[论文阅读] Few-Shot Font Generation by Learning Fine-Grained Local Styles
pre
ref: https://zhuanlan.zhihu.com/p/542389717
paper: https://arxiv.org/abs/2205.09965
code: https://github.com/tlc121/FsFont
阅读论文 《Few-Shot Font Generation by Learning Fine-Grained Local Styles》 https://openaccess.thecvf.com/content/CVPR2022/papers/Tang_Few-Shot_Font_Generation_by_Learning_Fine-Grained_Local_Styles_CVPR_2022_paper.pdf
intro
字体生成任务通常讨论的是字符容量较多、字符结构精细度高的语言(汉语、韩语 etc.)。英文等语言由于字符种类非常少,而且字符的结构很简单,自主设计的压力不大,通常不需要字体生成模型来解决。字体生成这个任务发展到现在,工作通常都是FFG。
FFG: few-shot font generation
FLS: fine-grained local styles
SAM: style aggregation module
最后提到一种为每个字形自动选取最合适的参考字的策略,基于宽度优先搜索,这个很重要,因为模型训练依赖content-reference mapping,而这个json文件目前并没有完整公开。
总结论文的贡献为:
- 新奇的模型,抽取参考字形图片的FLS,和一个基于跨注意力的SAM,将参考风格汇聚为目标风格图。因此参考字形的细节就被转移到了目标字形
- 提出带有新设计的重建分支的统一训练框架。该分支极大增强了模型的细节捕捉能力,并且改进了输出图片的质量。
- 分析字符之间的关系,并且选取一个相当小的字符集作为参考。然后设计一种规则将每个字符映射到参考集中的元素,提出的这个规则更好地发挥了模型抽取部件特征的能力。
难点
虽然人脸的视觉差异很大,但其实人脸图像的结构特征相对比较单一(五官等位置结构信息相对比较固定)而且出了某些细小的错误通常不明显。
汉字不同instance的结构差异可能非常大,一些微小的错误会对整个字形效果产生显著的削弱。这对模型的特征学习能力提出了相当高的要求。主要难点是两个:字形重构(不能有错误、模糊等缺陷)、风格融合(完美复刻出reference字的风格)
许多传统的衡量生成图像质量的指标在font generation这里可能并不具备说服力,更多的情景下,需要依赖user study
文献综述
字体生成的工作其实并不多,因为这个方向实在是太小了。这个任务从开始借鉴通用图像生成框架,到后来逐步加入本任务特有元素,其实并没有发展太久。可以关注一下北京大学的连宙辉教授,以及Clova AI Research,他们提出了很多字体生成的模型。
基于通用image generation框架
