TCN
- TCN的优点
(1)并行性。当给定一个句子时,TCN可以将句子并行的处理,而不需要像RNN那样顺序的处理。
(2)灵活的感受野。TCN的感受野的大小受层数、卷积核大小、扩张系数等决定。可以根据不同的任务不同的特性灵活定制。
(3)稳定的梯度。RNN经常存在梯度消失和梯度爆炸的问题,这主要是由不同时间段上共用参数导致的,和传统卷积神经网络一样,TCN不太存在梯度消失和爆炸问题。
(4)内存更低。RNN在使用时需要将每步的信息都保存下来,这会占据大量的内存,TCN在一层里面卷积核是共享的,内存使用更低。
- 为什么选择TCN(时间卷积网络)而不是LSTM/GRU?
TCN 的内存比具有相同容量的循环架构更长。
在长时间序列(序列 MNIST、添加问题、复制内存、字级 PTB...)上表现优于 LSTM/GRU。
并行性(卷积层)、灵活的感受野大小(模型可以看到多远)、稳定的梯度(与随时间反向传播相比,梯度消失)......
- 但因其卷积模型结构限制,TCN模型搭建完成之后,对输入序列长度要求严格,当输入长度不满足要求时,输出对输入序列长度变化不敏感,进而会影响状态评估的准确性。为解决此问题,本文通过引入编码器对TCN模型进行改进。
- 编码器-解码器结构分为编码器和解码器两部分。通过调整编码器并对其训练,可以将输入的长时间序列转换至TCN模型感受野大小,且在此过程中可以保留序列原有的关键信息;解码器可以根据压缩后的特征信息对数据进行还原,用于编码器的模型训练。利用编码器对数据特征的压缩提取能力,获取电池健康因子关键信息的短时序列表达,并进一步由TCN模型挖掘电池健康因子与SOH之间的映射关系,实现对电动汽车电池健康状态的准确评估,以期在提高评估准确性的同时,增强传统TCN模型在输入长度要求方面的灵活性。
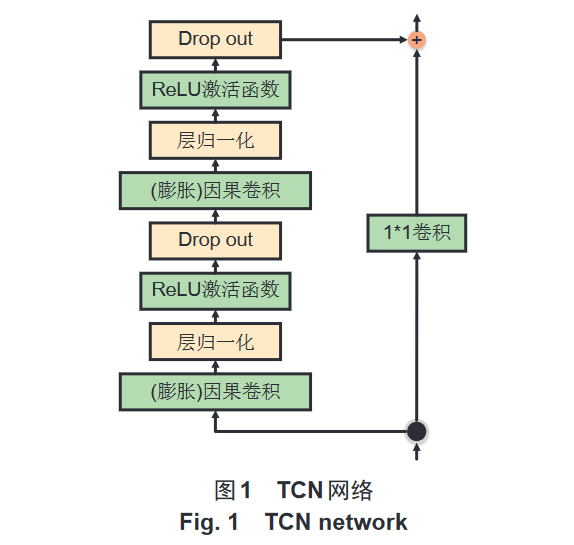
- TCN在算法优化上采用了:膨胀因果卷积、空洞卷积(通过在卷积核中插入空白位置/膨胀因子,使卷积核覆盖更长范围的输入而不增加参数数量,实现增加感受野)、残差连接(可以构建更深层次的网络、提高性能)。
- TCN的结构上由多个重复模块组成,每个模块包含两个因果空洞卷积层+一个残差连接,每个模块的膨胀因子、过滤器数量都不一样;最后一个模块后再加一个全连接层/softmax层来输出预测结果。
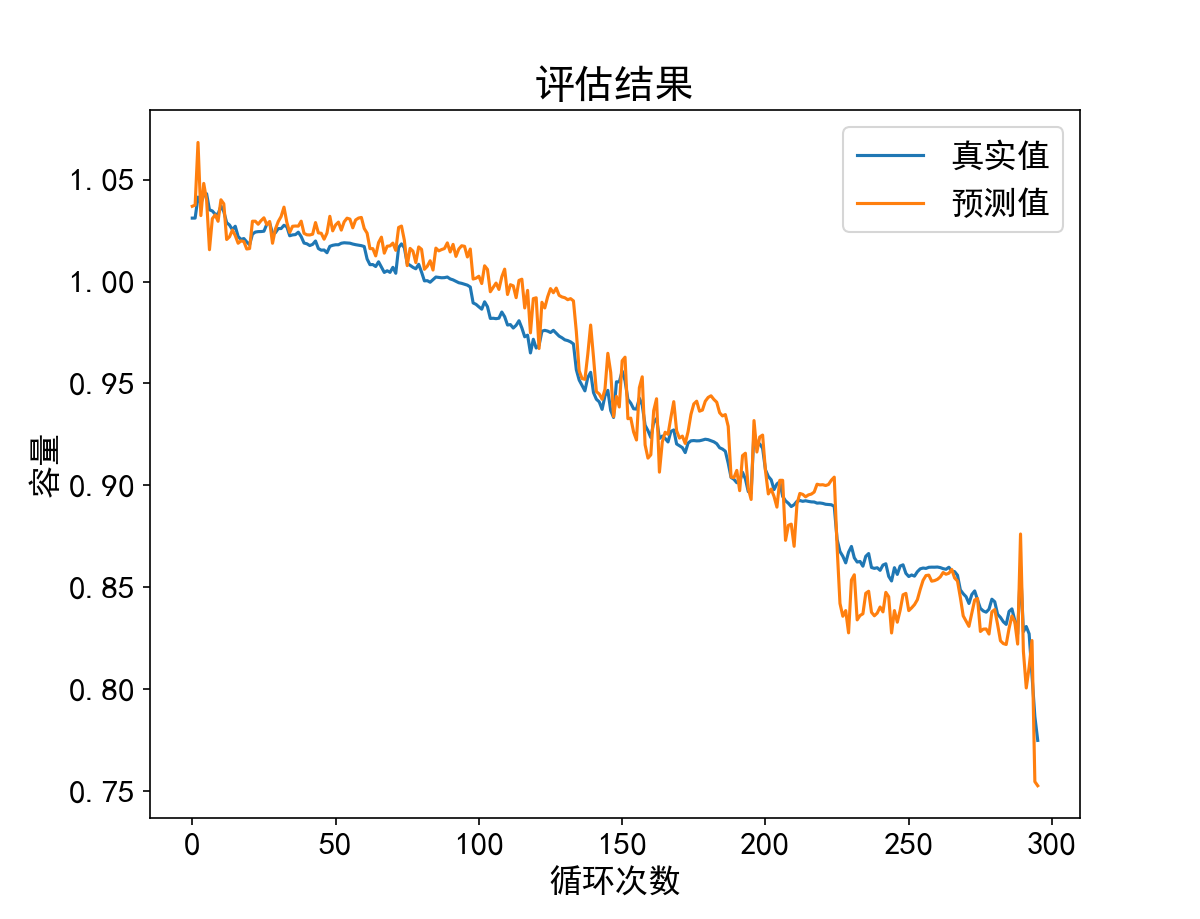
1 ##导入库 2 import numpy as np 3 import pandas as pd 4 import matplotlib.pyplot as plt 5 import torch 6 import torch.nn as nn 7 import torch.utils.data as Data 8 from torch.nn.utils import weight_norm 9 10 plt.rcParams['font.sans-serif'] = ['SimHei'] #运行配置参数中的字体(font)为黑体(SimHei) 11 plt.rcParams['axes.unicode_minus'] = False #运行配置参数总的轴(axes)正常显示正负号(minus) 12 plt.rcParams['font.size'] = 16 #字体大小 13 14 15 # 这个函数是用来修剪卷积之后的数据的尺寸,让其与输入数据尺寸相同。 16 class Chomp1d(nn.Module): 17 """ 18 假设输入长度是5,padding是1,卷积核为2,得到的长度就是6,但是只取前5个。chomp_size也就是padding的值 19 """ 20 21 def __init__(self, chomp_size): 22 super(Chomp1d, self).__init__() 23 self.chomp_size = chomp_size 24 25 def forward(self, x): 26 return x[:, :, :-self.chomp_size].contiguous() 27 28 29 # 这个就是TCN的基本模块,包含8个部分,两个(卷积+修剪+relu+dropout) 30 # 里面提到的downsample就是下采样,其实就是实现残差链接的部分。不理解的可以无视这个 31 class TemporalBlock(nn.Module): 32 """ 33 n_inputs = 输入的通道数 34 n_outputs = 输出的通道数。可以理解为卷积核的个数 35 kernel_size = 卷积核宽度 36 stride = 卷积步长 37 padding = 补偿宽度 38 dilation = 卷积核元素之间的间距 39 """ 40 41 def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2): 42 super(TemporalBlock, self).