
机器学习——人脸识别判断表情
一、选题背景
随着机器学习和深度神经网络两个领域的迅速发展以及智能设备的普及,人脸识别技术正在经历前所未有的发展,关于人脸识别技术讨论从未停歇。目前,人脸识别精度已经超过人眼,同时大规模普及的软硬件基础条件也已具备,应用市场和领域需求很大,基于这项技术的市场发展和具体应用正呈现蓬勃发展态势。
人脸表情识别作为人脸识别技术中的一个重要组成部分,近年来在人机交互、安全、机器人制造、自动化、医疗、通信和驾驶领域得到了广泛的关注,成为学术界和工业界的研究热点。
二、机器学习案例设计方案
数据来源:
本案例中涉及的数据集来源于 INC 网站 ,案例用keras框架对人脸面部图像进行的笑脸识别。
数据集包括4000张不同大小的像素的面部图像,通过人脸识别68个特征点检测数据库(shape_predictor_68_face_landmarks.dat)进一步确定人脸大小,将具有笑脸特征的图像转化为150×150像素保存在一个文件夹内。
使用用keras,搭建模型,训练模型,输出模型训练次数的精度变化, 导入图片测试模型。
三、机器学习的实现步骤
1.下载数据集
2.导入需要用到的库

1 import dlib # 人脸识别的库dlib 2 import numpy as np # 数据处理的库numpy 3 import cv2 # 图像处理的库OpenCv 4 import os 5 from keras import layers 6 from keras import models 7 from keras import optimizers 8 from keras.preprocessing.image import ImageDataGenerator 9 import matplotlib.pyplot as plt 10 from keras.utils import image_utils
3.对图片进行人脸识别,并截取人脸部分输出150*150像素图像。
1 import dlib # 人脸识别的库dlib 2 import numpy as np # 数据处理的库numpy 3 import cv2 # 图像处理的库OpenCv 4 import os 5 6 # dlib预测器 7 detector = dlib.get_frontal_face_detector() 8 predictor = dlib.shape_predictor('E:\\smiletest\\shape_predictor_68_face_landmarks.dat') 9 10 # 读取图像的路径 11 path_read = "E:\\smiletest\\files" 12 num = 0 13 for file_name in os.listdir(path_read): 14 # aa是图片的全路径 15 aa = (path_read + "/" + file_name) 16 # 读入的图片的路径中含非英文 17 img = cv2.imdecode(np.fromfile(aa, dtype=np.uint8), cv2.IMREAD_UNCHANGED) 18 # 获取图片的宽高 19 img_shape = img.shape 20 img_height = img_shape[0] 21 img_width = img_shape[1] 22 23 # 用来存储生成的单张人脸的路径 24 path_save = "E:\\smiletest\\files1" 25 # dlib检测 26 dets = detector(img, 1) 27 print("人脸数:", len(dets)) 28 for k, d in enumerate(dets): 29 if len(dets) > 1: 30 continue 31 num = num + 1 32 # 计算矩形大小 33 # (x,y), (宽度width, 高度height) 34 pos_start = tuple([d.left(), d.top()]) 35 pos_end = tuple([d.right(), d.bottom()]) 36 37 # 计算矩形框大小 38 height = d.bottom() - d.top() 39 width = d.right() - d.left() 40 41 # 根据人脸大小生成空的图像 42 img_blank = np.zeros((height, width, 3), np.uint8) 43 for i in range(height): 44 if d.top() + i >= img_height: # 防止越界 45 continue 46 for j in range(width): 47 if d.left() + j >= img_width: # 防止越界 48 continue 49 img_blank[i][j] = img[d.top() + i][d.left() + j] 50 img_blank = cv2.resize(img_blank, (200, 200), interpolation=cv2.INTER_CUBIC) 51 52 cv2.imencode('.jpg', img_blank)[1].tofile(path_save + "\\" + "file" + str(num) + ".jpg")

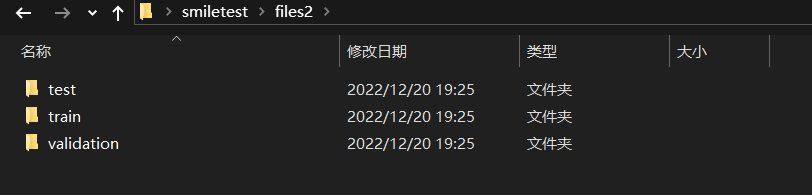
4.导入数据集路径,对数据集进行分类。