字体生成任务说到底仍然是一个图像生成任务,因此,一个思路是将某些经典的图像生成框架直接套到字体生成任务上,这些模型通常是encoder-decoder架构。说白了就是将数据集直接换成字体数据集。
以zi2zi为例,它是从pixel2pixel改进得到的,网络架构是经典的UNet结构,输入是一个标准汉字(黑体或者宋体),输出则是具有风格的相同内容汉字。其中,字的风格采用one-hot向量编码。但是,要使单路的encoder-decoder结构具备重构字形的能力,并不简单,通常需要reference字对输出字进行强约束,但收集一一对应的数据集很难。
于是,更多的工作开始融入更多的图像生成框架,以提升模型理解字形特征和风格特征的能力。除了使用Auto Encoder、CycleGAN等重建风格字来获得较好的特征,其他的图像生成模型如FUNIT等也可以应用到字体生成中。
FUNIT: Content&Class融合的Few-shot Unsupervised风格迁移模型: FUNIT
FUNIT是一个few-shot学习模型,且不需要paired data,可以将若干个风格字同时提取特征,并整合成一个general的特征表示,再融入到主干生成网络中。它也是一个字形特征+风格特征融合的典型案例,后续很多专门针对字体生成提出的模型也几乎延续了这种模型架构,即使用一个网络提取标准字的字形特征,再用一个网络提取风格字的风格特征,随后特征融合,再重构出具有相同字形但已经变了风格的汉字。
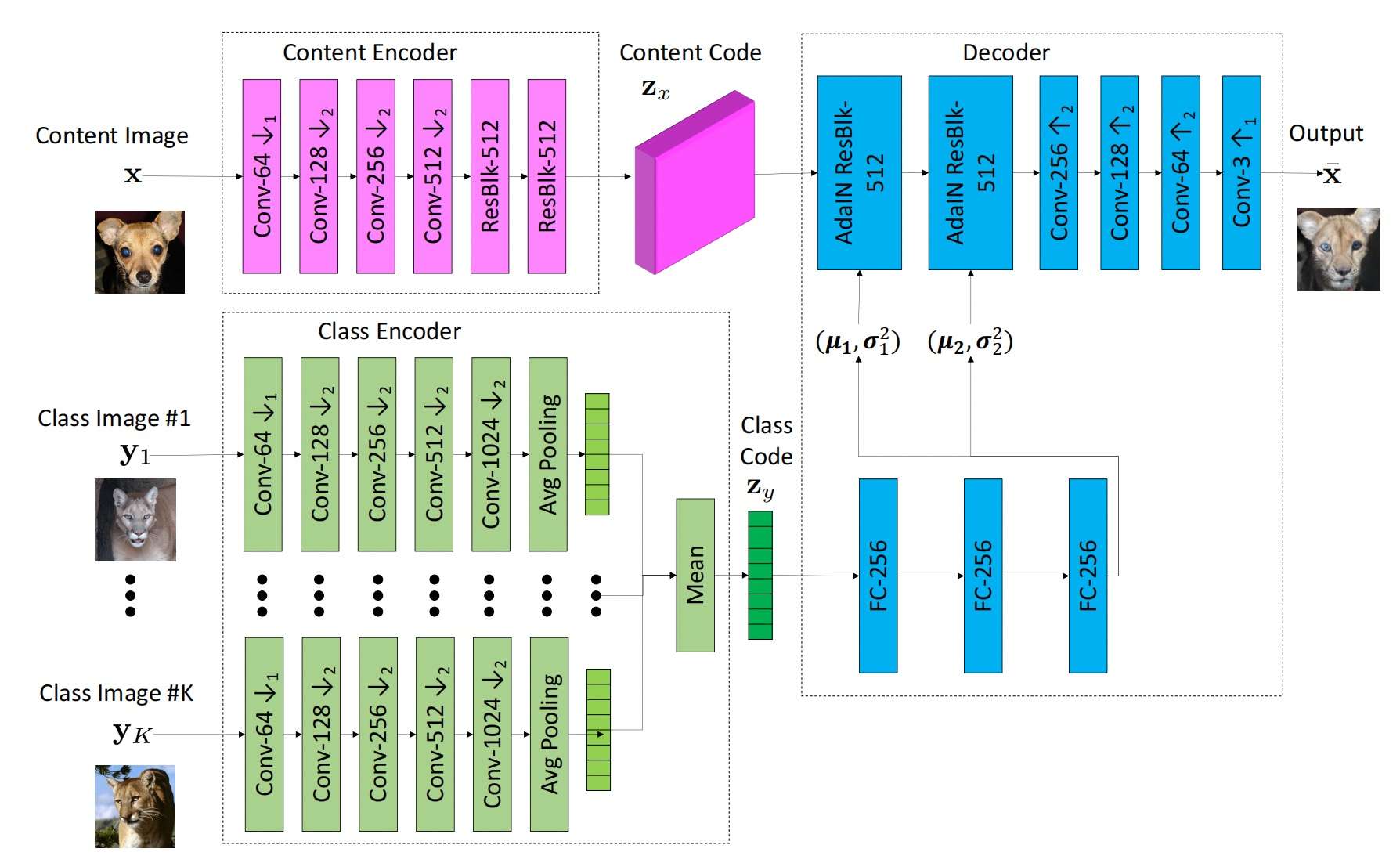
使用FUNIT做字体生成,会有一些成果,但是距离生成令人满意的风格字还有很大的距离,这是因为字体图形特征太复杂,需要专门设计分析它们结构特征的模型
针对字体生成任务的特定工作
SC-Font
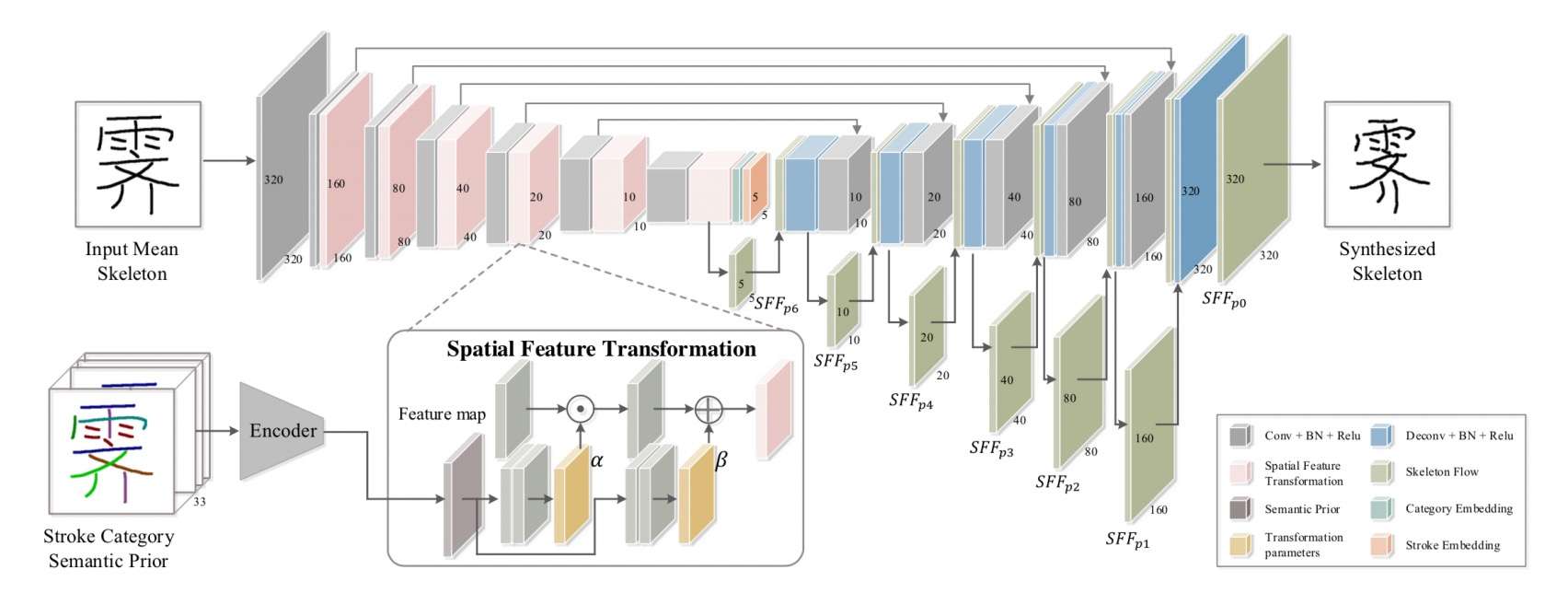
SC-Font使用了笔画层面的语义信息作为附加信息,逐级融入到主干UNet结构中,约束生成图像的笔画稳定性。但是,对普通的数据而言,想要取得笔画级别的label难度也很大,不利于商业化的应用。
AGIS-Net
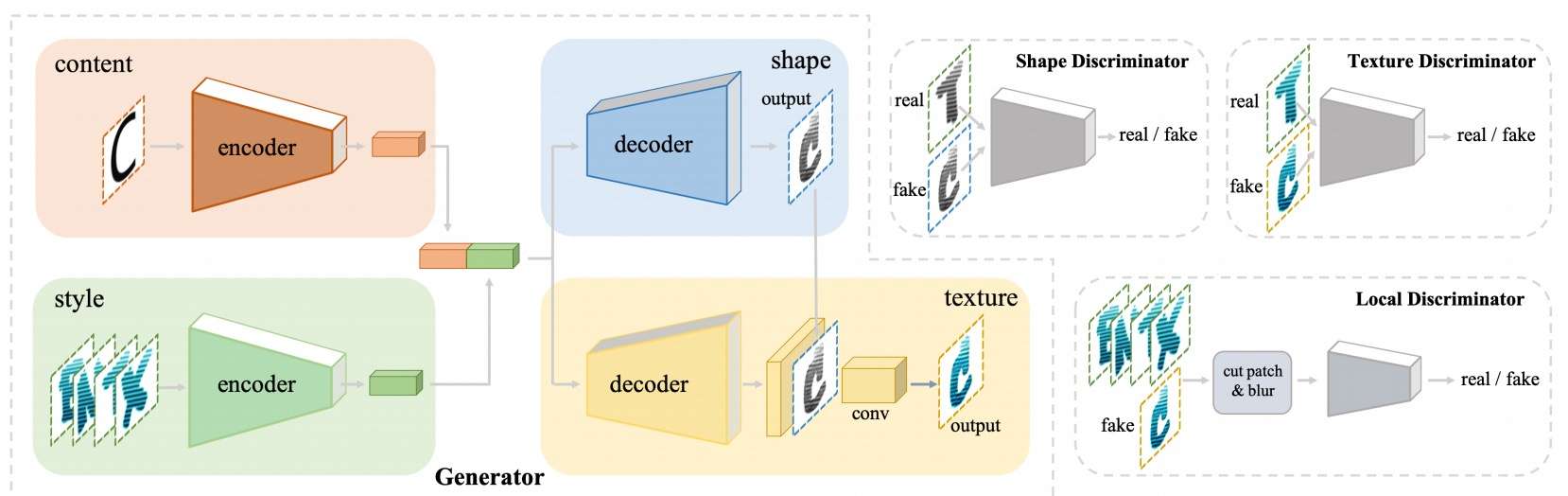
字体的特征通常可以划分为字形特征(字的轨迹)和风格特征(笔锋等)。AGIS-Net在网络中设计了不同的模块,分别约束生成字体的字形和风格。它和FUNIT的网络架构很相似,但从一个融合后的特征引出了两个不同的解码器:一个专门负责生成字形,一个负责在生成字形的基础上再“渲染”出更细节的风格。同时,字形的中间结果和最终结果都会有discriminator来约束。
ZiGAN
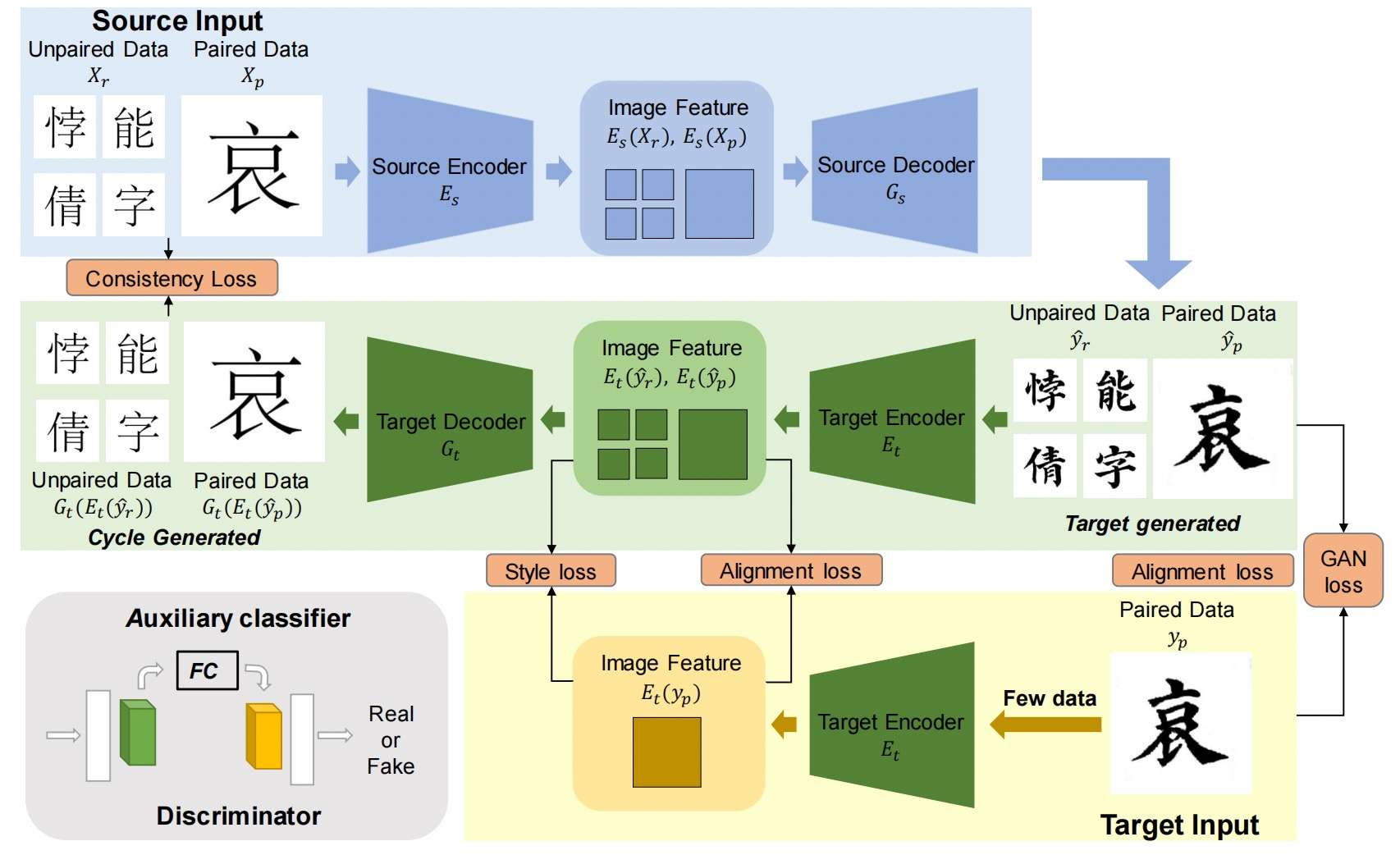
ZiGAN针对原来的zi2zi模型,提出了如下的改进:首先,它引入了类似于CycleGAN的模式,加入了一个额外的encoder-decoder(淡绿色部分),将生成的风格字又映射回原来的标准字。这项约束有效的提高了生成字的字形质量,因为如果生成的字形有缺陷,它很难映射回标准字的正确字形。其次,它的discriminator引入了class activation map (CAM)来使提升模型对局部信息的关注。
