
Python教程:pandas读写txt文件——DataFrame和Series
大家用pandas一般都是读写csv文件或者tsv文件,读写txt文件时一般就with open了,其实pandas数据类型操作起来更加方便,还是建议全用pandas这一套。
读txt文件代码如下,主要是设置正则表达式的分隔符(sep参数),和列名取消(header参数),以及不需要列索引(index_col)。
1 df = pd.read_csv("workloads/tpch_workload.txt", header=None,error_bad_lines=False,sep = r'\s+\n',index_col=0)
设分隔符是为了去除行末空格和多个空行;
设列名取消是防止把第一行的数据当做schema;
设索引取消是防止输出 df.iloc[i] 的时候给你输出一堆Series,就像下面这样:
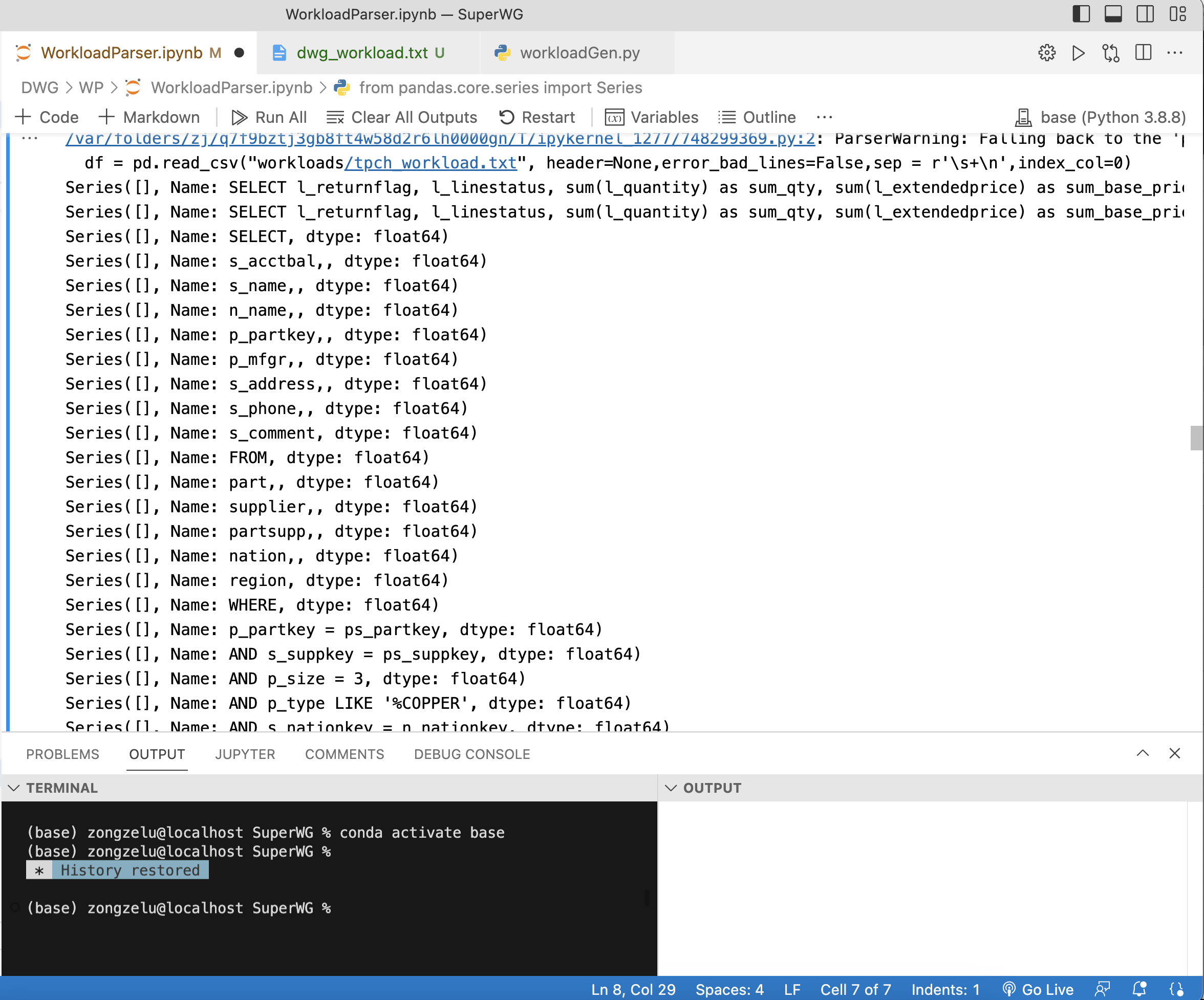
当然你也可以直接输出 df.iloc[i].name 来去掉Series的warper。输出 df 和 df.index 的结果如下,里面包含了一些不必要的warper:
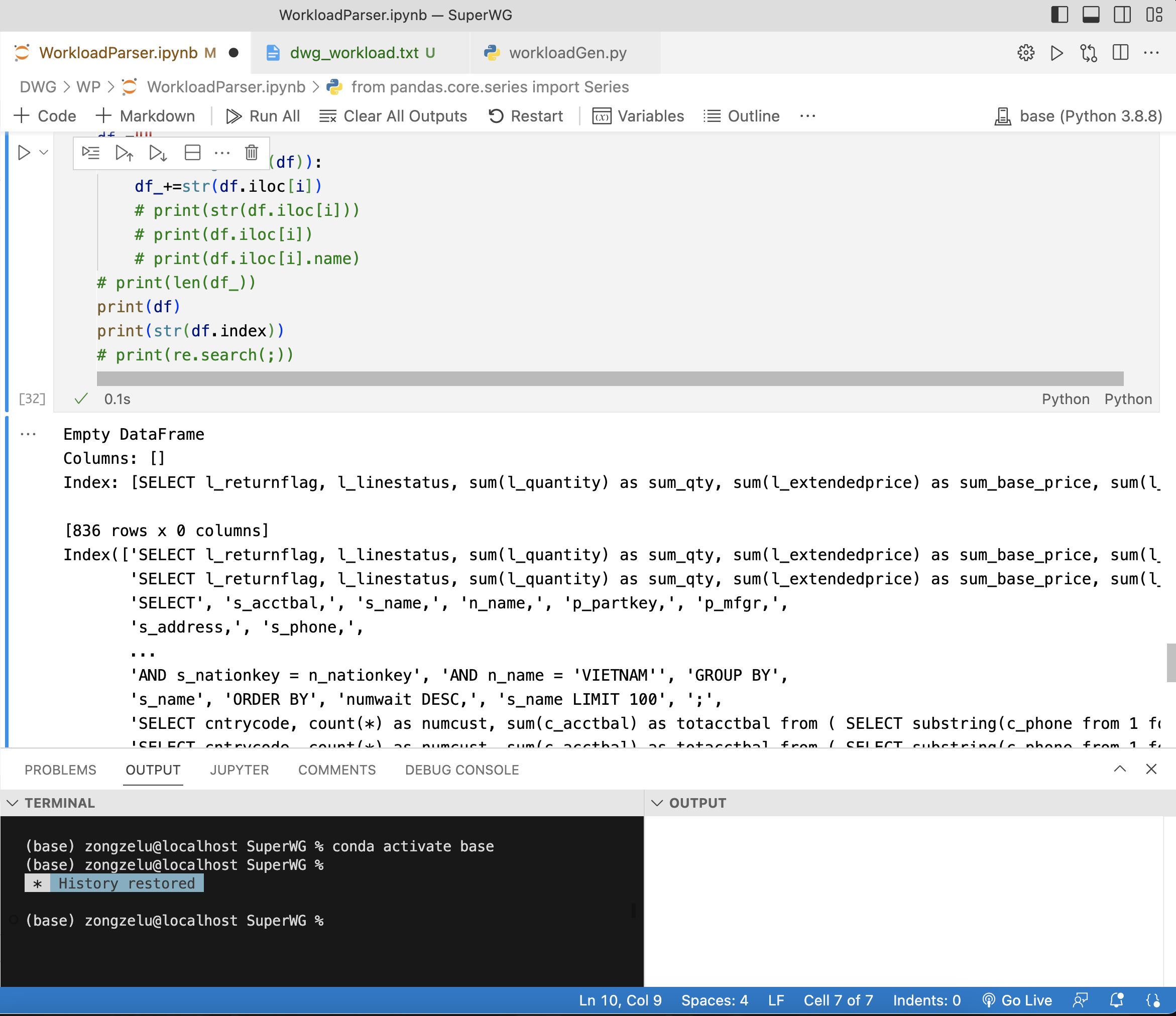
想要去掉结果的话,就用 df.index.value 即可,因为这个df读了txt之后本质上是空DataFrame,数据全都存在index里了。