1 import os, shutil 2 3 # 原始数据集路径 4 original_dataset_dir = 'E:\\smiletest\\files1' 5 6 # 新的数据集 7 base_dir = 'E:\\smiletest\\files2'\ 8 # 创建文件夹 9 os.mkdir(base_dir) 10 11 # 训练图像、验证图像、测试图像的目录 12 train_dir = os.path.join(base_dir, 'train') 13 os.mkdir(train_dir) 14 validation_dir = os.path.join(base_dir, 'validation') 15 os.mkdir(validation_dir) 16 test_dir = os.path.join(base_dir, 'test') 17 os.mkdir(test_dir) 18 19 train_smiles_dir = os.path.join(train_dir, 'smile') 20 os.mkdir(train_smiles_dir) 21 22 train_unsmiles_dir = os.path.join(train_dir, 'unsmile') 23 os.mkdir(train_unsmiles_dir) 24 25 validation_smiles_dir = os.path.join(validation_dir, 'smile') 26 os.mkdir(validation_smiles_dir) 27 28 validation_unsmiles_dir = os.path.join(validation_dir, 'unsmile') 29 os.mkdir(validation_unsmiles_dir) 30 31 test_smiles_dir = os.path.join(test_dir, 'smile') 32 os.mkdir(test_smiles_dir) 33 34 test_unsmiles_dir = os.path.join(test_dir, 'unsmile') 35 os.mkdir(test_unsmiles_dir) 36 37 # 复制900张笑脸图片到train_smiles_dir 38 fnames = ['file{}.jpg'.format(i) for i in range(1, 900)] 39 for fname in fnames: 40 src = os.path.join(original_dataset_dir, fname) 41 dst = os.path.join(train_smiles_dir, fname) 42 shutil.copyfile(src, dst) 43 # 复制450张笑脸图片到validation_smiles_dir 44 fnames = ['file{}.jpg'.format(i) for i in range(900, 1350)] 45 for fname in fnames: 46 src = os.path.join(original_dataset_dir, fname) 47 dst = os.path.join(validation_smiles_dir, fname) 48 shutil.copyfile(src, dst) 49 50 # 复制450张笑脸图片到test_smiles_dir 51 fnames = ['file{}.jpg'.format(i) for i in range(1350, 1800)] 52 for fname in fnames: 53 src = os.path.join(original_dataset_dir, fname) 54 dst = os.path.join(test_smiles_dir, fname) 55 shutil.copyfile(src, dst) 56 57 # 复制873张笑脸图片到train_unsmiles_dir 58 fnames = ['file{}.jpg'.format(i) for i in range(2127, 3000)] 59 for fname in fnames: 60 src = os.path.join(original_dataset_dir, fname) 61 dst = os.path.join(train_unsmiles_dir, fname) 62 shutil.copyfile(src, dst) 63 64 # 复制878张笑脸图片到validation_unsmiles_dir 65 fnames = ['file{}.jpg'.format(i) for i in range(3000, 3878)] 66 for fname in fnames: 67 src = os.path.join(original_dataset_dir, fname) 68 dst = os.path.join(validation_unsmiles_dir, fname) 69 shutil.copyfile(src, dst)
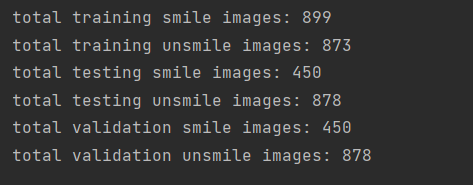
5.输出分类后的数据集图片数量
1 print('total training smile images:', len(os.listdir(train_smiles_dir))) 2 print('total training unsmile images:', len(os.listdir(train_unsmiles_dir))) 3 print('total testing smile images:', len(os.listdir(test_smiles_dir))) 4 print('total testing unsmile images:', len(os.listdir(test_unsmiles_dir))) 5 print('total validation smile images:', len(os.listdir(validation_smiles_dir))) 6 print('total validation unsmile images:', len(os.listdir(validation_unsmiles_dir)))
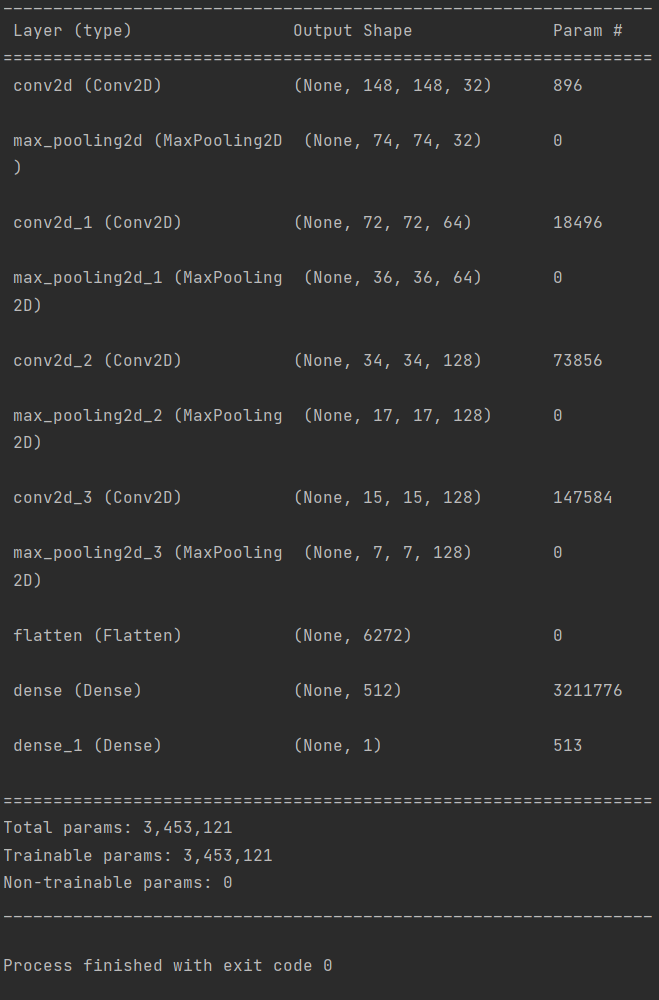
6.数据集分类完成后,搭建卷积网络。