__init__() 43 self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size, 44 stride=stride, padding=padding, dilation=dilation)) 45 self.chomp1 = Chomp1d(padding) 46 self.relu1 = nn.ReLU() 47 self.dropout1 = nn.Dropout(dropout) 48 49 self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size, 50 stride=stride, padding=padding, dilation=dilation)) 51 self.chomp2 = Chomp1d(padding) 52 self.relu2 = nn.ReLU() 53 self.dropout2 = nn.Dropout(dropout) 54 55 self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1, 56 self.conv2, self.chomp2, self.relu2, self.dropout2) 57 self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else None 58 self.relu = nn.ReLU() 59 self.init_weights() 60 61 def init_weights(self): 62 self.conv1.weight.data.normal_(0, 0.01) 63 self.conv2.weight.data.normal_(0, 0.01) 64 if self.downsample is not None: 65 self.downsample.weight.data.normal_(0, 0.01) 66 67 def forward(self, x): 68 out = self.net(x) 69 res = x if self.downsample is None else self.downsample(x) 70 return self.relu(out + res) 71 72 73 class TemporalConvNet(nn.Module): 74 """ 75 num_inputs就是输入数据的通道数,一般就是1 76 num_channels应该是个列表,其他的np.array也行,它的长度表示共有几个TemporalBlock,里面的数字,表示每次经过一个TemporalBlock的输入通道数 77 比方说是[2,1]。那么整个TCN模型包含两个TemporalBlock,整个模型共有4个卷积层, 78 第一个TemporalBlock的两个卷积层的膨胀系数dilation = 2^0 = 1,输出的通道数就是2 79 第二个TemporalBlock的两个卷积层的膨胀系数是dilation = 2^1 = 2,输出的通道数就是1 80 """ 81 82 def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2): 83 super(TemporalConvNet, self).__init__() 84 layers = [] 85 num_levels = len(num_channels) 86 for i in range(num_levels): 87 dilation_size = 2 ** i 88 in_channels = num_inputs if i == 0 else num_channels[i - 1] 89 out_channels = num_channels[i] 90 layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size, 91 padding=(kernel_size - 1) * dilation_size, dropout=dropout)] 92 93 self.network = nn.Sequential(*layers) 94 95 def forward(self, x): 96 return self.network(x)[:, :, -1] # .squeeze() # 不给参数就会把能删减的都删减 97 98 99 # 卷积都是在最后一个维度上卷 100 data = pd.read_csv(r'./CS33.csv') 101 data = data.iloc[:592, :4] 102 103 # 归一化函数 x为DataFrame对象 104 max_min_scaler = lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)) 105 data.iloc[:, [1]] = data.iloc[:, [1]].apply(max_min_scaler) 106 data.iloc[:, [2]] = data.iloc[:, [2]].apply(max_min_scaler) 107 108 109 # 592 / 2 = 296 110 # input 20 output 1 // 296-19 = 277 111 def get_data(data, train_use_len=296, test_use_len=296, input_len=15, output_len=1): 112 """ 113 所用的数据 114 训练所用的数据有多长 296 115 测试所用的数据有多长 296 116 每次输入的长度 15 117 输出的长度 1 118 """ 119 x, y = data.shape[0], data.shape[1] 120 if (x == train_use_len + test_use_len): 121 # 训练数据 122 train_x = np.zeros(shape=(train_use_len - input_len + 1, 3, input_len)) 123 train_y = np.zeros(shape=(train_use_len - input_len + 1, output_len)) 124 for batch in range(train_use_len - input_len + 1): 125 train_x[batch, :, :] = data.iloc[batch:batch + input_len, 1:].T.values 126 train_y[batch, :] = data.iloc[batch + input_len - 1, 0] 127 # 测试数据 128 test_x = np.zeros(shape=(test_use_len, 3, input_len)) 129 test_y = np.zeros(shape=(test_use_len, output_len)) 130 for batch in range(test_use_len): 131 test_x[batch, :, :] = data.iloc[batch + test_use_len - input_len + 1:batch + test_use_len + 1, 1:].T.values 132 test_y[batch, :] = data.iloc[batch + test_use_len, 0] 133 134 train_x = torch.from_numpy(train_x).type(torch.float32) 135 train_y = torch.from_numpy(train_y).type(torch.float32) 136 test_x = torch.from_numpy(test_x).type(torch.float32) 137 test_y = torch.from_numpy(test_y).type(torch.float32) 138 print(train_x.shape, train_y.shape, test_x.shape, test_y.shape) 139 140 torch_dataset = Data.TensorDataset(train_x, train_y) 141 loader = Data.DataLoader(dataset=torch_dataset, 142 batch_size=32, 143 shuffle=True, # 每次训练打乱数据 144 num_workers=0, # 使用多进行程读取数据, 145 ) 146 else: 147 print("数据未用完") 148 149 return (train_x, train_y, test_x, test_y), loader 150 151 152 df, loader = get_data(data, train_use_len=296, test_use_len=296, input_len=20, output_len=1) 153 model = TemporalConvNet(num_inputs=3, num_channels=[3, 2, 1], kernel_size=2, dropout=0.2) 154 criterion = nn.MSELoss() 155 optimizer = torch.optim.Adam(model.parameters(), lr=1e-2) # 1e-2 156 NEED_TRAIN = True 157 if NEED_TRAIN: 158 for epoch in range(500): 159 for step, (batch_x, batch_y) in enumerate(loader): 160 x = batch_x 161 y = batch_y 162 output = model(x) 163 164 loss = criterion(output, y) 165 model.zero_grad() 166 loss.backward(retain_graph=True) # 167 optimizer.step() 168 169 if epoch % 100 == 0: # 每 10 次输出结果 170 print('Epoch: {}, Loss: {:.5f}'.format(epoch, loss.item())) 171 # 保存模型参数 172 # torch.save(model, '.\\5-6-7-18\\7\\TCN_net.pth') 173 torch.save(model, '.\\TCN.pth') 174 else: 175 # 加载网络参数 176 model = torch.load('.\\TCN.pth') 177 pre = model(df[2]) # shape=(48) 178 fake = list(pre.detach().numpy().reshape(-1)) 179 180 plt.figure(figsize=(8, 6)) 181 plt.plot(range(296), data.iloc[296:, 0]) 182 plt.plot(fake) 183 # plt.axvline(x=75, ymin=0, ymax=0.8, c="black", ls="--", lw=2) 184 plt.legend(['真实值', '预测值']) 185 plt.title('评估结果') 186 plt.xlabel('循环次数') 187 plt.ylabel('容量') 188 # plt.savefig('.\\Pic_out\\7TCN75out', dpi=1000) 189 plt.show() 190 out = pd.DataFrame([list(data.iloc[296:, 0]), fake]).T 191 out.columns = ['real', 'TCN'] 192 out.to_csv("TCN实验结果.csv", index=False) 193 out