论文《Learning Deep Features for Discriminative Localization 》(2016CVPR)结合扫了两个概念:
Global Average Pooling Layer (全局平均池化层)
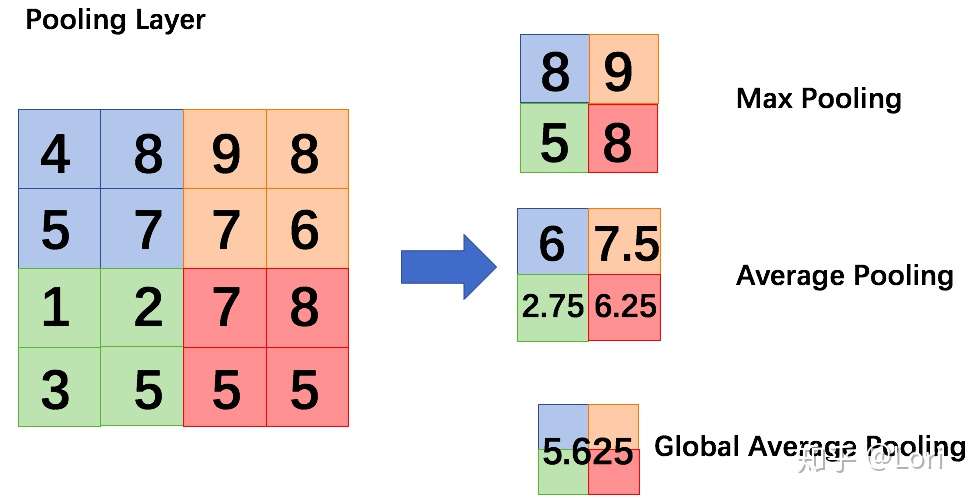
与平均池化类似,Global Average Pooling(全局平均池化)是指计算整个区域的平均值,仅用一个值来表示整个区域。通过下面这个图,我想我们可以更直观的理解GAP。
第一个提出GAP这个想法的,是一篇叫做《Network in Network》的论文。这篇论文发现用GAP代替全连接层,不仅可以降低维度,防止过拟合,减少大量参数,网络的性能也很不错。
如果我们使用GAP来代替FC,优点是最小化参数数量的同时保持高性能,结构变得简单,也避免了过拟合。但是缺点是和FC相比,GAP收敛速度较慢。
Class Activation Mapping (类激活映射)

CAM是一个帮助我们可视化CNN的工具。使用CAM,我们可以清楚的观察到,网络关注图片的哪块区域。比如,我们的网络识别出这两幅图片,一个是在刷牙,一个是在砍树。通过CAM这个工具,我们可以清楚的看到网络关注图片的哪一部分,根据哪一部分得到的这个结果。
这项技术非常有用但是存在一些缺陷的。首先我们必须改变网络结构,例如把全连接层改成全局平均池化层,这不利于训练。第二是这是基于分类问题的一种可视化技术,用于回归问题可能就没有这么好的效果。
为了解决第一个问题,2017年出现了一种改进的技术叫Grad-CAM,Grad-CAM可以不改变网络结构进行可视化,详见这篇论文《Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization》 (2017 ICCV)。
DM-Font
DM-Font在字体生成中引入了一个非常重要的概念,就是“部件复用”。部件(component),是汉文、韩文等亚洲国家文字常用的一种汉字成分表示(这里的部件涵盖了通常意义的部首)。
如果一套referfence涵盖了所有的部件,是否就可以合成出所有的汉字?从这一点出发,我们便可以大大缩小提供风格字的样本容量(常用韩文的部件在50个左右,汉字部件则是300个左右)。
一个结论是,字体生成任务中,我们应该更加关注字的局部特征,我们的模型输入是一个字,encoder输出的特征应该是涵盖不同部件的特征,从而能更好的指导decoder生成相似部件的其他字。
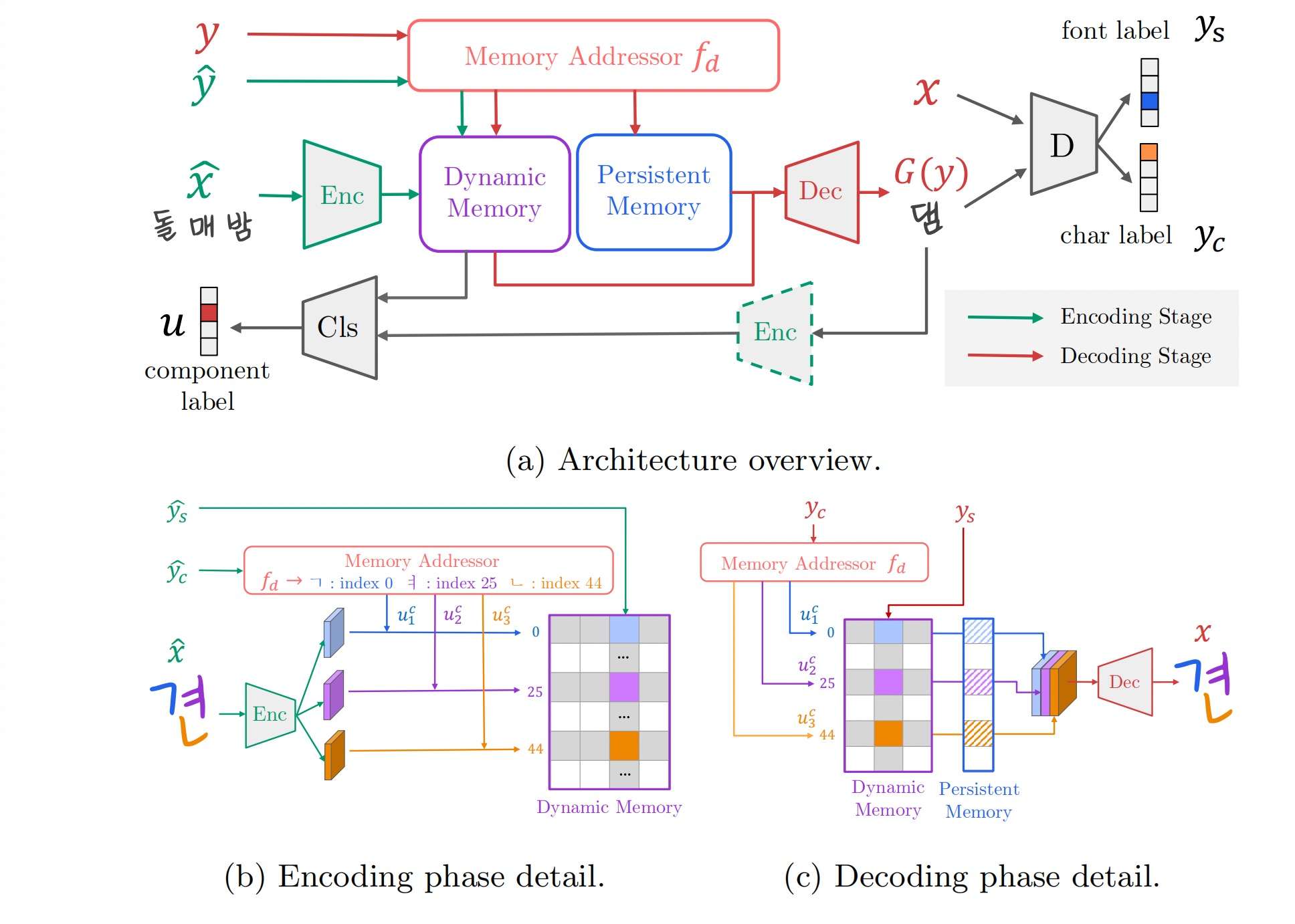
DM-Font的一个重要贡献便是模型加入了部件分析模块,可以将它想象成一个embedding层,不断读入不同部件的特征,每一个部件对应这个这个矩阵的一个位置。在解码时,解码器有根据要生成的字含有哪些部件,从这个矩阵中读取出对应部件的特征,并融合到decoder的feature map中。