1 from keras import layers 2 from keras import models 3 #创建模型 4 model = models.Sequential() 5 #第一个卷积层作为输入层,32个3*3卷积核 6 #输出尺寸:150-3+1=148*148,参数数量:32*3*3*3+32=896 7 model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3))) 8 model.add(layers.MaxPooling2D((2, 2))) 9 #输出尺寸:74-3+1=72*72,对应数量:64*3*3*32+64=18496 10 model.add(layers.Conv2D(64, (3, 3), activation='relu')) 11 model.add(layers.MaxPooling2D((2, 2))) 12 #输出尺寸:36-3+1=34*34,对应数量:128*3*3*64+128=73856 13 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 14 model.add(layers.MaxPooling2D((2, 2))) 15 #输出尺寸:17-3+1=15*15,对应数量:128*3*3*128+128=147584 16 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 17 model.add(layers.MaxPooling2D((2, 2))) 18 model.add(layers.Flatten()) 19 model.add(layers.Dense(512, activation='relu')) 20 model.add(layers.Dense(1, activation='sigmoid')) 21 model.summary()#查看标量信息
7.将所有图片统一化
1 from keras import layers 2 from keras import models 3 from keras import optimizers 4 #统一化 5 model.compile(loss='binary_crossentropy', 6 optimizer=optimizers.RMSprop(lr=1e-4), 7 metrics=['acc']) 8 train_datagen = ImageDataGenerator(rescale=1./255) 9 validation_datagen=ImageDataGenerator(rescale=1./255) 10 test_datagen = ImageDataGenerator(rescale=1./255) 11 train_generator = train_datagen.flow_from_directory( 12 # 目标文件目录 13 train_dir, 14 #所有图片的size必须是150x150 15 target_size=(150, 150), 16 batch_size=20, 17 class_mode='binary') 18 validation_generator = test_datagen.flow_from_directory( 19 validation_dir, 20 target_size=(150, 150), 21 batch_size=20, 22 class_mode='binary') 23 test_generator = test_datagen.flow_from_directory(test_dir, 24 target_size=(150, 150), 25 batch_size=20, 26 class_mode='binary') 27 for data_batch, labels_batch in train_generator: 28 print('data batch shape:', data_batch.shape) 29 print('labels batch shape:', labels_batch) 30 break

‘微笑’:0,‘非微笑’:1
8.对图像进行预处理(数据增强)
1 from keras import layers 2 from keras import models 3 from keras import optimizers 4 from keras.preprocessing.image import ImageDataGenerator 5 import os, shutil 6 #数据增强 7 datagen = ImageDataGenerator( 8 rotation_range=40, 9 width_shift_range=0.2, 10 height_shift_range=0.2, 11 shear_range=0.2, 12 zoom_range=0.2, 13 horizontal_flip=True, 14 fill_mode='nearest') 15 #数据增强后图片变化 16 import matplotlib.pyplot as plt 17 # from keras.preprocessing import image 18 from keras.utils import image_utils 19 train_smile_dir='E:\\smiletest\\files2\\train\\smile' 20 fnames = [os.path.join(train_smile_dir, fname) for fname in os.listdir(train_smile_dir)] 21 img_path = fnames[3] 22 img = image_utils.load_img(img_path, target_size=(150, 150)) 23 x = image_utils.img_to_array(img) 24 x = x.reshape((1,) + x.shape) 25 i = 0 26 for batch in datagen.flow(x, batch_size=1): 27 plt.figure(i) 28 imgplot = plt.imshow(image_utils.array_to_img(batch[0])) 29 i += 1 30 if i % 4 == 0: 31 break 32 plt.show()

9.训练卷积神经网络
