Master笔记 22-6-13 @英文论文书写@DETR@ViT@CLIP@汉字手写数据集@SwinT@StarGAN
2022-6-13 13:18:16
Brittman读了200多篇中国人的SCI论文,总结出了这些高频错误,你中枪了吗?
https://www.10kn.com/most-common-habits-from-english-papers-written-by-chinese-engineering-students/
file:///F:/Bookmark/Brittman%E8%AF%BB%E4%BA%86200%E5%A4%9A%E7%AF%87%E4%B8%AD%E5%9B%BD%E4%BA%BA%E7%9A%84SCI%E8%AE%BA%E6%96%87%EF%BC%8C%E6%80%BB%E7%BB%93%E5%87%BA%E4%BA%86%E8%BF%99%E4%BA%9B%E9%AB%98%E9%A2%91%E9%94%99%E8%AF%AF%EF%BC%8C%E4%BD%A0%E4%B8%AD%E6%9E%AA%E4%BA%86%E5%90%97%EF%BC%9F%20-%20%E5%8D%81%E5%8D%83%E7%89%9B%20(2022_6_7%2021_32_42).html
定冠词The和不定冠词a/an的主要区别在于,如果一个名词是已经知道的(known)或者是特指的,需要用the,如the plan的言外之意在于作者和读者已经都知道plan是什么,而a plan则表明是一般泛指,提出一个plan,后面再详细表述。
用若干短句代替长难句:更容易被读者理解,每句话只需要表达一个简单的意思,千万不要贪多嚼不烂。
选择列表展示数据和内容:还有一种情况容易出现超长句子,那就是作者希望在一句话中提供太多的数据和内容
把一个句子中的核心内容放到前面说:中国人的思维模式是“因为...所以...”,句子中的后面是重点,而英语当中恰好相反。
表示时间的短语放置在句子的开头
为了表示强调,通常把最重要的部分放在句子开头
用which作为先行词(代词指代的名词或代词)的时候,一定要注意是否会引起缺乏特指、指代不明而引起的混淆:
Incorrect: The Shijiazhuang south road underground bridge possesses the largest jacking force, which is built at 1978(10680t).
Correct: Shijiazhuang south road underground bridge possesses the largest jacking force which is built at 1978(10680t).
Respectively放置于两组对应的短语末尾:用于之前已经提到顺序的两个或两个以上的人或物,表示他们之间“分别地”关系,如果之前给出的是两个列表,则respectively指两个列表之间元素一一对应的关系。
"In this paper"不能滥用:通常这个短语有两种用途:1.在Introduction和conclusion中用于强调文章内容; 2.在正文中,在讨论作者未做的工作之后(如他人论文和标准规范等)。某些情况可以用"in this study"代替。‘study’是作者做出的工作,‘paper’指的是读者正在读的这篇论文(在工作的基础上加工而成的)
句子的开头不要出现阿拉伯数字
Incorrect: 12 parameters were selected for the experiment.
Correct: Twelve parameters were selected for the experiment.
Incorrect: All 3 studies concluded that the mean temperature should be 30°C.
Correct: All three studies concluded that the mean temperature should be 30°C.
数字最好只用于确切的试验数据,对于泛指的内容尽量不要用,尤其是尽量不要在一个句子中用太多数字。
许多文献都不主张在正文中用短的表达式代替文字
Incorrect: If the power battery SOC > SOClo and the driving torque belongs to the middle load,…
Correct: If the power battery SOC is greater than SOClo and the driving torque belongs to the middle load,…
关于figure 和 table 的缩写是 Fig. and Tbl。在文中使用全称figure或者简写fig,需要统一,不要二者都写,而且在句子开头不要使用缩写
Incorrect: Figure.6, Figure6, Fig.6, Tbl10
Correct: Figure 6, Fig. 6, Tbl. 10
变量,尤其是英文字母代表的变量,应该使用斜体表达
Such as表示for example,并且暗示:incomplete list will follow
etc.表示and so on,并且暗示 list is not complete
Incorrect: Compared to traditional industry, Micro-electronic fabrication has three characteristics such as high complexity, high precision and high automation.
Correct: Compared to traditional industry, Micro-electronic fabrication has three characteristics: high complexity, high precision and high automation.
上面由于three characteristics都给出来了,因此不能用such as(是完整、确定的列举,such as 是列举有代表性的几个)
有些词汇单复数相同,因此不需要加“s”,如:
- literature (when referring to research)
- equipment,
- staff (referring to a group of people)
- faculty
| insdead of | say | or say |
|---|---|---|
| research work | research | work |
| limit condition | limit | condition |
| knowledge memory | knowledge | memory |
| sketch map | sketch | map |
| layout scheme | layout | scheme |
| arrangement plan | arrangement | plan |
| output performance | output | performance |
| knowledge information | knowledge | information |
| calculation results | results | calculation |
| application results | results | application |
| Don't write | write |
|---|---|
| different node | different nodes |
| various method | various methods |
| two advantage | two advantages |
| fifteen thermocouple | fifteen thermocouples |
使用 ‘by this way’. Instead write ‘by doing this’, or ‘using this method’.
句子不要以 ‘How to…’ 开头
Incorrect: How to find the optimal parameter is the main objective.
Correct: Determining how to find the optimal parameter is the main objective.