同时,这个“存储器”的内容随着不同字的相同部件被读入,会不断地更新,使得模型掌握对这个部件可以学习到更加丰富的信息(例如,同一个部首“木”,它在左右结构和上下结构中的风格可能会不同,因此模型需要兼顾这些不同的情况)。DM-Font因为有两个不同的“存储器”模块,一个是动态变化的,一个则是比较稳定的,所以又称为Dual Memory(DM)。
RD-GAN
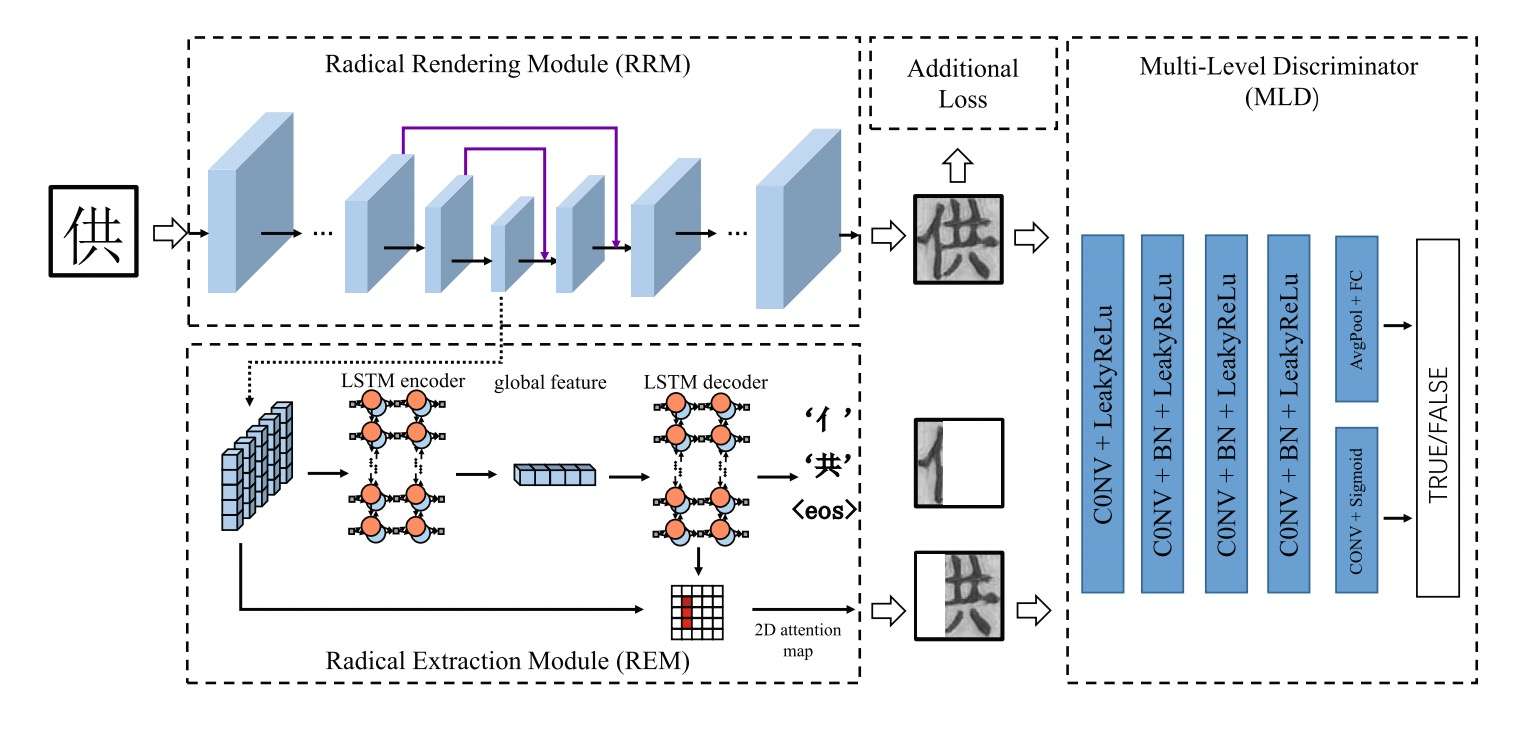
RD-GAN是另外一个关注如何提取字体局部特征的工作。它使用了LSTM以及Attention机制处理encoder得到的feature map,能够有效的划分出字体的不同部件。但这个思想似乎只能用于横向结构且部件比较容易划分的情况,如果遇到了更加复杂的结构,恐怕LSTM会很难提取它们的特征。
DG-Font
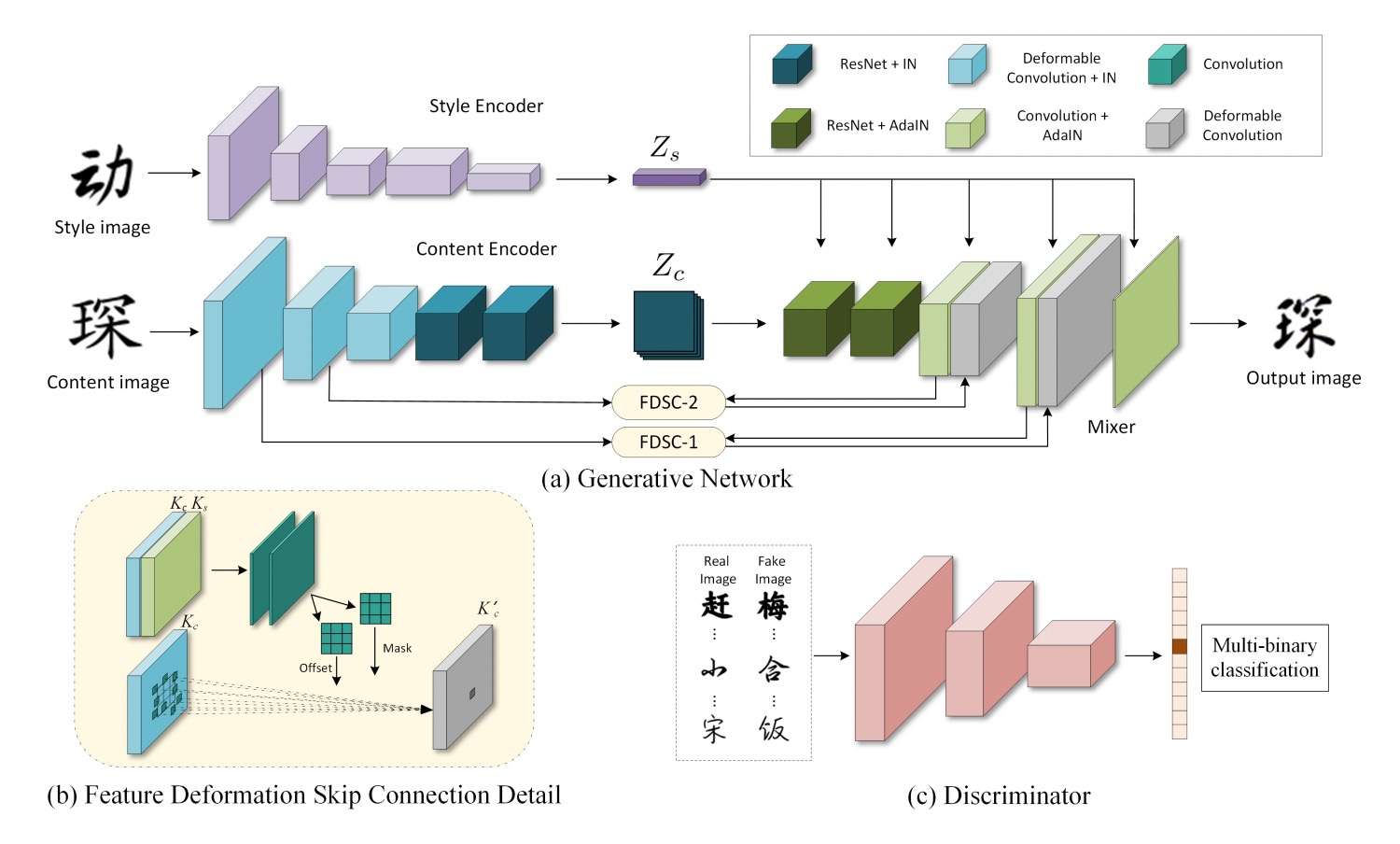
很多情况下,具有风格的字可以通过标准字做一些变换得到。DG-Font第一次使用了可变形卷积处理字的特征,使得它能够学习笔画的偏移和形变。它设计了一个基于可变形卷积的模块来对齐标准字和生成的风格字的浅层特征,取得了不错的效果。
LF-Font
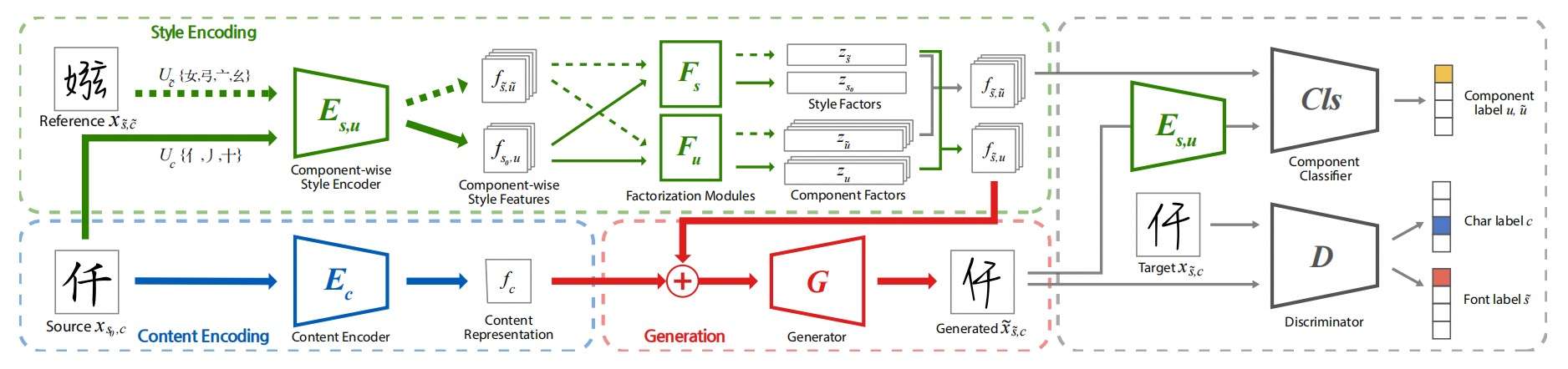
LF-Font和DM-Font出自同一个团队,前者可以说是对后者的一个改进。两者思想其实相差不大,但是前者在风格encoder的输出端加入了一个Factorization(图上半部分绿框\(F_s,\; F_u\)),试图将不同部件的结构特征和其他的风格特征分开。
MX-Font

LF-Font的续作。它不再针对不同的部件提取对应的特征,它提出无论一个字有多少个部件,都让一个固定数量的模块处理。例如,LF-Font的factorization会根据有多少个部件,会生成相同数量的特征。而MX-Font始终会生成同样数量的feature map,其实有点ensemble那种感觉了。其次,MX-Font在跨语言的任务上取得了不错的效果。
小总结
然而先前的FFG工作不能完整地从k个参考中提取风格图,对于k个参考图片,他们倾向于明确地解耦图片的风格和内容,在全局上或者部件级别上,并且对抽取的特征做均值操作,这会极大削弱每个参考字的局部细节。因此这里设计了SAM去保持参考字形中非常细节的特征,同时也为了充分利用空间细节。
Method
字体生成的任务需要注重局部特征的分析,从而实现部件级别的复用。而汉字的部件特征通常伴随着空间特征。本文使用了基于transformer的cross attention机制,使得模型能够更加容易的匹配内容字和风格字的空间特征,风格字的风格能够完美地迁移到标准字的对应位置。这个思想可以用下图表示:
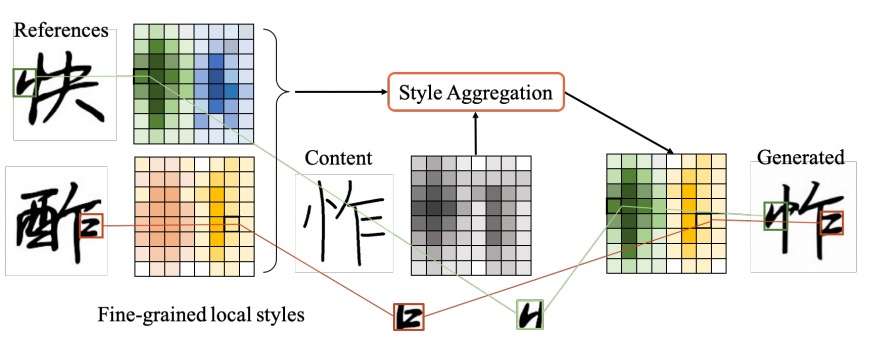
注意到参考字的绿色和黄色部分构成了生成字
style Aggregation Module(SAM)
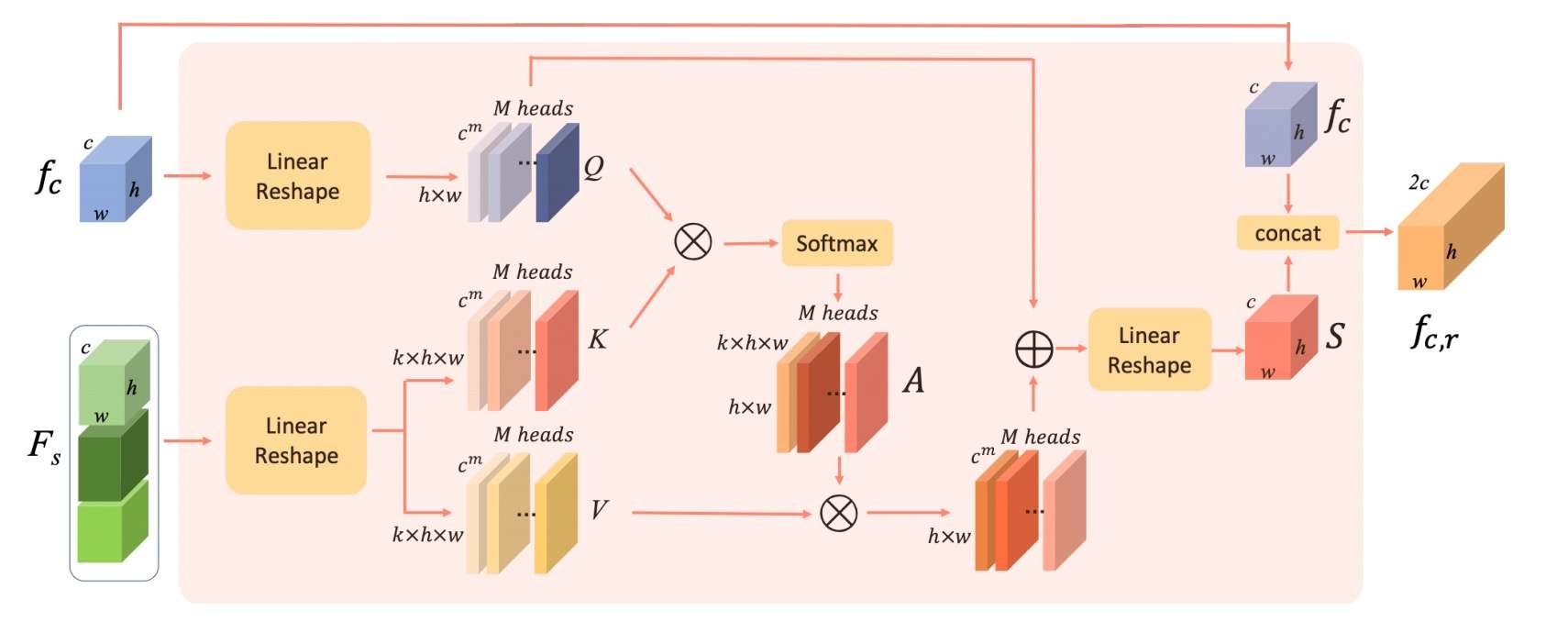