1 from keras import layers 2 from keras import models 3 from keras import optimizers 4 import matplotlib.pyplot as plt 5 #创建网络 6 from keras.preprocessing.image import ImageDataGenerator 7 8 model = models.Sequential() 9 model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3))) 10 model.add(layers.MaxPooling2D((2, 2))) 11 model.add(layers.Conv2D(64, (3, 3), activation='relu')) 12 model.add(layers.MaxPooling2D((2, 2))) 13 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 14 model.add(layers.MaxPooling2D((2, 2))) 15 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 16 model.add(layers.MaxPooling2D((2, 2))) 17 model.add(layers.Flatten()) 18 model.add(layers.Dropout(0.5)) 19 model.add(layers.Dense(512, activation='relu')) 20 model.add(layers.Dense(1, activation='sigmoid')) 21 model.compile(loss='binary_crossentropy', 22 optimizer=optimizers.RMSprop(lr=1e-4), 23 metrics=['acc']) 24 25 #统一化处理 26 train_datagen = ImageDataGenerator( 27 rescale=1./255, 28 rotation_range=40, 29 width_shift_range=0.2, 30 height_shift_range=0.2, 31 shear_range=0.2, 32 zoom_range=0.2, 33 horizontal_flip=True,) 34 35 test_datagen = ImageDataGenerator(rescale=1./255) 36 train_dir = 'E:\\smiletest\\files2\\train' 37 validation_dir='E:\\smiletest\\files2\\validation' 38 train_generator = train_datagen.flow_from_directory( 39 # This is the target directory 40 train_dir, 41 # All images will be resized to 150x150 42 target_size=(150, 150), 43 batch_size=32, 44 # Since we use binary_crossentropy loss, we need binary labels 45 class_mode='binary') 46 47 validation_generator = test_datagen.flow_from_directory( 48 validation_dir, 49 target_size=(150, 150), 50 batch_size=32, 51 class_mode='binary') 52 53 history = model.fit_generator( 54 train_generator, 55 steps_per_epoch=55, 56 epochs=60, 57 validation_data=validation_generator, 58 validation_steps=27)
10.保存训练模型
1 model.save('E:\\smiletest\\smileAndunsmile1.h5')

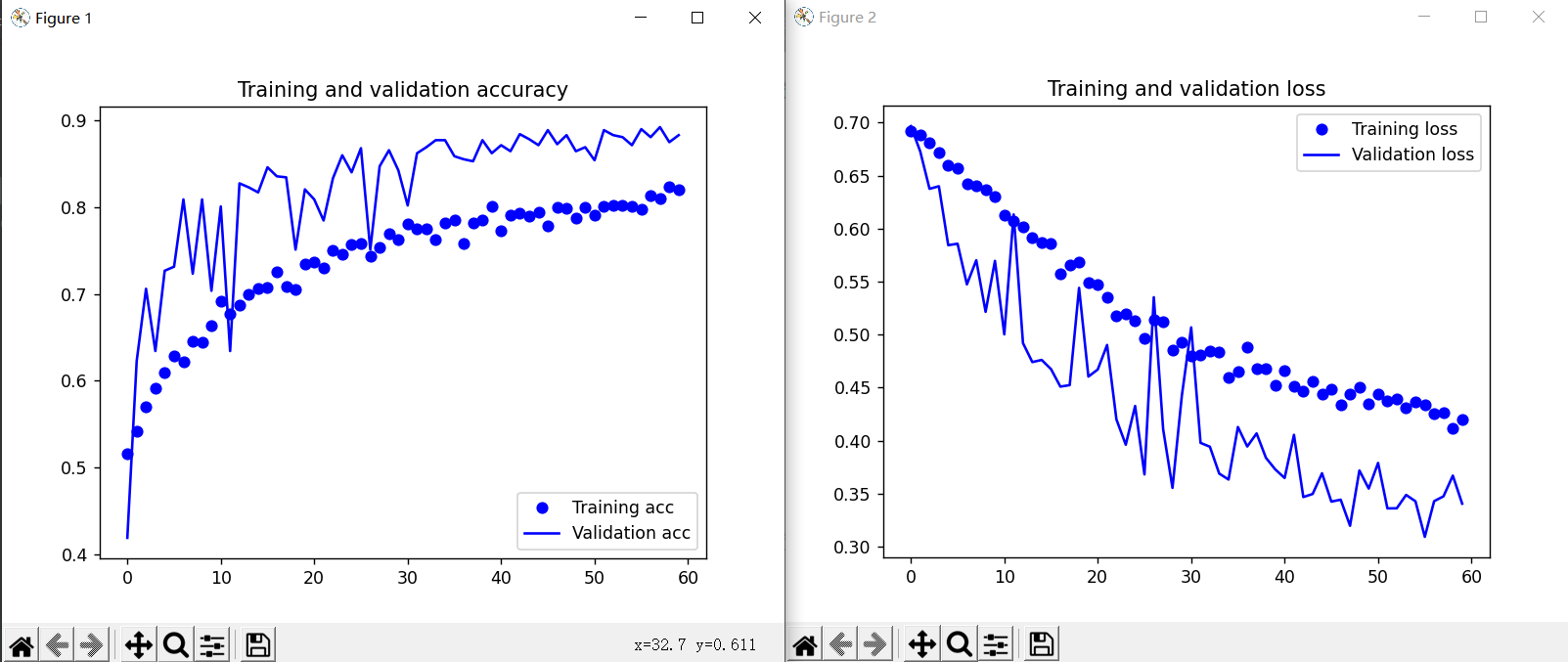
11.输出精度与损失曲线图和散点图
1 import matplotlib.pyplot as plt 2 #数据增强过后的训练集与验证集的精确度与损失度的图形 3 acc = history.history['acc'] 4 val_acc = history.history['val_acc'] 5 loss = history.history['loss'] 6 val_loss = history.history['val_loss'] 7 8 epochs = range(len(acc)) 9 # 输出精度度曲线图与散点图 10 plt.plot(epochs, acc, 'bo', label='Training acc') 11 plt.plot(epochs, val_acc, 'b', label='Validation acc') 12 plt.title('Training and validation accuracy') 13 plt.legend() 14 plt.figure() 15 # 输出损失曲线图与散点图 16 plt.plot(epochs, loss, 'bo', label='Training loss') 17 plt.plot(epochs, val_loss, 'b', label='Validation loss') 18 plt.title('Training and validation loss') 19 plt.legend() 20 plt.show()
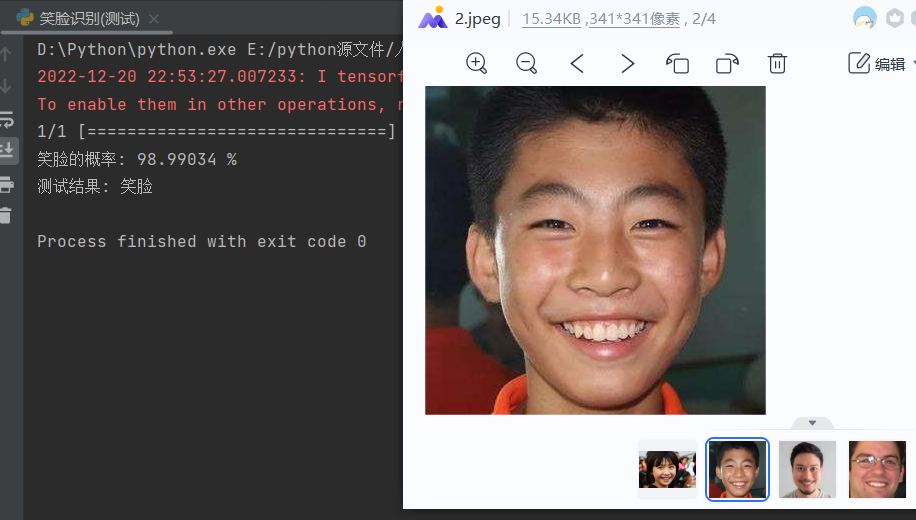
12.使用训练模型对单张图片进行判断是否微笑。
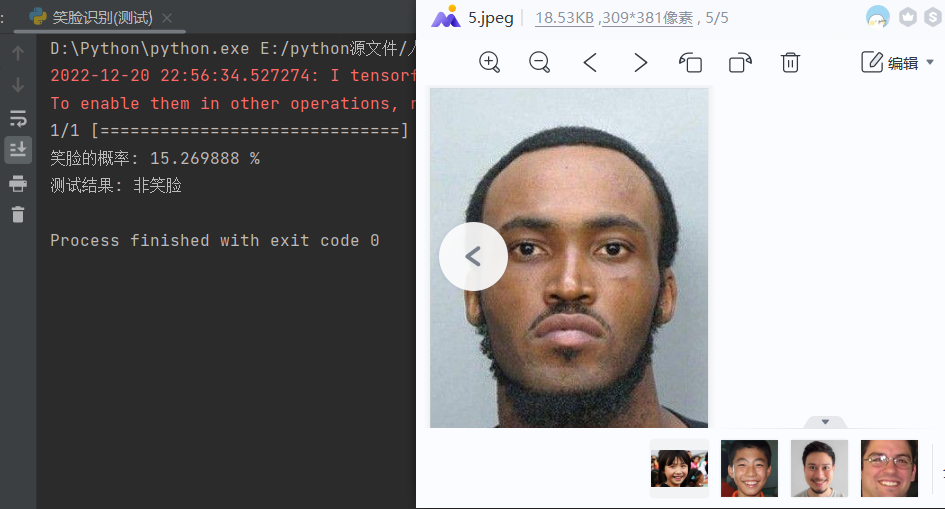
1 # import cv2 2 # from keras.preprocessing import image 3 from keras.utils import image_utils 4 from keras.models import load_model 5 import numpy as np 6 # 单张图片进行判断是笑脸还是非笑脸 7 # 加载模型 8 model = load_model('E:\\smiletest\\smileAndunsmile1.h5') 9 # 本地图片路径 10 img_path = 'E:\\smiletest\\testimg\\2.jpeg' 11 img = image_utils.load_img(img_path, target_size=(150, 150)) 12 13 img_tensor = image_utils.img_to_array(img) / 255.0 14 img_tensor = np.expand_dims(img_tensor, axis=0) 15 prediction = model.predict(img_tensor) 16 prediction1=str((1-prediction)*100).strip('[]') 17 # (1-prediction1)*100 18 print('笑脸的概率:',prediction1,'%') 19 if prediction[0][0] > 0.5: 20 result = '非笑脸' 21 else: 22 result = '笑脸' 23 print('测试结果:',result)