避免 obviously 的滥用
国际文章中,不要写‘at home’, ‘abroad’, ‘here’, ‘our country’,因为读者大多不是中国人,写成 ‘in China’
避免写‘that is to say’ and ‘namely’,尽量在一个句子里表达你的意思
在句子的结尾避免用‘too
LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding
https://paperswithcode.com/paper/layoutxlm-multimodal-pre-training-for
Multimodal pre-training with text, layout, and image has achieved SOTA performance for visually-rich document understanding tasks recently
文本、布局、图片模态的多语言文档理解模型
Screen2Words: Automatic Mobile UI Summarization with Multimodal Learning
https://paperswithcode.com/paper/screen2words-automatic-mobile-ui
https://arxiv.org/abs/2108.03353v1
Mobile User Interface Summarization generates succinct language descriptions of mobile screens for conveying important contents and functionalities of the screen
即移动端用户界面概括,输入app描述、视图层级信息(autojs那种, json)、UI截图,输出一段话描述该UI的作用
DALL·E Mini
https://github.com/borisdayma/dalle-mini
Generate images from a text prompt
根据文本生成对应的图片
VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
https://paperswithcode.com/paper/vatt-transformers-for-multimodal-self
We present a framework for learning multimodal representations from unlabeled data using convolution-free Transformer architectures.
video action recognition, audio event classification, image classification, and text-to-video retrieval
根据无标注数据进行自监督学习,可用于视频动作识别、音频事件分类、图像分类和文本到视频检索
2022-6-14 15:36:07
又一篇超百名作者的 AI 论文问世!442 位作者耗时两年发布大模型新基准 BIG-bench…
https://mp.weixin.qq.com/s/eHSIVK3OfT89Bm5OqF93zA
Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models
大模型新基准:BIG-Bench
BIG bench由 204 项任务组成,任务主题涉及语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等等领域的问题。
Beyond the Imitation Game 基准(BIG-bench)的GitHub 资源库包括:
- 超过 204 个语言任务。如 BIG-bench 审查标准那样,基准任务涵盖了不同的主题和语言,并且是目前的模型所不能完全解决的。
- BIG-bench Lite:一个小型、且具有代表性的任务子集,比在整个基准上进行更快的评估。
- 实现基准 API 的代码:支持在公开可用的模型上进行任务评估,并实现新任务的轻量级创建。
- 对规模横跨六个数量级的密集和稀疏语言模型的详细评估结果,以及由人类评估员建立的基线结果。
总结:看起来是整理了一些用于评估大模型的语言任务,并且实际对比测试了一些模型,得出了语言模型性能和模型规模之间的联系
一夜之间,谷歌 AI 就具有了“人格”......
https://mp.weixin.qq.com/s/OWSZGjVnkz7j0KGLzFuq5g
故事的主角是「他」和「它」:「他」是41岁的谷歌工程师Blake Lemoine,「它」是谷歌于2021年I/O大会上推出的对话AI系统LaMDA,是一个有1370亿参数的,专为对话优化的自然语言处理模型。
Blake Lemoine在谷歌的Responsible AI机构工作,与LaMDA系统对话是他工作的重要一部分。并且,他还一直致力于测试人工智能是否使用歧视性或仇恨言论。
硕士毕业论文写不出来导致严重焦虑,怎么办?
https://mp.weixin.qq.com/s/_1rIPSe3ce1eMlb0rj1_WA
关于选题是否好写,这里有一个重要坐标可以参考,那就是各大顶级会议的收录情况,比如ACM CIKM、ICLR等,他们通常代表着学术界的风向标
主要是看两个指标,一个是自己研究方向的论文收录篇数,第二个是收录排名历史对比
超越CLIP!谷歌发布首个大规模MoE架构的视觉语言模型
https://mp.weixin.qq.com/s/DWu9W3w43TYHWQRj-MI-NA
谷歌带来最新成果LIMoE,首次将稀疏化方法用在了图像文本混合模型上。谷歌想到的办法,不是拼硬件,而是从模型本身入手。利用稀疏化的方法,让每次输入只需激活部分网络就能完成任务。他们在模型内部设置了很多“专家”,每个“专家”只需处理对应部分的输入,根据任务情况按需使用“专家”就好。这样一来,尽管模型容量很大,但是计算成本并没有暴增。
对于深度学习来说,能同时处理文本图像任务其实已经不稀奇。不过过去常见的多模态学习方法,往往是单个输入就需要激活整个网络。谷歌这次提出的新方法,最大亮点就是首次在这一领域采用了稀疏化模型。
此次新提出的LIMoE,其实就是让MoE能同时处理图像文本。具体来看,就是让LIMoE进行对比学习。
在利用大量图像-文本对训练时,网络内部的图像模型提取图像表示,文本模型提取文本表示。针对相同的图像-文本对,模型会拉近图像和文本表示的距离。
反之,对于不同的图像-文本对,则会让相应的表示彼此远离。这样一来的直接好处,就是能实现零样本学习。比如一张图像的表示更接近文本“狗”的表示,那么它就会被归类为狗。这种思路可以扩展到数千种情况。
此次基于的模型是MoE(Mixture-of-Experts layer),它被称为专家混合模型。也就是在Transformer架构的基础上,加设了“专家层”。
除了性能上的提升,使用稀疏化模型的好处还体现在降低计算成本上。因为“多专家”的模式意味着,尽管多设了很多子模型,模型容量显著增加,但是实际计算成本并没有明显变化。
硬刚Meta!字节把元宇宙跳动到了美国
https://mp.weixin.qq.com/s/54T71lKL2Jwth_RAjFt70A
Meta在2020年推出的Quest 2相当的成功,根据IDC最新的估计,Meta至今卖出了近1500万台。
Oculus Quest2 VR眼镜一体机体感游戏机头戴影院显示器虚拟眼镜
DisplayPort连接线发光发热了——给Pico Neo 3 Link提供无损的高清画面。
而Quest 2只能使用USB进行有线连接,此时传输的图像显然是会被压缩的。
也就是说,在玩儿PC上的VR游戏时,Neo 3 Link的画质要比Quest 2好得多。
内容上,Neo 3 Link会略逊一筹。此外,Neo 3 Link也不支持手部追踪功能,好在商用的Pro版可以通过Ultraleap外部传感器搞定。即便如此,Neo 3 Link也能凭借着比低配更低的价格,以及和高配相同的参数,在性价比上扳回一城。想必在进军美国之后,Neo 3 Link也能凭借着这个优势,和Meta Quest 2打得有来有回。
CMU 提出全新 GAN 结构,GAN 自此迈入预训练大军!