Style Aggregation Module即是Attention机制。\(F_s, F_c\)分别是内容字和风格字提取出的feature map(风格字通常是3~4个,提供了内容字不同的部件),我们通过线性变换将它们转换成注意力机制的Q、K、V三个矩阵。
Q和K进行乘积计算的过程,就是进行空间特征匹配的过程,得到的attention map处理V,就是在风格特征中选择能够匹配上的特征的过程。
其他还有一些trick,例如将内容字的特征skip concat到attention机制的输出部分,可以减缓计算过程中结构信息的削弱。
Self Reconstruction
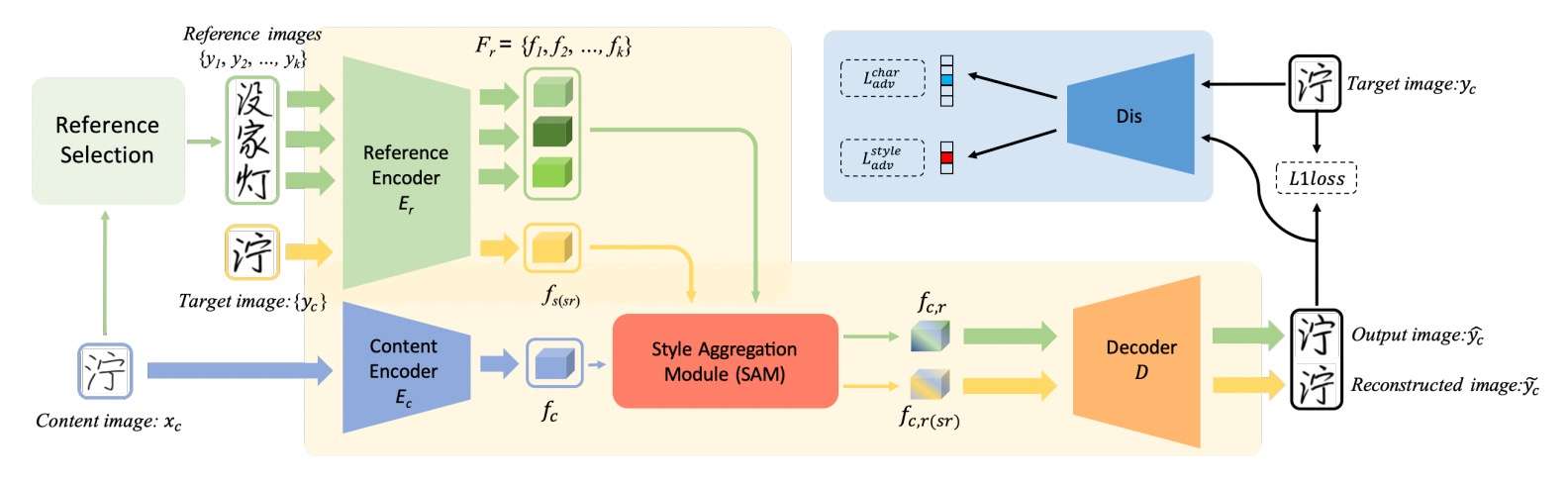
图中黄色流程表示Self-Reconstruction,用目标字风格与源字内容重建目标字(内容和风格是同一个字),绿色是多个参考字(与内容字不同但部分部件类似)提取风格跟源字的内容生成目标字。
Reference Selection
在一些考虑部件分解的之前的工作中,像LF-Font,包含跟内容字一致部件的参考字每个iteration都从训练集中随机抽取。模型很难从不断变化的参考字集学习如何提取部件级的特征。因此这里使用一种策略来选取固定的的参考字集,其部件覆盖大多数常用字,并设计一个内容-参考映射,使得每个字符都有固定的参考字组合。
为了建立这种映射,首先将每个字符分解为一棵部件树,如图4所示,基于一个常用的分解表,定义级别0, 1, 2的部件为高级部件(conspicuous-level),其包含较易从参考到目标转换的单独和复合部件(radical and compositional structures)

[注]:据表可知,上面的conspicuous-level意为分解较不彻底,如 '潮': '氵朝𠦝月',而把 '𠦝' 拿去继续拆分就构成低级部件(inconspicuous components)
参考字集选取。参考字集应覆盖尽量多的高级部件。首先选取一个小的子集(通常包括100个字符)。首先将这些字符分解为一棵棵的部件树,并将那些包含两个及以上新部件的字符加入参考字集中。当参考字集中的元素达到限制(When the elements in the reference set reach their limits),应该是说参考字达到固定数量就结束,就得到了风格参考字集和它相应的所包含的部件。
内容-参考映射。选取完参考字集,就在内容字形跟风格参考之间建立映射关系。提出一种贪心程序来找出一个字形的k个参考。在这程序中,将搜索k次参考字集来建立一个映射关系。每次搜索,就找跟目标字形有最多公共部件的参考字形。如果有多种选取方式,就选有最多部件并且具有相同结构组成的。每次选完就将其从参考字集中移除,然后继续下一个参考字的选取。通过这种方式就能为每个字形选出相应k个参考字。
Experiments
Datasets and evaluation metrics