笑脸
非笑脸
四、总结
在现代化社会工作学习给年轻人带来了诸多压力与困扰,笑容逐渐从脸上丢失,这是社会进步不得已的现如今人人都为学历、金钱、权利而奋斗,在内卷的过程中不知自己脸上那份可爱的笑容在不知不觉的消失了。此次项目识别人脸是否微笑是对社会幸福度的某一角度的贡献,可以通过人们时常微笑进而得出城市幸福度。
通过学习人脸微笑识别的制作,大致了解了机器学习相关概念,整个过程让我感觉到机器学习的学习困难与逻辑思维上相比其他语言有着许多的不同,经过自己滚打摸爬解决了许多问题,遇到问题少有代码文档给予我理解与渗透。
最后感谢老师的悉心栽培。
附完整代码
1 import dlib # 人脸识别的库dlib 2 import numpy as np # 数据处理的库numpy 3 import cv2 # 图像处理的库OpenCv 4 import os 5 6 # dlib预测器 7 detector = dlib.get_frontal_face_detector() 8 predictor = dlib.shape_predictor('E:\\smiletest\\shape_predictor_68_face_landmarks.dat') 9 10 # 读取图像的路径 11 path_read = "E:\\smiletest\\files" 12 num = 0 13 for file_name in os.listdir(path_read): 14 # aa是图片的全路径 15 aa = (path_read + "/" + file_name) 16 # 读入的图片的路径中含非英文 17 img = cv2.imdecode(np.fromfile(aa, dtype=np.uint8), cv2.IMREAD_UNCHANGED) 18 # 获取图片的宽高 19 img_shape = img.shape 20 img_height = img_shape[0] 21 img_width = img_shape[1] 22 23 # 用来存储生成的单张人脸的路径 24 path_save = "E:\\smiletest\\files1" 25 # dlib检测 26 dets = detector(img, 1) 27 print("人脸数:", len(dets)) 28 for k, d in enumerate(dets): 29 if len(dets) > 1: 30 continue 31 num = num + 1 32 # 计算矩形大小 33 # (x,y), (宽度width, 高度height) 34 pos_start = tuple([d.left(), d.top()]) 35 pos_end = tuple([d.right(), d.bottom()]) 36 37 # 计算矩形框大小 38 height = d.bottom() - d.top() 39 width = d.right() - d.left() 40 41 # 根据人脸大小生成空的图像 42 img_blank = np.zeros((height, width, 3), np.uint8) 43 for i in range(height): 44 if d.top() + i >= img_height: # 防止越界 45 continue 46 for j in range(width): 47 if d.left() + j >= img_width: # 防止越界 48 continue 49 img_blank[i][j] = img[d.top() + i][d.left() + j] 50 img_blank = cv2.resize(img_blank, (200, 200), interpolation=cv2.INTER_CUBIC) 51 52 cv2.imencode('.jpg', img_blank)[1].tofile(path_save + "\\" + "file" + str(num) + ".jpg") 53 54 from keras import layers 55 from keras import models 56 from keras import optimizers 57 from keras.preprocessing.image import ImageDataGenerator 58 import os, shutil 59 60 # 原始数据集路径 61 original_dataset_dir = 'E:\\smiletest\\files1' 62 63 # 新的数据集 64 base_dir = 'E:\\smiletest\\files2'\ 65 # 创建文件夹 66 os.mkdir(base_dir) 67 68 # 训练图像、验证图像、测试图像的目录 69 train_dir = os.path.join(base_dir, 'train') 70 os.mkdir(train_dir) 71 validation_dir = os.path.join(base_dir, 'validation') 72 os.mkdir(validation_dir) 73 test_dir = os.path.join(base_dir, 'test') 74 os.mkdir(test_dir) 75 76 train_smiles_dir = os.path.join(train_dir, 'smile') 77 os.mkdir(train_smiles_dir) 78 79 train_unsmiles_dir = os.path.join(train_dir, 'unsmile') 80 