组参数来将一个结构转换为另一个结构。例如,如果我们通过某种办法把W变成了一个(O/2)xCxKxK的张量,那这个卷积层自然就变成了一个输出通道为O/2的卷积层。
再举个最简单的例子,两个全连接层之间如果没有非线性的话就可以转换为一个全连接层。设这两个全连接层的参数为矩阵A和B,输入为x,则输出为y=B(Ax)。我们可以构造C=BA,则有y=B(Ax)=Cx。那么C就是我们得到的全连接层的参数。
结构重参数化
我们所提出的概念结构重参数化(structural re-parameterization)指的是首先构造一系列结构(一般用于训练),并将其参数等价转换为另一组参数(一般用于推理),从而将这一系列结构等价转换为另一系列结构。
在现实场景中,训练资源一般是相对丰富的,我们更在意推理时的开销和性能,因此我们想要训练时的结构较大,具备好的某种性质(更高的精度或其他有用的性质,如稀疏性),转换得到的推理时结构较小且保留这种性质(相同的精度或其他有用的性质)。
换句话说,“结构重参数化”这个词的本意就是:用一个结构的一组参数转换为另一组参数,并用转换得到的参数来参数化(parameterize)另一个结构。只要参数的转换是等价的,这两个结构的替换就是等价的。
有效性
- 推理时的等价性不代表训练时的等价性。以RepVGG为例,3x3-BN + 1x1-BN + BN最后得到的结构就是一个3x3卷积。也就是说,最终得到那一组参数是OxCx3x3,直接训一个3x3卷积最终得到的也是OxCx3x3。但这两组参数只是形状相同而已,并不代表后者的性能跟前者一样。
- 大就是猛,多就是好,大力出奇迹,越多越work。加一些能在推理阶段去掉的参数,事实证明这样也是有好处的
- 构造的结构提供了模型本身所缺乏的某种性质,为某些花式操作提供了空间。例如,VGG式直筒模型缺乏分支结构和短的路径,我们就构造shortcut,给它加上分支和短的路径,只不过这些结构只在训练时存在而已
- 构造的结构增加了“多样化的链接”和更多的“训练时非线性”。在Diverse Branch Block的实验中,我们报告了一些有意思的发现。按理说1x1卷积的表征能力弱于3x3卷积,因为前者可以看作一个有很多参数为0的3x3卷积,但是1x1 + 3x3的性能却明显好于3x3 + 3x3,也就是说一个强结构加一个弱结构好于两个强结构相加
QA
Q:怎样能把一个训好的ResNet-50重参数化成VGG一样的单路结构?
A:恐怕不可能,这样的转换是不存在的。应该首先确定“我想要模型具有什么性质”,进而“我想要什么样的最终结构”,然后倒推“我需要构造的训练时结构是什么样的”,以及“这样的转换是否可行,如何实现”。所以不存在“怎样把ResNet-50重参数化成VGG”这样的问题,只有“应该把推理时的VGG构造成训练时的什么样子”这样的问题。
Q:所以RepVGG/DBB/ACNet推理的时候是先算出等效的kernel和bias,然后再卷积?