数据集 选取407种字体以及3396个常用汉字构成数据集,包括手写字体、印刷字体以及艺术字体。所有图像都是128x128像素。从数据集中选了100个字作为参考字集,用上面介绍的策略创建了个内容-参考映射。参考字集跟内容-参考映射在训练和测试集中都是固定的,意味着只需要100个字就能创建一个新的字库(font library)。训练集有397个字体以及2896个字符。测试集包含10种有代表性的字体,如打字机字体、艺术字体跟手写字体,用以评估模型对多样的未知字体的泛化性。
评估指标 涉及到L1、RMSE、SSIM和LPIPS指标,此外还引入用户调查去计算字符准确度,因为基于CNN的分类器会容忍小缺陷,比如一个笔画丰富的字中的笔画缺失和边模糊。雇了51个志愿者...(主要都是用户调查的细节,省略)
Comparison methods
将本文的模型与 FUNIT, DG-Font, MX-Font, AGIS-net, LF-Font 作对比,这些前文都有介绍。最后提到选取了 Kaiti Line Font 作为标准字体,并且在训练集上重新训练了所有模型。
Experimental results
UFUC: Unseen Fonts Unseen Characters
UFSC: Unseen Fonts Seen Characters
定量对比 表1展示了FsFont在像素级到感知级上都超越了先前的SOTA模型,在UFSC方面略逊于MX-Font和AGIS-Net,但对于UFUC能生成更好的结果。同时最后一列那个Style Consistency,FsFont远好于其他模型,数字十分离谱,说明FsFont能产生跟用户观点相近的(好)结果。

表1 在UFUC 和 UFSC上的质量对比
定性对比 图5展示了各个模型生成的样本,选取了4种不同的字体,包括打字机字体、艺术字体、和手写字体来验证各个模型的泛化性。如图所示,FsFont能恢复参考图形的许多细节,其他的像LF-Font和AGIS-Net不能像FsFont产生这么精细的样本。
但感觉也只是相对而言好一些,没有xmp-font那么惊艳细致。

图5 各方法在 UFUC 数据集上生成的结果
消融研究 表2展示了UFUC数据集上面进行的总体评估。将SAM换成平均化\(F_r\)来测试它的有效性。而Reference Selection 和 Content-Reference mapping 则是把它们换成LF-Font的策略,对于每个内容字符都随机选取具有共同部件集的参考字形图片。而 Self-Reconstruction Branch 对输出具有非常重大的影响,如表3所示,不具备SR分支的模型训练后几乎不能重建参考字形图的细节。

表2 独立测试了Style Aggregation Module (SAM), Self Construction (SR) 和 Reference Selection (RS)三部分。

表3 绿框是希望模型重建的部件,红框展示的是不足的细节
可视化SAM 在图6中可视化了不同级别的注意力图来验证SAM的有效性。特别是给定一个内容特征图中确定的空间点q作为query,可以得到空间对应矩阵\(A^m\)相应的相关矩阵\(A^m_q\),并通过reshape \(A^m_q\) 为\(h\times kw\)来构建注意力图。分别考虑来自 Granular, Stroke 和 Component 级别的查询,并且通过将与queries相关的注意力图相加计算最终注意力图。