os.mkdir(train_unsmiles_dir) 81 82 validation_smiles_dir = os.path.join(validation_dir, 'smile') 83 os.mkdir(validation_smiles_dir) 84 85 validation_unsmiles_dir = os.path.join(validation_dir, 'unsmile') 86 os.mkdir(validation_unsmiles_dir) 87 88 test_smiles_dir = os.path.join(test_dir, 'smile') 89 os.mkdir(test_smiles_dir) 90 91 test_unsmiles_dir = os.path.join(test_dir, 'unsmile') 92 os.mkdir(test_unsmiles_dir) 93 94 # 复制900张笑脸图片到train_smiles_dir 95 fnames = ['file{}.jpg'.format(i) for i in range(1, 900)] 96 for fname in fnames: 97 src = os.path.join(original_dataset_dir, fname) 98 dst = os.path.join(train_smiles_dir, fname) 99 shutil.copyfile(src, dst) 100 # 复制450张笑脸图片到validation_smiles_dir 101 fnames = ['file{}.jpg'.format(i) for i in range(900, 1350)] 102 for fname in fnames: 103 src = os.path.join(original_dataset_dir, fname) 104 dst = os.path.join(validation_smiles_dir, fname) 105 shutil.copyfile(src, dst) 106 107 # 复制450张笑脸图片到test_smiles_dir 108 fnames = ['file{}.jpg'.format(i) for i in range(1350, 1800)] 109 for fname in fnames: 110 src = os.path.join(original_dataset_dir, fname) 111 dst = os.path.join(test_smiles_dir, fname) 112 shutil.copyfile(src, dst) 113 114 # 复制873张笑脸图片到train_unsmiles_dir 115 fnames = ['file{}.jpg'.format(i) for i in range(2127, 3000)] 116 for fname in fnames: 117 src = os.path.join(original_dataset_dir, fname) 118 dst = os.path.join(train_unsmiles_dir, fname) 119 shutil.copyfile(src, dst) 120 121 # 复制878张笑脸图片到validation_unsmiles_dir 122 fnames = ['file{}.jpg'.format(i) for i in range(3000, 3878)] 123 for fname in fnames: 124 src = os.path.join(original_dataset_dir, fname) 125 dst = os.path.join(validation_unsmiles_dir, fname) 126 shutil.copyfile(src, dst) 127 128 # 复制878张笑脸图片到test_unsmiles_dir 129 fnames = ['file{}.jpg'.format(i) for i in range(3000, 3878)] 130 for fname in fnames: 131 src = os.path.join(original_dataset_dir, fname) 132 dst = os.path.join(test_unsmiles_dir, fname) 133 shutil.copyfile(src, dst) 134 135 print('total training smile images:', len(os.listdir(train_smiles_dir))) 136 print('total training unsmile images:', len(os.listdir(train_unsmiles_dir))) 137 print('total testing smile images:', len(os.listdir(test_smiles_dir))) 138 print('total testing unsmile images:', len(os.listdir(test_unsmiles_dir))) 139 print('total validation smile images:', len(os.listdir(validation_smiles_dir))) 140 print('total validation unsmile images:', len(os.listdir(validation_unsmiles_dir))) 141 142 143 #创建模型 144 model = models.Sequential() 145 #第一个卷积层作为输入层,32个3*3卷积核 146 #输出尺寸:150-3+1=148*148,参数数量:32*3*3*3+32=896 147 model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3))) 148 model.add(layers.MaxPooling2D((2, 2))) 149 #输出尺寸:74-3+1=72*72,对应数量:64*3*3*32+64=18496 150 model.add(layers.Conv2D(64, (3, 3), activation='relu')) 151 