A:并不是。训练完之后,我们只进行一次转换,然后只保存转换后的模型。原模型完全可以扔掉了。
深度学习模型的几个性质
局部先验:卷积操作默认图片中的某个像素与周围的像素联系更加密切,而与距它较远的像素联系更少。所以卷积操作只处理某个局部邻域的信息。这一性质也称为归纳偏置 (inductive bias) 或者局部先验性质 (local prior)。MLP不具备这个能力。
全局信息:卷积网络中,我们会通过不断的卷积或者encoder减小尺寸,扩大感受野来获得全局信息,但是这也势必会导致计算十分低效,且造成优化困难。Transformer被用来解决这个问题,其中的self-attention层专门用来捕获长距离依赖,但是缺少了局部先验性质。同样的,对比卷积来说,他缺乏局部先验,所以可能需要大量的数据来进行预训练。而MLP是天然获取全局信息的,因为其输出与每个输入都有连接。
位置信息:很多图像是有位置先验(positional perception)的(比如说一个人的面部,眼睛肯定是在鼻子上面的),但是卷积操作是无法利用这些位置信息的。而MLP也是天然有位置信息的,因为它的参数是位置相关的,不像卷积操作不同位置的参数是共享的。
方法
作者看上了全连接层具备的全局建模能力和位置先验性质,使用MLP取代卷积操作。再用他拿手的结构重参数技术 (structural reparameterization technique)将卷积操作重参数化为MLP,使得MLP也有了局部先验性质
实验
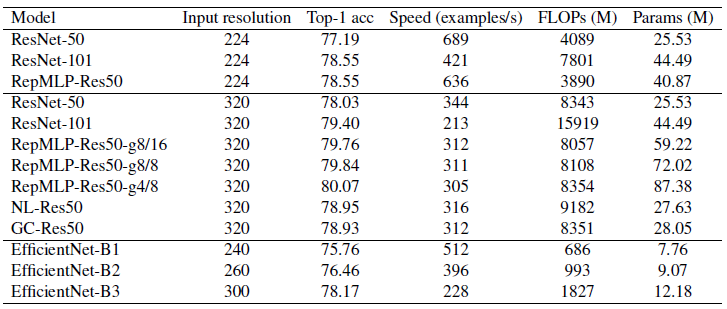
更高输入分辨率下不同模型的性能对比
相比同参数量的传统ConvNet,RepMLP-Res50的计算量更低、推理速度更快。比如,相比224×224输入的ResNet101,RepMLP-Res50仅需50%FLOPs,更少的参数量,推理速度快50%,也可以取得同等精度;当输入分辨率为320×320时,RepMLP-Res50在精度、速度以及FLOPs方面的优势更大。
提升RepMLP的参数量不会导致推理速度的大幅下降。比如,从RepMLP-Res50-g8/16到RepMLP-Res50-g4/8,参数量提升47%,但FLOPs仅提升3.6%,推理速度仅从311下降到305。这对于高吞吐量的大型服务器推理是非常有用的。
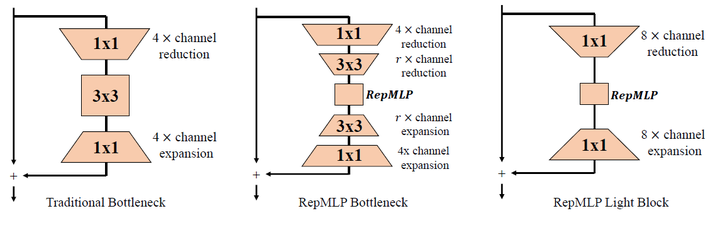
更轻量化的高速版本RepMLP

更轻量化的高速版本RepMLP性能
轻量版RepMLP取得了与原始ResNet50相当的性能(77.14 vs 77.19),但FLOPs降低30%,推理速度快55%,达到1074 examples per second。
总结
RepMLP借助结构重参数技术,将MLP与卷积巧妙结合,不仅保留了MLP的全局建模能力和位置先验性质,还能融入卷积的局部先验性质。在ImageNet分类、人脸识别以及语义分割等任务(无论是否具有平移不变性)上均能涨点。作为模型压缩的方法,它可以在GPU端实现模型推理速度的提升。
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
pre
ref: https://zhuanlan.zhihu.com/p/481445076
ref: https://zhuanlan.zhihu.com/p/480935774
paper: https://arxiv.org/abs/2203.06717
code: https://github.com/DingXiaoH/RepLKNet-pytorch
31x31大卷积核、结构重参数化
挑战习惯认知
- 超大卷积不但不涨点,而且还掉点?超大卷积在过去没人用,不代表其现在不能用。人类对科学的认知总是螺旋上升的,在现代CNN设计(shortcut,重参数化等)的加持下,kernel size越大越涨点!
- 超大卷积效率很差?我们发现,超大depth-wise卷积并不会增加多少FLOPs。如果再加点底层优化,速度会更快,31x31的计算密度最高可达3x3的70倍!