https://mp.weixin.qq.com/s/j7Lia_8UTbKUcGk2eHY5GQ
GAN的训练基本上是从头开始!!因为GAN的判别器好坏直接影响生成器的梯度,判别器太好将导致生成器的梯度消失,网络就没法训练了
今年 CVPR'2022的一篇Oral 引入了叫做 Vision-aided GAN(以下简称VAG)的全新结构,使得 GAN 也能够采用预训练+精调的范式。此外,VAG 只用1%的训练数据就达到了与StyleGAN相匹配的水准,使得训练难度显著降低。
Ensembling Off-the-shelf Models for GAN Training
https://github.com/nupurkmr9/vision-aided-gan
训练思想非常简单,首先搭建好一个的预训练模型库,然后从模型库中取出若干个模型再接上分类头组成的新判别器,再跟初始GAN网络的判别器并联
也就是说并联的判别器会跟原始判别器一起去训练,由于原始的判别器不够强,所以能一定程度上避免梯度消失,又因为新的判别器是用大数据集训练好的模型,其中蕴含的丰富特征也让GAN网络不至于在某个数据集上过拟合。
这篇文章的思路很直观,但是在实验中如何平衡新引入的GAN判别器Loss和原始判别器Loss是一个很难的抉择问题,因为在训练过程中,由于原始判别器Loss始终处于一个主导地位,很有可能模型直接摆烂完全不优化第二部分判别器的Loss,所以能把这种方法做work的才是真正的大佬呀。
2022-6-15 16:24:10
StyleGAN-基于样式的生成对抗网络(论文阅读总结)
https://zhuanlan.zhihu.com/p/63230738
StyleGAN 和 StyleGAN2 的深度理解
https://zhuanlan.zhihu.com/p/263554045
latent code 简单理解就是,为了更好的对数据进行分类或生成,需要对数据的特征进行表示,但是数据有很多特征,这些特征之间相互关联,耦合性较高,导致模型很难弄清楚它们之间的关联,使得学习效率低下,因此需要寻找到这些表面特征之下隐藏的深层次的关系,将这些关系进行解耦,得到的隐藏特征,即latent code。由 latent code组成的空间就是 latent space。
Lazy regularization
损失 是由损失函数和正则项组成,优化的时候也是同时优化这两项的,lazy regularization就是正则项可以减少优化的次数,比如每16个minibatch才优化一次正则项,这样可以减少计算量,同时对效果也没什么影响。
No Progressive growth
StyleGAN使用的Progressive growth会有一些缺点,如下图,当人脸向左右偏转的时候,牙齿却没有偏转,即人脸的一些细节如牙齿、眼珠等位置比较固定,没有根据人脸偏转而变化,造成这种现象是因为采用了Progressive growth训练,Progressive growth是先训练低分辨率,等训练稳定后,再加入高一层的分辨率进行训练,训练稳定后再增加分辨率,即每一种分辨率都会去输出结果,这会导致输出频率较高的细节,如下图中的牙齿,而忽视了移动的变化。
2022-6-16 15:47:31
搞懂 Transformer 结构,看这篇 PyTorch 实现就够了
https://mp.weixin.qq.com/s/FWT7vUSqXlohWro7CQLmWw
介绍了一个用pytorch实现Transformer并附有注释的github仓库,2022年有过更新,代码较为简洁易懂,有参考价值,可以跟Huggingface的实现比较
DETR 论文精读【论文精读】
DETR: DEtection TRansformer
End-to-End Object Detection with Transformers
这个方法十分简单,而且是端到端的,不需要NMS等后处理,超参数简化了不少
使目标检测成为跟图像分类一样简单的任务,不需要过多的人工干预
主要工作:
将目标检测看做是一个集合预测的问题,不同图片包含的预测框不同,将框看作集合的元素,任务就变成了预测给定图片所对应的集合
贡献:
- 新的损失函数,通过二分图匹配的方式强制模型输出一组独一无二的框,也就是理想状态下每个物体只有一个预测框
- 使用了Transformer Encoder-Decoder架构
- 以learned object query作为decoder的另一个输入
- 与NLP中decoer自回归输出不同,这里一张图片的所有预测框并行地同时生成
优点:
- 模型简单,对部署的硬件没有特殊要求
- 在COCO上性能与Faster-RCNN差不多
- 可以简单地拓展到其他任务,如全景分割
- 对大物体相比anchor方法更有优势,利用Transformer的全局信息理论上无论多大都可以检测
缺点:
- 对于小物体检测效果不好,可以通过多尺度的特征解决
- 训练太慢,在COCO上训练了500个Epoch,而大家一般只训练几十个
- 而且因为使用Transformer不好优化
注: 代码挺好,建议阅读
流程:
- 对于一张图片先使用CNN抽取特征再送入Transformer Encdoer
- 使用了Transformer Encoder能更好利用全局信息去除同一物体冗余的检测框
- Transformer Decoder 生成固定数量的预测框
- 将生成的框和ground-truth做匹配,互相匹配的算loss,其余没能匹配的预测框就当做背景类