1 ##导入库 2 import numpy as np 3 import pandas as pd 4 import matplotlib.pyplot as plt 5 import torch 6 import torch.nn as nn 7 import torch.utils.data as Data 8 from torch.nn.utils import weight_norm 9 10 plt.rcParams['font.sans-serif'] = ['SimHei'] #运行配置参数中的字体(font)为黑体(SimHei) 11 plt.rcParams['axes.unicode_minus'] = False #运行配置参数总的轴(axes)正常显示正负号(minus) 12 plt.rcParams['font.size'] = 16 #字体大小 13 14 15 # 这个函数是用来修剪卷积之后的数据的尺寸,让其与输入数据尺寸相同。 16 class Chomp1d(nn.Module): 17 """ 18 假设输入长度是5,padding是1,卷积核为2,得到的长度就是6,但是只取前5个。chomp_size也就是padding的值 19 """ 20 21 def __init__(self, chomp_size): 22 super(Chomp1d, self).__init__() 23 self.chomp_size = chomp_size 24 25 def forward(self, x): 26 return x[:, :, :-self.chomp_size].contiguous() 27 28 29 # 这个就是TCN的基本模块,包含8个部分,两个(卷积+修剪+relu+dropout) 30 # 里面提到的downsample就是下采样,其实就是实现残差链接的部分。不理解的可以无视这个 31 class TemporalBlock(nn.Module): 32 """ 33 n_inputs = 输入的通道数 34 n_outputs = 输出的通道数。可以理解为卷积核的个数 35 kernel_size = 卷积核宽度 36 stride = 卷积步长 37 padding = 补偿宽度 38 dilation = 卷积核元素之间的间距 39 """ 40 41 def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2): 42 super(TemporalBlock, self).__init__() 43 self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size, 44 stride=stride, padding=padding, dilation=dilation)) 45 self.chomp1 = Chomp1d(padding) 46 self.relu1 = nn.ReLU() 47 self.dropout1 = nn.Dropout(dropout) 48 49 self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size, 50 stride=stride, padding=padding, dilation=dilation)) 51 self.chomp2 = Chomp1d(padding) 52 self.relu2 = nn.ReLU() 53 self.dropout2 = nn.Dropout(dropout) 54 55 self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1, 56 self.conv2, self.chomp2, self.relu2, self.dropout2) 57 self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else None 58 self.relu = nn.ReLU() 59 self.init_weights() 60 61 def init_weights(self): 62 self.conv1.weight.data.normal_(0, 0.01) 63 self.conv2.weight.data.normal_(0, 0.01) 64 if self.downsample is not None: 65 self.downsample.weight.data.normal_(0, 0.01) 66 67 def forward(self, x): 68 out = self.net(x) 69 res = x if self.downsample is None else self.downsample(x) 70 return self.relu(out + res) 71 72 73 class TemporalConvNet(nn.Module): 74 """ 75 num_inputs就是输入数据的通道数,一般就是1 76 num_channels应该是个列表,其他的np.array也行,它的长度表示共有几个TemporalBlock,里面的数字,表示每次经过一个TemporalBlock的输入通道数 77 比方说是[2,1]。那么整个TCN模型包含两个TemporalBlock,整个模型共有4个卷积层, 78 第一个TemporalBlock的两个卷积层的膨胀系数dilation = 2^0 = 1,输出的通道数就是2 79 第二个TemporalBlock的两个卷积层的膨胀系数是dilation = 2^1 = 2,输出的通道数就是1 80 """ 81 82 def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2): 83 super(TemporalConvNet, self).