- 大卷积只能用在大feature map上?我们发现,在7x7的feature map上用13x13卷积都能涨点。
- ImageNet点数说明一切?我们发现,下游(目标检测、语义分割等)任务的性能可能跟ImageNet关系不大。
- 超深CNN(如ResNet-152)堆叠大量3x3,所以感受野很大?我们发现,深层小kernel模型有效感受野其实很小。反而少量超大卷积核的有效感受野非常大。
- Transformers(ViT、Swin等)在下游任务上性能强悍,是因为self-attention(Query-Key-Value的设计形式)本质更强?我们用超大卷积核验证,发现kernel size可能才是下游涨点的关键。
现代CNN中应用超大卷积核的五条准则
- 用depth-wise超大卷积,最好再加底层优化(已集成进开源框架MegEngine)
- 加shortcut
- 用小卷积核做重参数化(即结构重参数化方法论,见RepVGG)
- 要看下游任务的性能,不能只看ImageNet点数高低
- 小feature map上也可以用大卷积,常规分辨率就能训大kernel模型
基于以上准则,简单借鉴Swin Transformer的宏观架构,提出一种架构RepLKNet,其中大量使用超大卷积,如27x27、31x31等。这一架构的其他部分非常简单,都是1x1卷积、Batch Norm等喜闻乐见的简单结构,不用任何attention。
基于超大卷积核,对有效感受野、shape bias(模型做决定的时候到底是看物体的形状还是看局部的纹理?)、Transformers之所以性能强悍的原因等话题的讨论和分析。我们发现,ResNet-152等传统深层小kernel模型的有效感受野其实不大,大kernel模型不但有效感受野更大而且更像人类(shape bias高),Transformer可能关键在于大kernel而不在于self-attention的具体形式。例如,下图分别表示ResNet-101、ResNet-152、全为13x13的RepLKNet、kernel大到31x31的RepLKNet的有效感受野,可见较浅的大kernel模型的有效感受野非常大。

为什么要超大kernel size
- 为大kernel正名。在历史上,AlexNet曾经用过11x11卷积,但在VGG出现后,大kernel逐渐被淘汰了。原因包括大kernel的效率差(卷积的参数量和计算量与kernel size的平方成正比)、加大kernel size反而精度变差等。但现代技术下作者认为可以把大kernel size做好。
- 克服传统的深层小kernel的CNN的固有缺陷。曾经大家认为大kernel可以用若干小kernel来替换,比如一个7x7可以换成三个3x3,这样速度更快(3x3x3< 1x7x7),效果更好(更深,非线性更多)。而深层小kernel的堆叠导致的优化问题由ResNet解决,但实际上它只是回避了“深层模型难以优化”的问题,而并没有真正解决它(ResNet实际感受野并不大)
- 理解Transformer之所以work的原因。Transformer的基本组件是self-attention,而self-attention的实质是在全局尺度或较大的窗口内进行Query-Key-Value运算。作者猜测会不会“全局尺度或较大的窗口”才是关键?对应到CNN中,这就需要用超大卷积核来验证。
注:第三点正好对应《Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet》提出了Transformer中的attention是不必要的,仅仅使用Feed forward就可以在ImageNet上实现非常高的结果。
Shape bias:大kernel模型更像人类
又研究了模型的shape bias(即模型有多少比例的预测是基于形状而非纹理做出的),人类的shape bias在90%左右