model.add(layers.MaxPooling2D((2, 2))) 152 #输出尺寸:36-3+1=34*34,对应数量:128*3*3*64+128=73856 153 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 154 model.add(layers.MaxPooling2D((2, 2))) 155 #输出尺寸:17-3+1=15*15,对应数量:128*3*3*128+128=147584 156 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 157 model.add(layers.MaxPooling2D((2, 2))) 158 model.add(layers.Flatten()) 159 model.add(layers.Dense(512, activation='relu')) 160 model.add(layers.Dense(1, activation='sigmoid')) 161 model.summary()#查看标量信息 162 163 164 #统一化 165 model.compile(loss='binary_crossentropy', 166 optimizer=optimizers.RMSprop(lr=1e-4), 167 metrics=['acc']) 168 train_datagen = ImageDataGenerator(rescale=1./255) 169 validation_datagen=ImageDataGenerator(rescale=1./255) 170 test_datagen = ImageDataGenerator(rescale=1./255) 171 train_generator = train_datagen.flow_from_directory( 172 # 目标文件目录 173 train_dir, 174 #所有图片的size必须是150x150 175 target_size=(150, 150), 176 batch_size=20, 177 class_mode='binary') 178 validation_generator = test_datagen.flow_from_directory( 179 validation_dir, 180 target_size=(150, 150), 181 batch_size=20, 182 class_mode='binary') 183 test_generator = test_datagen.flow_from_directory(test_dir, 184 target_size=(150, 150), 185 batch_size=20, 186 class_mode='binary') 187 for data_batch, labels_batch in train_generator: 188 print('data batch shape:', data_batch.shape) 189 print('labels batch shape:', labels_batch) 190 break 191 # '微笑': 0, '非微笑': 1 192 193 #数据增强 194 datagen = ImageDataGenerator( 195 rotation_range=40, 196 width_shift_range=0.2, 197 height_shift_range=0.2, 198 shear_range=0.2, 199 zoom_range=0.2, 200 horizontal_flip=True, 201 fill_mode='nearest') 202 #数据增强后图片变化 203 import matplotlib.pyplot as plt 204 # from keras.preprocessing import image 205 from keras.utils import image_utils 206 train_smile_dir='E:\\smiletest\\files2\\train\\smile' 207 fnames = [os.path.join(train_smile_dir, fname) for fname in os.listdir(train_smile_dir)] 208 img_path = fnames[22] 209 img = image_utils.load_img(img_path, target_size=(150, 150)) 210 x = image_utils.img_to_array(img) 211 x = x.reshape((1,) + x.shape) 212 i = 0 213 for batch in datagen.flow(x, batch_size=1): 214 plt.figure(i) 215 imgplot = plt.imshow(image_utils.array_to_img(batch[0])) 216 i += 1 217 if i % 4 == 0: 218 break 219 plt.show() 220 221 222 #创建模型 223 from keras import layers 224 from keras import models 225 from keras import optimizers 226 import matplotlib.pyplot as plt 227 #创建网络 228 from keras.preprocessing.image import ImageDataGenerator 229 230 model = models.Sequential() 231 model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3))) 232 model.add(layers.MaxPooling2D((2, 2))) 233 model.add(layers.Conv2D(64, (3, 3), activation='relu')) 234 model.add(layers.MaxPooling2D((2, 2))) 235 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 