- 推理的时候第四步换成抽取第三步中大于阈值的框作为输出
将元素为loss的cost matrix使用scipy提供的linear-sum-assingment就可以得到最优匹配 —— 哪一个工人完成哪项任务花费的成本最低,对应到这里就是100个预测框中哪几个对应ground-truth最优
Encoder学全局信息,将物体分开,而Decoder更细致地区分物体的极值点,比如动物的尾巴跟蹄子。因此二者缺一不可
trick:
- auxiliary loss: 每层decoder后面都接FFN得到输出来算loss,将这些loss相加作为总的loss,可以加快模型的收敛。这些FFN共享参数
- 流程第一步的卷积网络backbone用的是预训练的resnet50:
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2]) - 分别用两个FFN处理最终Transformer的输出,一个负责预测类别,一个负责预测框(4个值)
- 自觉想法好,但是在一个数据集上不分数不如其他方法,可以换个数据集,或者通过消融实验、可视化等证明提出的方法有效,如对encoder、decoder跟object query进行可视化
- DETR相关的论文,有一个研究方向是把object query分解为content query和spacial query来提升性能
2022-6-17 10:35:07
Github 3.8k,人、车、OCR 等 9 大高精度超轻量图像识别模型全开源!!
https://mp.weixin.qq.com/s/X9hMVCFfvaytgITKhAz9EA
完全开源免费的、覆盖人、车、OCR 等 9 大经典识别场景、在 CPU 上可 3 毫秒实现急速识别、一行代码就可实现迭代训练的项目
https://github.com/PaddlePaddle/PaddleClas
PaddleClas 推出的超轻量图像分类方案(Practical Ultra Light Classification,简称 PULC),就完美解决上述产业落地中算法精度和速度难以平衡的痛点。
它的精度与 Swin-Transformer 等大模型比肩,预测速度却可以快 30 倍以上,在 CPU 上的推理时长仅需 2ms!项目还匹配了详细的中文使用文档及产业实践范例教程。
超轻量图像分类方案(PULC)集成了业界 4 大业界领先的优化策略:
- PP-LCNet 轻量级骨干网络
PP-LCNet 作为针对 CPU 量身打造的骨干网络模型,在速度、精度方面均远超如 MobileNetV3 等同体量算法,多个场景模型优化后,速度较SwinTransformer的模型快30倍以上,精度较 MobileNetV3_small_0.35x 高 18 个点。 - SSLD 预训练权重
SSLD半监督蒸馏算法可以使小模型学习到大模型的特征和 ImageNet22k 无标签大规模数据的知识。在训练小模型时,使用 SSLD 预训练权重作为模型的初始化参数,可以使不同场景的应用分类模型获得 1-2.5 个点的精度提升。 - 数据增强策略集成
该方案融合了图像变换、图像裁剪和图像混叠 3 种数据增强方法,并支持自定义调整触发概率,能使模型的泛化能力大大增强,提升模型在实际场景中的性能。模型可以在上一步的基础上,精度再提升 1 个点左右。 - SKL-UGI 知识蒸馏算法
SKL(symmetric-KL) 在经典的KL知识蒸馏算法的基础上引入对称信息,提升了算法的鲁棒性。同时,该方案可以方便的在训练中加入无标签训练数据(Unlabeled General Image),可以进一步提升模型效果。该算法可以使模型精度继续提升 1-2 个点。
【机器学习】详解 Vision Transformer (ViT)
https://blog.csdn.net/qq_39478403/article/details/118704747
该文章为ViT论文的翻译
论文:https://arxiv.org/abs/2010.11929
代码:GitHub - google-research/vision_transformer

ViT 模型
完全不使用CNN:直接应用于图像块序列 (sequences of image patches) 的纯 Transformer 可以很好地执行 图像分类 任务。当对大量数据进行预训练并迁移到多个中小型图像识别基准时 (ImageNet、CIFAR-100、VTAB 等),与 SOTA 的 CNN 相比,Vision Transformer (ViT) 可获得更优异的结果,同时仅需更少的训练资源。
尽量少的修改,仿照NLP方式使用Transformer:将图像拆分为块 (patch),并将这些图像块的线性嵌入序列作为 Transformer 的输入。图像块 image patches 的处理方式与 NLP 应用中的标记 tokens (单词 words) 相同
中型数据集上不如ResNet:Transformers 缺乏 CNN 固有的一些归纳偏置 (inductive biases),例如平移等效性和局部性 (translation equivariance and locality),因此在数据量不足的情况下训练时不能很好地泛化。
大规模数据集效果好:Vision Transformer (ViT) 在以足够的规模进行预训练并迁移到具有较少数据点的任务时获得了出色结果。