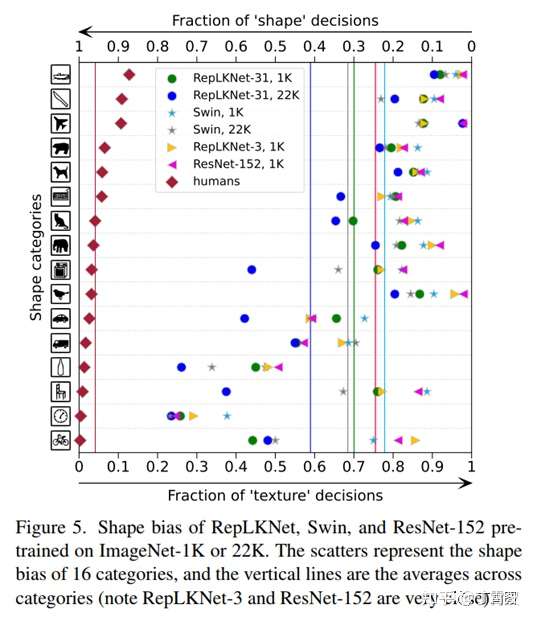
关于shape bias的一项工作提到ViT(全局attention)的shapebias很高,而我们发现Swin(窗口内局部attention)的shape bias其实不高(下图),这似乎说明attention的形式不是关键,作用的范围才是关键,这也解释了RepLKNet-31的高shape bias(即更像人类)。
附录
FLOPS:注意全大写,是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs:注意s小写,是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
Depthwise(DW)卷积:与Pointwise(PW)卷积,合起来被称作Depthwise Separable Convolution(参见Google的Xception),该结构和常规卷积操作类似,可用来提取特征,但相比于常规卷积操作,其参数量和运算成本较低。
Depthwise卷积与Pointwise卷积
ref:https://zhuanlan.zhihu.com/p/80041030
ref:https://zhuanlan.zhihu.com/p/339835983
常规卷积
对于一张5×5像素、三通道彩色输入图片(shape为5×5×3)。经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4),最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3。
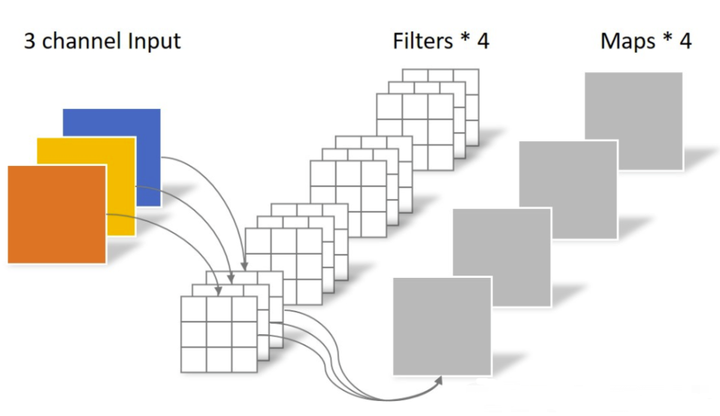
此时,卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:
N_std = 4 × 3 × 3 × 3 = 108
Depthwise Separable Convolution
将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
Depthwise Convolution
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。
同样是对于一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,不同于上面的常规卷积,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
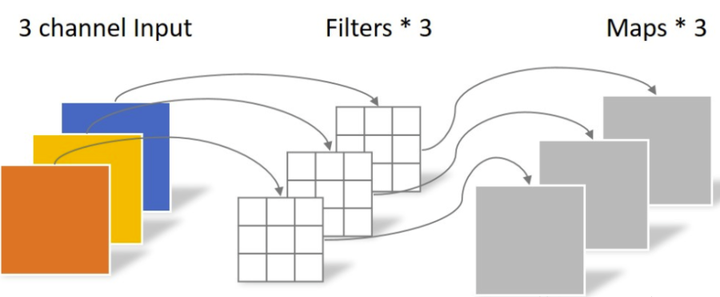
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
N_depthwise = 3 × 3 × 3 = 27
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
Pointwise Convolution
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示。
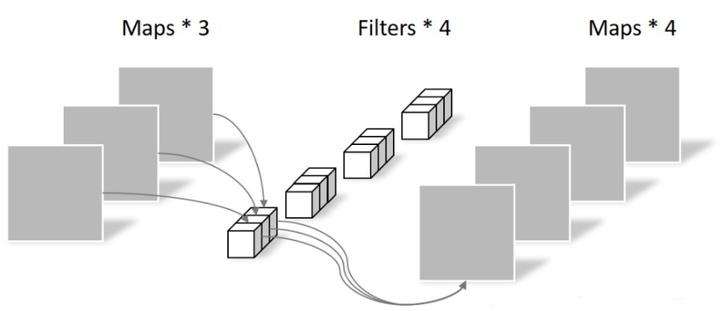
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同。
参数对比
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
本文作者:心有所向,日复一日,必有精进
本文链接:https://www.cnblogs.com/Stareven233/p/16704617.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步