
SQL优化 MySQL版 - 索引分类、创建方式、删除索引、查看索引、SQL性能问题
SQL优化 MySQL版 - 索引分类、创建方式、删除索引、查看索引、SQL性能问题
作者 Stanley 罗昊
【转载请注明出处和署名,谢谢!】
索引分类
单值索引
单的意思就是单列的值,比如说有一张数据库表,表内有三个字段,分别是 id name age,我给age这个字段加一个索引,这就是单值索引,因为只有age这一列是索引;
一个表可以有多个单值索引,我不光可以设置age,我也可以吧name设置成索引,或许更多;
唯一索引
顾名思义,就是不能重复,比如age就不能被设置为唯一索引,因为年龄肯定是不唯一的,小明18岁,有可能小李也是18岁,这就重复了,所以age这一列不能被设置成唯一索引;
一般唯一索引就是Id;
复合索引
由多个列构成,相当于书的二级目录,比如我找“赵”这个字,它就先去Z里面找,然后再去zhao里面去找,找两次;
这个时候我把name跟age它两个共同组成一个复合索引,意思就是,我先根据name找人,如果名字重复了,我再根据age去找;
复合索引不一定必须两个列在一起使用,比如找李四,这个表里面就一个李四,就没有必要再去找age进行筛选;
创建索引的方式一
语法:careate 索引类型 索引名 on 表 (字段)//你现在在给那张表的那个字段加索引
创建单值索引
单值索引索引类型就是index;
careate index dept_index on tb(dept)
讲解:我要根据部门进行查询所以我就给部门加一个单值索引,dept_index就是我起的名字,dept就是部门的意思,名字可以随便起,但是要有意义,on后面跟上表名,我的数据库的这张表是tb,所以我写tb,括号里面写字段名;
创建唯一索引
careate unique index name_index on tb (name)
讲解:unique 与 index 都是索引类型,这里我们就假设name是唯一的,创建方法跟上面一样,无非就多加了一个unique,去掉unique就是单值索引;
创建复合索引
careate index dept_name_index on tb tb(dept,name);//程序会自动检测,如果你后面参数只有一个,那就判定你为单值,如果是一个以上,就判定你是复合!
讲解:我现在假设dept跟name这俩字段复合,我现在查询一个人的时候,先看他是哪个部门的(dept)如果大家都是开发部门的,那我再根据名字找,如果你不是开发部门的,那我我就直接找到了,就两次截然查询,也就是先根据部门,再根据名字;
创建索引的方式二
语法:alter table 表名 索引类型 索引名(字段)
创建单值索引
alter table tb add index dept_index(dept);
讲解:add就表示给tb这张表添加一个为index类型的索引,并起名为dept_index,要被加的字段是dept;
创建唯一索引
alter table tb add unique index name_index(name)
讲解:照猫画虎,跟上放基本一致,假设name字段是唯一不可重复
创建复合索引
alter table tb add index dept_name_index(dept,name)
讲解:先dept就是先根据dept查,再去根据name查,这个顺序是有意义的!
值得注意的是,两个创建方式的效果是一样的,任选其一,均不需要事物的提交(commit),因为两者都是DDL语句,程序遇到DDL会自动提交,但是你写了也不报错,就是什么也没提交而已;
事物只对DML语句进行操作,也就是增删改操作,这个需要理解!
注意:
如果一个字段是primary key(主键),则该字段默认就是主键索引,即便你没有给他加索引,他也是主键索引!
主键索引与唯一索引基本相似,区别就是,值不能为Null,而唯一索引可以!
主键索引:值不能重复 值不能为null
唯一索引:值不能重复 值可以为null
删除索引
语法:drop index 索引名 on 表名;
drop index name_index on tb;
讲解,我要删除的索引名字为name_index on 它属于 tb 表
查询索引
语法:show index from tb;
解析,看一下tb这张表的索引;
SQL性能问题
1.分析SQSL的执行计划
通过explain,可以模拟SQL优化器执行SQL语句,从而让开发人员知道自己编写的状况;
查询执行计划:explain+SQL语句;
举例:explain select * From bbs_detail,看一下执行结果:
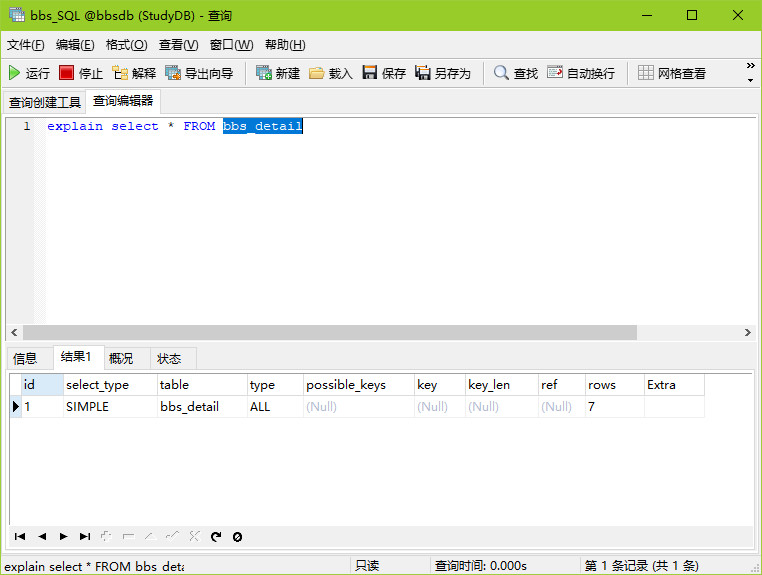
我会在下篇文章详细介绍并且实战优化,在这里各位仅做了解即可;
解说: id:顾名思义就是查询编号 select_type:查询类型 table:你在操作哪一张表 type:类型 key:实际使用的索引,你到底用了哪些索引 possible_keys:预测你用到了哪些索引,假设你用了八个索引,它这里就会显示八个,但是实际有效的只有五个,所以在key显示就是五个! key_len:实际使用索引的长度; ref:表和表之间的引用关系; rows:通过索引查询到的数据量;
Extra:额外的优化信息
2.MySQL查询优化器会干扰我们的优化
我在前几章说过有关为什么会干扰我们优化好的SQL语句,因为它内置有一个优化器,它会擅自篡改我们优化好的SQL语句;
今日感悟:
自利偏差告诉我们:
人在失败时会把原因归结到别人身上,
成功时更倾向把劳务归于自己,
印象管理告诉我们:
人在别人的面前,
会不知不觉地进行自我表演。
决断效应告诉我们:
人在选择以后,会通过自我说服,来让自己相信自己的选择是最好的
自我确定理论告诉我们:
人一般会喜欢和自己相似的人,这里面的爱,包含了对自己的肯定
学习心理学,自己能更好的了解自己,并理解他人;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号