图中展示了SAM模块使得模型关注来自参考图形的正确FLSs并抽取内容图形的子部件级特征表达。
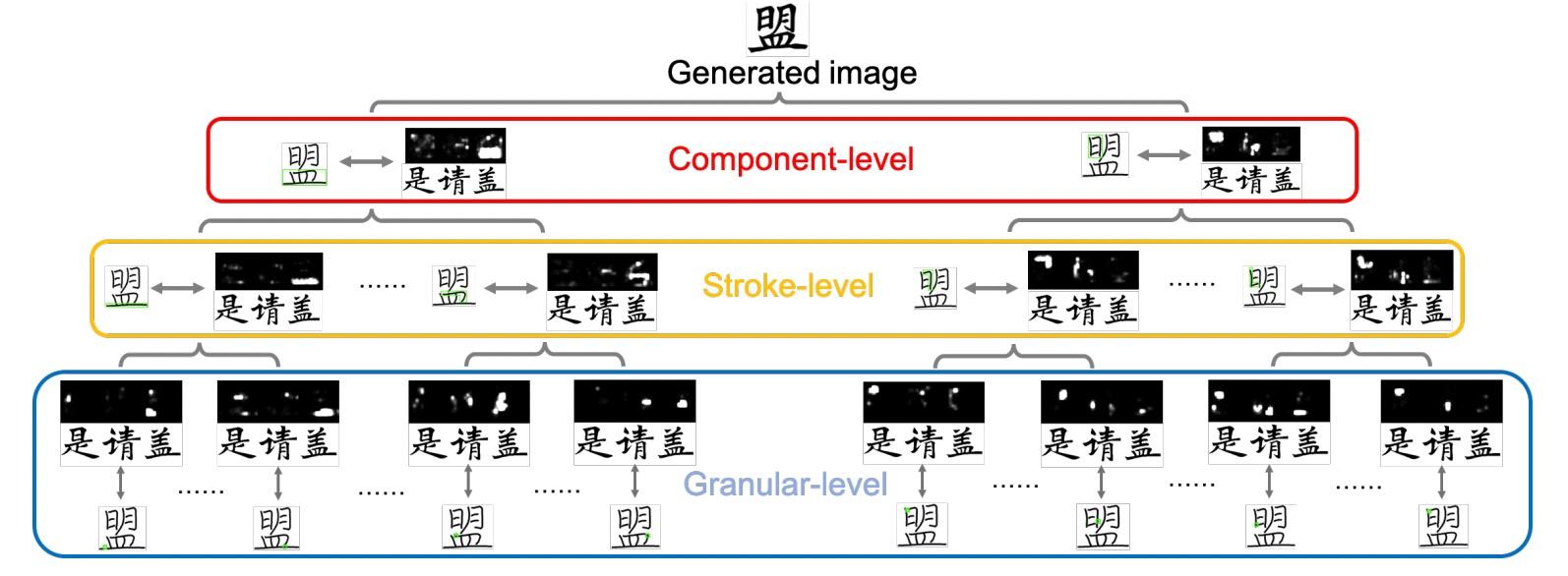
图6 SAM的可视化,attention maps 中的更亮的点表示参考特征图中相应特征具有更大的贡献。
如图从不同部件细粒度级别,查看Attention机制的feature map。用“是、请、盖”三个字生成“盟“字的时候,它们的公共部件”日、皿、月“在Attention机制中响应较大,验证了特征匹配的有效性。
此外作者还做了很多实验,包括但不限于生成训练集中没有的字(unseen glyph)、生成新的风格(unseen font),跨语言,效果都比他们之前的工作更优秀,可以参考其论文。
对比之前的工作,作者引入了user study。评价过程是,由用户自己提供若干个字作为reference,基于这些数据,用这个模型和之前工作的模型生成出该用户的所有字,随后,在用户端隐去模型信息,并且打乱顺序,让用户选择最符合他们书写风格的模型结果。结果表明,该模型的结果选中次数明显高于其他的模型。这也说明该模型在复用用户部件上的效果是很有效的。
总结
回顾字体生成这个任务,它的模型由借鉴各种image generation框架,最终逐渐确立内容字和风格字特征融合的框架(两个encoder,一个feature融合模块,一个decoder);encoder从提取字的总体特征,逐渐转向细粒度高的部件特征提取。随着近年来Transformer结构在CV领域的应用越来越多,Attention机制成为了分析字体部件特征的有效工具。随着多媒体技术的发展,字体生成无疑也能够在个人数据定制等领域发挥自己的作用。
SAM汇聚参考字细粒度的局部风格高保真地给内容相应的局部。局限是这个模型只在有限的数据上训练,不能忠实的复现字体的每个细节。虽然FsFont有望用于模拟手写字,但人类专家仍然能注意到生成的跟真实之间的差别。
核心思想应该是根据目标字形c挑选合适的、含有所需组件的参考字作为风格参考s,然后借助跨注意力从多个s中抽取所需的风格,跟c编码出的内容特征一起去生成字形g。本质上也是风格、内容的解耦,但通过注意力从多个s去选择所需组件,有点DM-Font的味道。这也是比较合理的,反倒是one-shot的方案理论上就不可靠,毕竟对于人来说都很难做到。
但实际上该方案似乎仍有不足,附录中的样本细看还是很明显,且不说连笔,大小、布局、倾斜度都有所欠缺,毕竟有些组件在每个字里面的位置、大小都未必相同,当参考字跟目标字结构不同时会有明显差距。但总体来说效果算是比较好的,论文内容也很详尽,且代码开源。
22/9/27: 花了3周想要复现,一点点自己构造cr_mapping、lmdb,跟paddlepaddle斗智斗勇,代码难懂,框架报错不清晰。数据集构造繁琐,paddle后期想改进恐怕不容易,而且100个参考字说是few-shot有点勉强吧,最终没坚持下去。