图像块嵌入:将一个图像(shape=\(H\times W\times C\))分割成N块\(P\times P\)的patches,其中\(N=HW/P^2\),即Transformer的输入长度,然后每块patch再flatten成向量,使用全连接层变换为D维,此时输入变为了\(N\times D\),相当于 NLP 中的 词嵌入 (Word Embeddings)
可学习的嵌入:类似于BERT中的[class] token,ViT引入了class token机制,因为ViT基于Transformer的Encoder,输出与输入等长,同样是N个向量,最终取哪一个输出向量作为分类向量就需要选择。这里在输入向量前插入一个可学习的class token,一共N+1个输入向量。这样就能取class token对应的输出向量作为分类向量。
位置嵌入:ViT 采用 标准可学习/训练的 1-D 位置编码嵌入,因为更高级的 2-D-aware 位置嵌入 (附录 D.4) 没有更显著的性能提升。在输入 Transformer 编码器之前直接 将图像块嵌入和位置嵌入按元素相加
微调:用比预训练时更高的图像分辨率进行微调通常更有益。当提供更高分辨率的图像时,需要保持图像块大小相同,此时会使有效序列长度更长。Vision Transformer 可处理任意序列长度 (取决于内存限制),但 预训练的位置嵌入可能不再有意义。因此,我们根据它们在原始图像中的位置,对预训练的位置嵌入执行 2D 插值。
Scalability:Transformer 的一个特色,当模型和数据量提升时,性能持续提升。在大数据下,ViT 可能会发挥更大的优势。预训练的数据量须达到 100M 时才能凸显 ViT 的优势,性能才能比肩CNN。
详解CLIP (一) | 打通文本-图像预训练实现ImageNet的zero-shot分类,比肩全监督训练的ResNet50/101
https://zhuanlan.zhihu.com/p/521151393
论文:Learning Transferable Visual Models From Natural Language Supervision
代码:https://github.com/openai/CLIP
Alec Radford等人提出Contrastive Language-Image Pre-training (CLIP), 突破了文本-图像之间的限制。CLIP使用大规模的文本-图像配对预训练,并且可以直接迁移到Imagenet上,完全不需要图像标签微调即可实现zero-shot分类。CLIP模型或许会引导CV的发展走向大规模预训练,文本-图像打通的时代。
文本-图像对:图片以及对应的文本描述
模型结构:包括两个部分,即文本编码器(Text Encoder)和图像编码器(Image Encoder)。Text Encoder选择的是Text Transformer模型;Image Encoder选择了两种模型,一是基于CNN的ResNet(对比了不同层数的ResNet),二是基于Transformer的ViT。
CLIP在文本-图像对数据集上的训练过程:通过编码器将N个文本图像对编码为N个文本一维向量和N个图片一维向量,对应的作为正样本,共N个,不对应的为负样本,有\(N^2-N\)个。通过最大化正样本之间的余弦相似度,最小化负样本的余弦相似度来进行训练。
训练成果:通过大批量的文本-图像预训练后, CLIP可以先通过编码,计算输入的文本和图像的余弦相似度,来判断数据对的匹配程度。
zero-shot图像分类步骤:
- 根据所迁移的数据集将所有类别转换为文本。这里以Imagenet有1000类为例,我们得到了1000个文本:A photo of {label}。我们将这1000个文本全部输入 Text Encoder中,得到1000个编码后的向量\(T_i\) ,这被视作文本特征。
- 我们将需要分类的图像(单张图像)输入Image Encoder中,得到这张图像编码后的向量\(I_1\) .将\(I_1\)与得到的1000个文本特征分别计算余弦相似度。找出1000个相似度中最大的那一个,那么如果要分类的图片与第三个文本标签(dog)最匹配,即可将其分类为狗。
在ImageNet-A数据集(分布漂移,即数据集中不同类别图像的数量分布不均衡)上,CLIP可以达到77.1%,而ResNet只有2.7%(基本属于瞎猜)。这证明了使用文本-图像做预训练的CLIP具备更强的鲁棒性。
2022-6-18 14:16:00
腾讯计算机视觉,已经世界第二了。。。
https://mp.weixin.qq.com/s/rp3_GSkKZ8iSwjfZP4P2-w
Gartner在报告中指出:「在计算机视觉领域,腾讯的得分是3.53,在此次评分排名中位居全球第二。腾讯利用其在游戏、视觉和其他服务领域的广泛AI资源,不断来验证和完善其能力。腾讯还拥有强大的计算机视觉服务产品,包括视频服务(如面部识别、人体分析和情感分析)、图像处理和分析,以及OCR能力。」
依托腾讯优图实验室,通过AI与云的深度融合,腾讯云对外输出超过300+标准化AI原子能力和80+AI解决方案,覆盖行业超过30个大类,100个子类,为数十万家内外部客户提供AI技术服务和丰富的计算机视觉产品组合。此外,腾讯云计算机视觉能力也已经在工业、新能源汽车等实体经济场景加速落地。
在算法研究方面,优图的研究成果多次在人工智能国际权威比赛中创造了世界纪录。
在学术研究方面,优图公开发表的论文涵盖ICCV,CVPR,ECCV等各类全球顶级会议,仅2022年即被全球顶级会议CVPR接收了30篇论文。
“我要做小小瑶大人的狗!”