236 model.add(layers.MaxPooling2D((2, 2))) 237 model.add(layers.Conv2D(128, (3, 3), activation='relu')) 238 model.add(layers.MaxPooling2D((2, 2))) 239 model.add(layers.Flatten()) 240 model.add(layers.Dropout(0.5)) 241 model.add(layers.Dense(512, activation='relu')) 242 model.add(layers.Dense(1, activation='sigmoid')) 243 model.compile(loss='binary_crossentropy', 244 optimizer=optimizers.RMSprop(lr=1e-4), 245 metrics=['acc']) 246 247 #统一化处理 248 train_datagen = ImageDataGenerator( 249 rescale=1./255, 250 rotation_range=40, 251 width_shift_range=0.2, 252 height_shift_range=0.2, 253 shear_range=0.2, 254 zoom_range=0.2, 255 horizontal_flip=True,) 256 257 test_datagen = ImageDataGenerator(rescale=1./255) 258 train_dir = 'E:\\smiletest\\files2\\train' 259 validation_dir='E:\\smiletest\\files2\\validation' 260 train_generator = train_datagen.flow_from_directory( 261 262 train_dir, 263 #转化为150*150像素 264 target_size=(150, 150), 265 batch_size=32, 266 #二进制标签 267 class_mode='binary') 268 269 validation_generator = test_datagen.flow_from_directory( 270 validation_dir, 271 target_size=(150, 150), 272 batch_size=32, 273 class_mode='binary') 274 275 history = model.fit_generator( 276 train_generator, 277 steps_per_epoch=55, 278 epochs=60, 279 validation_data=validation_generator, 280 validation_steps=27) 281 model.save('E:\\smiletest\\smileAndunsmile1.h5') 282 283 #数据增强过后的训练集与验证集的精确度与损失度的图形 284 acc = history.history['acc'] 285 val_acc = history.history['val_acc'] 286 loss = history.history['loss'] 287 val_loss = history.history['val_loss'] 288 289 epochs = range(len(acc)) 290 # 输出准确度折线图与散点图 291 plt.plot(epochs, acc, 'bo', label='Training acc') 292 plt.plot(epochs, val_acc, 'b', label='Validation acc') 293 plt.title('Training and validation accuracy') 294 plt.legend() 295 plt.figure() 296 # 输出损失度折线图与散点图 297 plt.plot(epochs, loss, 'bo', label='Training loss') 298 plt.plot(epochs, val_loss, 'b', label='Validation loss') 299 plt.title('Training and validation loss') 300 plt.legend() 301 plt.show() 302 303 304 305 # 单张图片进行判断是笑脸还是非笑脸 306 # from keras.preprocessing import image 307 from keras.utils import image_utils 308 from keras.models import load_model 309 import numpy as np 310 # 加载模型 311 model = load_model('E:\\smiletest\\smileAndunsmile1.h5') 312 # 本地图片路径 313 img_path = 'E:\\smiletest\\testimg\\5.jpeg' 314 img = image_utils.load_img(img_path, target_size=(150, 150)) 315 316 img_tensor = image_utils.img_to_array(img) / 255.0 317 img_tensor = np.expand_dims(img_tensor, axis=0) 318 prediction = model.predict(img_tensor) 319 prediction1=str((1-prediction)*100).strip('[]') 320 # (1-prediction1)*100 321 print('笑脸的概率:',prediction1,'%') 322 if prediction[0][0] > 0.5: 323 result = '非笑脸' 324 else: 325 result = '笑脸' 326 print('测试结果:',result)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律