java爬虫(二)利用HttpClient和Jsoup库实现简单的Java爬虫程序
jsoup官方文档:https://www.open-open.com/jsoup/parsing-a-document.htm
一、jsoup简介
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
文档内容可知道,获取数据源的方法有三种:
(1)从一段html代码字符串获取: Document doc = Jsoup.parse(html);
(2)从一个url获取: Document doc = Jsoup.connect(url).get();
(3)从一个html文件获取 File input = new File("XXX.html"); 或Document doc = Jsoup.parse(input, "UTF-8", url);
二、编码实践
0.导入jsoup.jar资源包
1.获取页面全部代码
每一个页面都有相关的前端内容,我们这里就是先分析相关页面的内容,然后根据标签来进行分别分类获取,然后利用java的其余技术来处理你获取的内容。
首先最基本的,获取页面的全部代码,包含HTML,CSS等内容,这里也以网络盗版小说网站为例子,进行相关的爬虫。
package pachong; import java.io.IOException; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; public class test{ //第一个,完整爬虫爬下来内容 public static void get_html(String url){ try { Document doc = Jsoup.connect(url).get(); System.out.println(doc); } catch (IOException e) { e.printStackTrace(); } } public static void main(String[] args) { String url = "http://news.tjut.edu.cn/yw.htm"; get_html(url); } }
运行结果如下
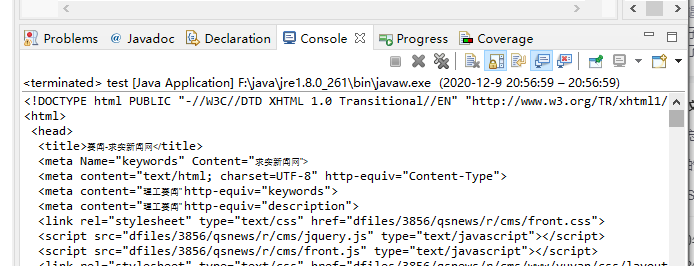
2.用相关class、id、tag的方法解析我们需要的数据
方法总结:
①
②
③
package debug; import java.io.IOException; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class test { //第一个,完整爬虫爬下来内容 public static void get_html(String url){ try { Document doc = Jsoup.connect(url).get(); //得到html中id为content下的所有内容 Element ele = doc.getElementById("line52564_20"); //分离出下面的具体内容 Elements tag = ele.getElementsByTag("td"); System.out.println(tag); } catch (IOException e) { e.printStackTrace(); } } public static void main(String[] args) { // String url = "http://www.biquge5200.com/78_78387/149957687.html"; String url = "http://news.tjut.edu.cn/yw.htm"; get_html(url); } }
输入如下:

3.通过io操作获取到某个具体的值
本事例想要获取的是新闻网站中新闻的总条数
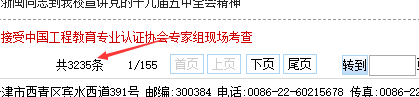
代码如下
package debug; import java.io.IOException; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class test { // 实现切割某两个字之间的字符串 public static String findstr(String str1,String strstrat,String strend ) { String finalstr=new String(); int strStartIndex = str1.indexOf(strstrat); int strEndIndex = str1.indexOf(strend); finalstr = str1.substring(strStartIndex, strEndIndex).substring(strstrat.length()); return finalstr; } //第一个,完整爬虫爬下来内容 public static void get_html(String url){ try { Document doc = Jsoup.connect(url).get(); //得到html中id为content下的所有内容 Element ele = doc.getElementById("fanye52564"); //分离出下面的具体内容 Elements tag = ele.getElementsByTag("td"); for(Element e : tag) { String title = e.getElementsByTag("td").text(); String Totals=findstr(title,"共","条"); System.out.println(Totals); } } catch (IOException e) { e.printStackTrace(); } } public static void main(String[] args) { String url = "http://news.tjut.edu.cn/yw.htm"; get_html(url); } } //参考文献https://blog.csdn.net/suqi356/article/details/78547137?depth_1- //https://www.cnblogs.com/carlo/p/4717947.html
运行结果如下:
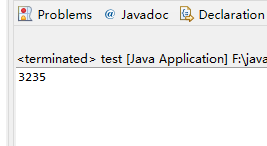
接口文档(https://jsoup.org/apidocs/overview-summary.html)也能搜到。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
文档内容可知道,获取数据源的方法有三种:
(1)从一段html代码字符串获取: Document doc = Jsoup.parse(html);
(2)从一个url获取: Document doc = Jsoup.connect(url).get();
(3)从一个html文件获取 File input = new File("XXX.html"); 或Document doc = Jsoup.parse(input, "UTF-8", url);
废话不说,进入正文。
每一个页面都有相关的前端内容,我们这里就是先分析相关页面的内容,然后根据标签来进行分别分类获取,然后利用java的其余技术来处理你获取的内容。
首先最基本的,获取页面的全部代码,包含HTML,CSS等内容,这里也以网络盗版小说网站为例子,进行相关的爬虫。
输出的结果如下:

因为consle不能全部截图,我就截图了一部分,从这里就能看到完整的前端内容。
而我们只需要里面的小说内容,而对于什么样式,脚本等等之类的东西并不是我们需要的,于是我们先找到小说正文内容,根据正文内容来处理。

我们分析正文内容发现,正文内容全部是被一组id为content的div包含的,对于其他内容,我们并不需要,只需要id为content的div内容里的数据,于是我们能不能只要这里面的东西的。
而查询jsoup,我们发现确实是有相关获取class,id,tag的方法的,可以利用这些发现来获取我们需要的数据,于是第二个例子就出现了。
他的输出结果如下图:

我们发现最基本的内容我们已经拿到,现在就是需要对立面的内容来简单的处理一下。这就很简单了,转换成字符串类型的,利用字符串的相关方法来处理这个。
如果我们要导出来保存本地,就可以利用java的io来处理相关数据并保存。
那上面只是简单的一篇小说,如果我们想把全本小说全部下载到我们的电脑里并保存下来,那又如何处理呢?
我们先看看整个目录的小说里对前端内容的分析,我们发现,其实每个章节的内容都在一个id为list的div下,那面根据上面的经验来说,我们就拿list来获取。
然后获取到后,我们根据超链接标签a来遍历,获取到数据后,在循环里打开页面,然后爬虫下载下来就可以了。
这里有几个地方解释:
1.先说.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)").timeout(999999999)
.userAgent表示是模拟自己是浏览器访问,防止反爬虫网站对爬虫程序的禁止访问;
.timeout(999999999)个人理解是延时访问,也是防止反爬虫网站对爬虫程序的禁止访问;
2.为何循环从9开始,而不是从0或者1开始呢?
因为我们看小说章节目录发现,前面九章是最新更新的九章,而这九章我们并不需要,因为我们后面的循环可以抓到最后的九章,所以从9开始,或者在循环结束那减去9也可以的。因人而异。
3.为何要写个Thread.currentThread().sleep(5000);来对循环睡眠:
因为你频繁访问,哪怕你伪装成浏览器,还是会对服务器性能等方面造成影响,服务器会对这种连接拒绝,而睡眠线程,这样的话,就模拟一个人正在浏览小说,5秒看完一篇小说是比较很正常的,这样,你才能把上百上千的小说下载下来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号