https://mp.weixin.qq.com/s/I4UvFszN9rXfPMDpiqwaWA
Speak Like a Dog: Human to Non-human creature Voice Conversion
由日本学术振兴会赞助,立命馆大学:人狗语音转换
任务的输入是人声音频,输出是合成的狗叫音频。数据音源中,包含503段人类的声音,自收集了成年犬792段和幼崽288段叫声。论文采用音频合成领域经典的StarGAN和ACVAE作为benchmark,并设计了三个主观定性指标:输出音频和狗叫声的相似度,音频质量,声音清晰度;还有一个量化指标,角色偏差程度(character error rate, CER)用于评估模型的效果。目前为止,benchmark在测试中遥遥领先。
本质上是想把人类的话语声变换成接近狗叫,但又要保留语义信息,是一种他们自己提出来的新的语音转换任务,voice conversion (VC),他们将其称为human to non-human creature voice conversion (H2NH-VC) tasks。
做了一些比较实验,使用StarGAN-VC、ACVAE-VC跟梅尔倒谱系数(MCC)、梅尔频谱(melspec)的排列组合,以及FKN、成年狗叫、白噪声之间的对照。结果显示梅尔频谱有助于使输出贴近狗叫,但如何保留语义信息是一大挑战。
NLP开源数据集汇总
https://mp.weixin.qq.com/s/zZ30hnrheOKGLxFZXT8wIA
- CASIA手写数据集
- Twitter地理定位信息数据集
- 印度新闻头条数据集
- 专利短语数据集
- 电影元数据
- Twitter 情绪推文数据集
- 幸福畅销书评论数据集
- Olist电子商务公共数据集
- 假新闻和真实新闻数据集
- Top1000的Github存储库数据集
其中一些的展示图分明就是kaggle的页面,却只贴出一个叫极市的网站的下载连接
CASIA手写数据集
CASIA-HWDB-T:一个从中文手写数据库CASIA-HWDB收集的触摸字符数据库。所有接触的字符(或字符串)都用字符类别、接触点的位置以及字符串高度(LH)和平均笔划宽度(SW)等辅助值进行注释。
感觉挺有趣的,做仿真手写用于印刷(已经有不少这方面的研究,如zi2zi)
官网主页:http://www.nlpr.ia.ac.cn/databases/handwriting/Touching_Characters_Databases.html
对应kaggle链接:Handwritten Chinese Character (Hanzi) Datasets
联机手写汉字数据集下载总结
https://blog.csdn.net/lph188/article/details/102731309
- 中科院CASIA数据集
- 哈工大HIT-OR3C数据集
- 华南理工SCUTCOUCH-2009数据集
【论文翻译】HCL2000—A Handwritten Chinese Character Database
https://blog.csdn.net/weixin_43624538/article/details/88528170
提出了一种大规模离线手写汉字数据库-HCL2000,包含3,755个经常使用的简体中文字符,由1,000名不同的受试者撰写,并且包含受试者的年龄、职业、性别、教育等信息。
汉字手写训练和识别
https://zhuanlan.zhihu.com/p/351413580
HITHCD-2018:哈尔滨工业大学收集的、用于手写汉字识别(HCCR)的大型数据库,有超过5346名书写者书写,目前规模最大、字类最多的数据库(Tonghua Su et al. HITHCD–2018: Handwritten Chinese Character Database of 21K-Category, ICDAR, 2019)
6分钟听懂Swin Transformer V2【CVPR2022 Oral】
https://www.bilibili.com/video/BV1gU4y1X7KK
视觉领域中的最大模型ViT-G(1.8B)比NLP领域的最大模型(Megatron-Turing)小了近300倍,而Swin-v2大约3B
目前模型训练范式:
先在大规模数据集进行与训练(JFT-3B)然后通过微调迁移到下游任务中
训练大模型的主要挑战:
- 模型变大后训练会变得不稳定
- 预训练任务与下游任务所用的图片分辨率差距很大
- 大模型需要更大更大的标注数据进行训练
解决办法:
- 调整Layer Norm的位置,使得残差连接加回主流的时候有归一化的效果,使得输入方差增大得到控制,同时也要将点乘注意力变为余弦注意力
- 使用小网络生成连续偏置矩阵,并使用对数输入空间,使扩大窗口时产生更小的外插率?
