python plt让scatter能够使不同类别的点有不同的颜色、大小和形状
参考:https://blog.csdn.net/weixin_43769946/article/details/103522194
python自带的plt可以给不同类别生成不同的颜色,但不能生成不同的性形状。所以需要自己实现一个方法。
1.定义mscatter函数
import matplotlib.pyplot as plt def mscatter(x, y, ax=None, m=None, **kw): import matplotlib.markers as mmarkers if not ax: ax = plt.gca() sc = ax.scatter(x, y, **kw) if (m is not None) and (len(m) == len(x)): paths = [] for marker in m: if isinstance(marker, mmarkers.MarkerStyle): marker_obj = marker else: marker_obj = mmarkers.MarkerStyle(marker) path = marker_obj.get_path().transformed( marker_obj.get_transform()) paths.append(path) sc.set_paths(paths) return sc
2.例子
from sklearn.datasets import make_blobs import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.mixture import GaussianMixture import numpy as np def mscatter(x, y, ax=None, m=None, **kw): import matplotlib.markers as mmarkers if not ax: ax = plt.gca() sc = ax.scatter(x, y, **kw) if (m is not None) and (len(m) == len(x)): paths = [] for marker in m: if isinstance(marker, mmarkers.MarkerStyle): marker_obj = marker else: marker_obj = mmarkers.MarkerStyle(marker) path = marker_obj.get_path().transformed( marker_obj.get_transform()) paths.append(path) sc.set_paths(paths) return sc def datasets(): """ 使用datasets包产生一些数据 :return: """ plt.rcParams['axes.unicode_minus'] = False#解决不显示负数问题 X,y_true = make_blobs(n_samples=400,centers=3,random_state=1000)
#random_state=1000效果也不错
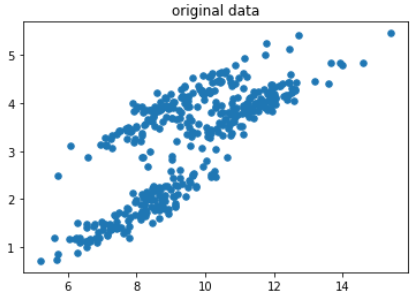
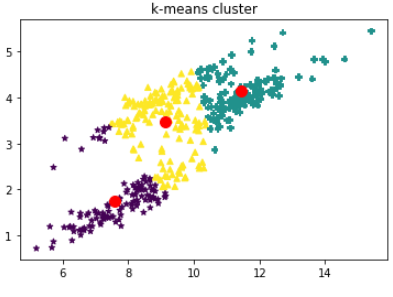
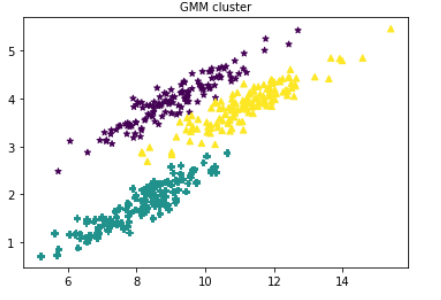
rng = np.random.RandomState(70) Y = np.dot(X,rng.randn(2,2)) plt.scatter(Y[:,0],Y[:,1],s=30) plt.title("original data") plt.show() return X,Y def GmmKmean(data,dataY): """ GMM算法与Kmeans算法对比 :return: """ kmeansy = KMeans(n_clusters=3,random_state=1) kmeansy.fit(dataY) datay_kmeans = kmeansy.predict(dataY) # 可视化 # print(datay_kmeans[0]) map_marker = {0: '*', 1: 'P', 2: '^'} markers = list(map(lambda x: map_marker[x], datay_kmeans)) centers = kmeansy.cluster_centers_ # print(centers) mscatter(dataY[:,0],dataY[:,1],c=datay_kmeans,s=30,m=markers,cmap='viridis') plt.scatter(centers[:,0],centers[:,1],c="red",s=100) plt.title("k-means cluster") plt.show() # gmmY = GaussianMixture(n_components=4) gmm = GaussianMixture(n_components=3,random_state=10) gmm.fit(dataY) labelsY = gmm.predict(dataY) # print(labelsY) map_marker = {0: '*', 1: 'P', 2: '^'} markersG = list(map(lambda x: map_marker[x],labelsY)) mscatter(dataY[:,0],dataY[:,1],c=labelsY,s=30,m=markersG,cmap='viridis') plt.title("GMM cluster",fontproperties="SimHei") plt.show() return None if __name__ == "__main__": data,dataY = datasets() GmmKmean(data,dataY) # draw(KMeans(n_clusters=3).fit(dataY))
运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号