

python的pandas处理txt文件
使用pandas实现sql中主要的方法
1.对行、列、元素增删改查
2.数据筛选:loc函数配合条件完成
①与& 或|
②> < == >= <= !=
data1.loc[(data1['userID']!=0)&(data1['location-id']<=10000)]
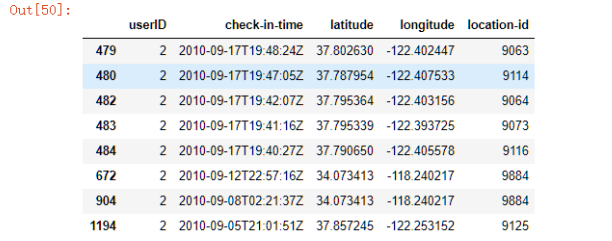
比较运算符、逻辑运算符、模糊查询、空判断
3.分组group by
使用where完成分组
4.排序sort_values
①对某一列DataFrame排序
DataFrame.sort_values(by='location-id')
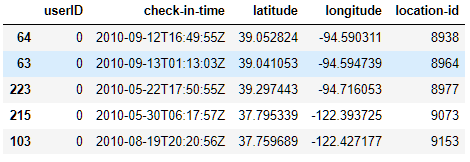
②按照多列进行排序(当第一个因素相等时,按照第二个因素排序)
df.sort_values(by=['userID','check-in-time'],ascending=[True,True])

import pandas as pd
import numpy as np
#以下实现排序功能。
series=pd.Series([3,4,1,6],index=['b','a','d','c'])
frame=pd.DataFrame([[2,4,1,5],[3,1,4,5],[5,1,4,2]],columns=['b','a','d','c'],index=['one','two','three'])
print frame
print series
print 'series通过索引进行排序:'
print series.sort_index()
print 'series通过值进行排序:'
print series.sort_values()
print 'dataframe根据行索引进行降序排序(排序时默认升序,调节ascending参数):'
print frame.sort_index(ascending=False)
print 'dataframe根据列索引进行排序:'
print frame.sort_index(axis=1)
print 'dataframe根据值进行排序:'
print frame.sort_values(by='a')
print '通过多个索引进行排序:'
print frame.sort_values(by=['a','c'])
5.获取部分行limit star,count
6.聚合:count、max、min、avg、sum
pandas中常见统计函数
| 函数名 | 功能 |
|---|---|
| count() | 统计个数(NaN不算) |
| describe() | 一次性输出多个指标:count,mean,std,min,max |
| min() max() sum() mean() | 最小最大求和平均值 |
| media() | 中位数 |
| var() | 方差 |
| std() | 标准差 |
| argmin() | 统计最小值的索引位置 |
| argmax() | 统计最大值的索引位置 |
| idmax() | 统计最大值的索引值 |
7.数据表的合并
merge函数
8.数据提取
loc,iloc和ix函数
二、pandas读写文件
1.pandas读取txt数据
import pandas as pd
data1=pd.read_csv('Gowalla_minitestCheckins.txt', sep='\t', names=['userID','check-in-time','latitude', 'longitude', 'location-id'])
data1.to_csv('Gowalla_minitestCheckins.csv') print(data1[0:10]) #显示前10行
# data.to_excel('240.xlsx') 将数据保存为excle格式
#data.to
sep="\t"是原始文档间的空格每一个文档可能都不一样,可能有空格,逗号或者是\n,根据情况选择names用来设置列名,如果不设置的话,则默认使用第一列作为列名。
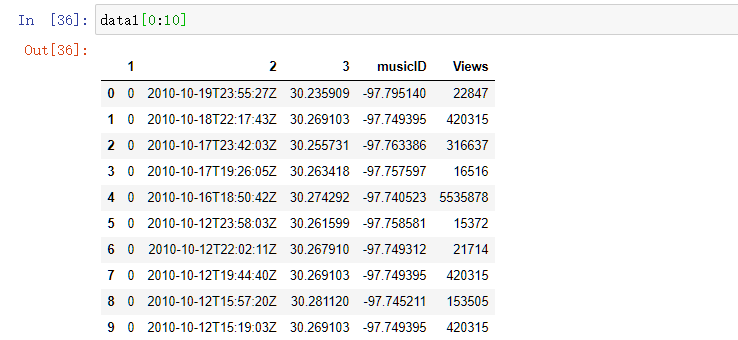
2.
data[data['views'].isin([1])]

3 分组(统计汇总)
“group by” 指的是涵盖下列一项或多项步骤的处理流程:
-
分割:按条件把数据分割成多组;
-
应用:为每组单独应用函数;
-
组合:将处理结果组合成一个数据结构
data.groupby('musicID').sum()#按照音乐分组,统计每首歌的总播放量
data.groupby('musicID').count()#按照音乐分组,统计每首歌出现在数据中的总条数
三、数据表的检查
1.数据维度
df.shape

2.数据表信息
df.info()
3.查看数据格式
df.dtypes
4.查看空值
df.isnull()
5.查看唯一值(某一列中不重复的内容)
df['city'].unique()
注意:去除dataframe中重复的内容 dataframe.drop_duplicates()
6.查看数据表数值
df.values
7.查看列名称
df.columns
8.查看某一列(对应的series形式)
df['要查看的列名']
9.查看前10行 后10行
DataFrame添加元素和字典的操作类似(待整理)
datas = { '排名': [1, 2, 3, 4, 5], '综合得分': [894, 603, 589, 570, 569], '粉丝数': [309147, 93704, 98757, 124712, 59847], '获赞数': [12200, 31637, 4987, 1736, 8996]} df = pd.DataFrame(datas) df["新列名"]=list1或多多维数组 #需要注意维度需要与df长度相同的问题
四、数据可视化
1.pandas用plt简单绘图(文章中的代码没有换行,import,plt等之前需要换行)
https://blog.csdn.net/weixin_28568819/article/details/112359154
参考文献
1.pandas官方文档
https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html
2.