- 使用SimMIM进行自监督学习解决数据不足的问题
图解Swin Transformer
https://zhuanlan.zhihu.com/p/367111046
Transformer在图像领域两大挑战:
- 视觉实体变化大,在不同场景下视觉Transformer性能未必很好
- 图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大
针对上述两个问题,提出了一种包含滑窗操作,具有层级设计的Swin Transformer。
其中滑窗操作包括不重叠的local window,和重叠的cross-window。将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量。
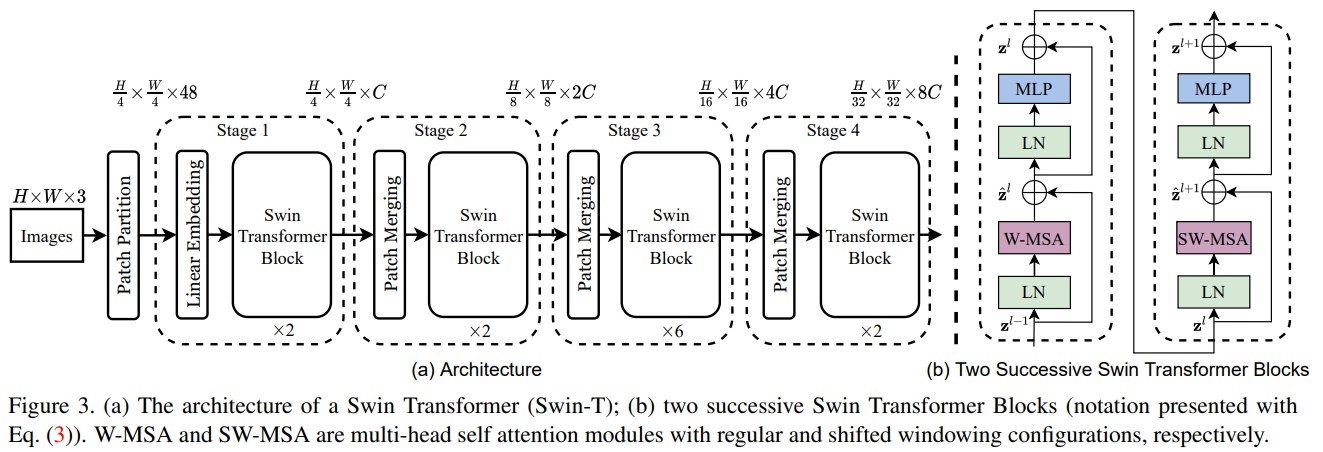
Swin Transformer的整体架构
整个模型采取层次化的设计,一共包含4个Stage,每个stage都会缩小输入特征图的分辨率,像CNN一样逐层扩大感受野。
- 在输入开始的时候,做了一个Patch Embedding,将图片切成一个个图块,并嵌入到Embedding。
- 在每个Stage里,由Patch Merging和多个Block组成。
- 其中Patch Merging模块主要在每个Stage一开始降低图片分辨率。
- 而Block具体结构如右图所示,主要是LayerNorm,MLP,Window Attention 和 Shifted Window Attention组成 (为了方便讲解,我会省略掉一些参数)
其中有几个地方处理方法与ViT不同:
- ViT在输入会给embedding进行位置编码。而Swin-T这里则是作为一个可选项(self.ape),Swin-T是在计算Attention的时候做了一个相对位置编码
- ViT会单独加上一个可学习参数,作为分类的token。而Swin-T则是直接做平均,输出分类,有点类似CNN最后的全局平均池化层
Patch Embedding
在输入进Block前,我们需要将图片切成一个个patch,然后嵌入向量。
Patch Merging
该模块的作用是在每个Stage开始前做降采样,用于缩小分辨率,调整通道数 进而形成层次化的设计,同时也能节省一定运算量。
Window Partition/Reverse
window partition函数是用于对张量划分窗口,指定窗口大小。而window reverse函数则是对应的逆过程。这两个函数会在后面的Window Attention用到。
Window Attention
这是这篇文章的关键。传统的Transformer都是基于全局来计算注意力的,因此计算复杂度十分高。而Swin Transformer则将注意力的计算限制在每个窗口内,进而减少了计算量。主要区别是在原始计算Attention的公式中的Q,K时加入了相对位置编码(不是在原始输入X中加入,X分解为QKV计算注意力时才加入)。后续实验有证明相对位置编码的加入提升了模型性能。
Shifted Window Attention
前面的Window Attention是在每个窗口下计算注意力的,为了更好的和其他window进行信息交互,Swin Transformer还引入了shifted window操作。即通过移位改变窗口的切分方法,使得不同的窗口能够进行信息交互,这样窗口数也得改变,代码中通过torch.roll将图移位后再结合mask达到这一效果。
Attention Mask
通过设置合理的mask,让Shifted Window Attention在与Window Attention相同的窗口个数下,达到等价的计算结果。
Transformer Block整体架构
一个Stage包含的Block个数必须是偶数,因为需要交替包含一个含有Window Attention的Block和含有Shifted Window Attention的Block。
结构见上图(b)
- 先对特征图进行LayerNorm
- 通过self.shift_size决定是否需要对特征图进行shift
- 然后将特征图切成一个个窗口
- 计算Attention,通过self.attn_mask来区分Window Attention还是Shift Window Attention
- 将各个窗口合并回来
- 如果之前有做shift操作,此时进行reverse shift,把之前的shift操作恢复
- 做dropout和残差连接
- 再通过一层LayerNorm+全连接层,以及dropout和残差连接
总结
这篇文章创新点很棒,引入window这一个概念,将CNN的局部性引入,还能控制模型整体计算量。在Shift Window Attention部分,用一个mask和移位操作,很巧妙的实现计算等价。作者的代码也写得十分赏心悦目,推荐阅读!
关于相对位置编码
relative_position_bias_table为一堆需要学习的bias
法1:relative_position_index在table提取bias再加在atn上
法2:直接把bias按顺序加在atn上
拿一维位置关系举例, 1,2,3,4 四个位置,法1不管计算那个位置,编码始终是不变的。
但是法2(相对位置编码),计算1位置的时候,四个位置编码idx是 1,2,3,4. 计算 2位置的时候,四个位置编码是0,1,2,3,同理3的时候是-1,0,1,2, 4的时候是-2,-1,0,1。就是计算当前位置的时候,前第N个位置对应的位置编码idx始终是 -N,后第N个位置对应的位置编码idx始终是N。只要两个位置相对关系不变,位置编码就不变。
[CVPR 2020] StarGAN v2: 多域风格图像合成,效果惊人,史上最强!