附录
A.1 Reference Selection
Reference set determination 目标是找一个参考字集覆盖大多数高级部件,详细算法见算法1。
其中\(X\)表示按照字符出现频率排序的完整字符列表,大约20k个。
\(T\)表示X中所有字符的单层分解查询表(Single-level decomposition look-up table)。对于T中的键\(x_i\),相应的值\(\chi_i\)是X的子集,由其分解部件的name列表和相应的分解形式构成。通过浏览该部件列表,可利用宽度优先搜索来递归地获得不同级别的所有部件,它们形成了本工作中的部件树。猜测每个键值对形如"愫: [累, 快, 请]"
\(C\)表示所有高级部件的集合,总大小为374.
\(N_{ref}\)表示目标参考集的总大小,本实验中固定为100
[注]:这里100个参考字无法涵盖所有组件,因此训练集选的是这100字能cover的3396个常用汉字
初始时,设目标参考集\(\hat{U}\)和相应覆盖部件集\(\hat{C}\)为\(\emptyset\),然后开始在X中进行搜索,对X中的每个字形\(x_i\),通过算法1里的函数 searchComponents 取得它的高级部件\(c_i\)。如果\(c_i\)里存在\(\hat{C}\)还没有的独特部件,就把\(x_i\)作为目标参考字形,然后把它和它的独特部件分别加入\(\hat{U}\)和\(\hat{C}\)
本实验中,只有参考字含两个以上的独特部件才加入参考字集,一旦\(\hat{U}\)达到\(N_{ref}\)就停止搜索

Content-reference mapping k-shot参考映射(一个字有k个参考),按如下过程搜索k次: 在参考字集里找一个字形,跟内容字有最多公共部件,然后把它从原始参考字集中去掉。如果有多个选择,就选跟内容字形结构一样的(上下、左右、全包围等结构?)
图8展示了一些内容和参考的映射
A.3. Training details
使用Adam优化器,生成器和判别器学习率分别为 0.0002 和 0.0008。模型使用kaiming初始化。训练时采用3-shot参考字,若不足,则重复直到参考字有3个,这是为了能够batch训练。在SAM中,设置注意力头数量为8,batch size为32。带着所有目标函数一共训练了500k个iteration。
B. Additional Experimental Results
在未知字体上更多的实验结果,用到的内容字,更多的注意力图可视化。
C. User Study Examples
展示了用于用户研究(User Study)的样本

图8 更多结果。展示了Content-Reference mapping跟所有测试字体上的生成结果。

图9 实验中使用的内容字体

图10 注意力图可视化。给定内容字形不同区域时的注意力图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号