https://zhuanlan.zhihu.com/p/339257152
补充:starGAN v2 论文阅读
paper: StarGAN v2: Diverse Image Synthesis for Multiple Domains
code: https://github.com/clovaai/stargan-v2
摘要
一个好的图像转换模型应可以学习不同图像域间的映射,同时:1)生成图像多样化;2)在多个域上具有可扩展性。现有方法则无法很好同时解决上述问题。
提出StarGAN v2Q和新的动物面孔数据集(AFHQ),一个可同时解决上述问题、并在基线上表现出明显改善效果的单一框架。在CelebAH和AFHQ上进行视觉质量、多样性和可扩展性方面验证其有效性。
背景
domain表示一组图像,被分组的依据可以是视觉上具有某种属性/类别。
而每幅图像有独特的外观,称为样式/风格style。例如,可根据人的性别设置图像域domain,在这种情况下,风格样式包括妆容类别、胡须和发型等。
大概就是范围更大的可区分特征叫做域,范围小的叫做风格。
一个理想的图像转换模型应该考虑域内的多样化的风格。但设计和学习此类模型会变得很复杂,因为数据集中可能有大量的style和domain。
针对style的多样性,目前的方法(Pix2Pix模型解决了有Pair对数据的图像翻译问题;CycleGAN解决了Unpaired数据下的图像翻译问题。)大都仅考虑两个域之间的映射,例如K个域,这些方法需要训练K(K-1)生成器来处理每个域与每个域之间的转换,限制了它们的实际使用。
为此,一些研究提出更具扩展性、统一的框架,StarGAN便是最早的模型之一,它使用一个生成器来学习所有可用域间的映射。生成器将域标签作为附加输入,并将图像转换到相应的域。但StarGAN仍然学习每个域的确定性映射(对于同一张输入的图片,由于输入跟one-hot标签都一样,因此结果也一样),不能学到数据分布多种模态的特性。
网络结构
本文提出的StarGAN v2,是一种可扩展的方法,可跨多个域生成不同的图像。基于StarGAN,使用所提出的domain-specific style code替换域标签,前者可表示特定领域的各种风格样式。为此,引入两个模块,一个映射网络mapping network和一个样式编码器stye encoder。
映射网络学习将随机高斯噪声转换为样式码(style code),而编码器则学习从给定的参考图像中提取样式码。考虑到多个域,两个模块都具有多个输出分支,每个分支都提供特定域的样式码。最后,利用这些样式码,生成器将学习在多个域上合成各种图像。
生成器 Generator:将输入图像x转换到输出图像G(x, s),后者体现的是指定domain的风格码s,该码由映射网络F或样式编码器E提供。其中,使用的是自适应实例归一化(AdaIN)将s注入G。s被设计为表示特定域y的样式,这消除了向G提供y的必要性,并使G可以合成所有域的图像。
映射网络 Mapping network:给定一个隐向量z和一个域y,映射网络F生成样式码\(s=F_y(z)\)。 F由具有多个输出分支的MLP组成,可为所有可用域提供样式码。训练的时候随机采样Z中的样本z和随机采样域Y中的一张图片来使得该网络有效的学到所有域的风格表示,来产生多种样式码,因此可以实现多样性风格生成。
判别器 Discriminator:多任务分类器,有多个输出分支。每个分支\(D_y\)使用一个二进制分类确定图像x是域y的真实图像还是G生成的伪图像\(G(x,\;s)\)
使用多个分类器是为了避免笼统地判断生成地是否真实,因为我们要的是生成地图片在特定域上地真实,而不是随便地真实,优化更加具体了。
StarGAN学习笔记(八)
https://zhuanlan.zhihu.com/p/44563641
论文地址:StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
代码地址(Pytorch):https://github.com/yunjey/StarG
本文贡献:
- 提出StarGAN模型,使用单组GAN模型进行跨domain和跨数据集的训练
- 展示了mask vector技术来实现上述的训练过程
- 训练了角色的面部属性和面部表情特征的各种图片
要想让G拥有学习多个领域转换的能力,本文对生成网络G和判别网络D做如下改动:
- 在G的输入中添加目标领域信息c,即把图片翻译到哪个领域这个信息告诉生成模型。
- D除了具有判断图片是否真实的功能外,还要有判断图片属于哪个类别的能力。这样可以保证G中同样的输入图像,随着目标领域的不同生成不同的效果。
- 除了上述两样以外,还需要保证图像翻译过程中图像内容要保存,只改变领域差异的那部分。图像重建可以完整这一部分,图像重建即将图像翻译从领域A翻译到领域B,再翻译回来,不会发生变化。
多训练集进行训练:
在多数据集下训练StarGAN存在一个问题,那就是数据集之间的类别可能是不相交的,但内容可能是相交的。比如CelebA数据集合RaFD数据集,前者拥有很多肤色,年龄之类的类别,而后者拥有的是表情的类别。但前者的图像很多也是有表情的,这就导致前一类的图像在后一类的标记是不可知的。为了解决这个问题,在模型输入中加入了Mask,即如果来源于数据集B,那么将数据集A中的标记全部设为0。
处理流程:
- 将输入图片x和目标生成域c结合喂入到生成网络G来合成fake图片
- 将fake图片和真实图片分别喂入到鉴别器D,D需要判断图片是否真实,还需要判断它来自哪个域
- 与CycleGAN类似,还有一个一致性约束,将生成的fake图片和原始图片的域信息c'结合起来喂入到生成器G要求能输出重建出原始输入图片x

 浙公网安备 33010602011771号
浙公网安备 33010602011771号