__init__() 84 layers = [] 85 num_levels = len(num_channels) 86 for i in range(num_levels): 87 dilation_size = 2 ** i 88 in_channels = num_inputs if i == 0 else num_channels[i - 1] 89 out_channels = num_channels[i] 90 layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size, 91 padding=(kernel_size - 1) * dilation_size, dropout=dropout)] 92 93 self.network = nn.Sequential(*layers) 94 95 def forward(self, x): 96 return self.network(x)[:, :, -1] # .squeeze() # 不给参数就会把能删减的都删减 97 98 99 # 卷积都是在最后一个维度上卷 100 data = pd.read_csv(r'./CS33.csv') 101 data = data.iloc[:592, :4] 102 103 # 归一化函数 x为DataFrame对象 104 max_min_scaler = lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)) 105 data.iloc[:, [1]] = data.iloc[:, [1]].apply(max_min_scaler) 106 data.iloc[:, [2]] = data.iloc[:, [2]].apply(max_min_scaler) 107 108 109 # 592 / 2 = 296 110 # input 20 output 1 // 296-19 = 277 111 def get_data(data, train_use_len=296, test_use_len=296, input_len=15, output_len=1): 112 """ 113 所用的数据 114 训练所用的数据有多长 296 115 测试所用的数据有多长 296 116 每次输入的长度 15 117 输出的长度 1 118 """ 119 x, y = data.shape[0], data.shape[1] 120 if (x == train_use_len + test_use_len): 121 # 训练数据 122 train_x = np.zeros(shape=(train_use_len - input_len + 1, 3, input_len)) 123 train_y = np.zeros(shape=(train_use_len - input_len + 1, output_len)) 124 for batch in range(train_use_len - input_len + 1): 125 train_x[batch, :, :] = data.iloc[batch:batch + input_len, 1:].T.values 126 train_y[batch, :] = data.iloc[batch + input_len - 1, 0] 127 # 测试数据 128 test_x = np.zeros(shape=(test_use_len, 3, input_len)) 129 test_y = np.zeros(shape=(test_use_len, output_len)) 130 for batch in range(test_use_len): 131 test_x[batch, :, :] = data.iloc[batch + test_use_len - input_len + 1:batch + test_use_len + 1, 1:].T.values 132 test_y[batch, :] = data.iloc[batch + test_use_len, 0] 133 134 train_x = torch.from_numpy(train_x).type(torch.float32) 135 train_y = torch.from_numpy(train_y).type(torch.float32) 136 test_x = torch.from_numpy(test_x).type(torch.float32) 137 test_y = torch.from_numpy(test_y).type(torch.float32) 138 print(train_x.shape, train_y.shape, test_x.shape, test_y.shape) 139 140 torch_dataset = Data.TensorDataset(train_x, train_y) 141 loader = Data.DataLoader(dataset=torch_dataset, 142 batch_size=32, 143 shuffle=True, # 每次训练打乱数据 144 num_workers=0, # 使用多进行程读取数据, 145 ) 146 else: 147 print("数据未用完") 148 149 return (train_x, train_y, test_x, test_y), loader 150 151 152 df, loader = get_data(data, train_use_len=296, test_use_len=296, input_len=20, output_len=1) 153 model = TemporalConvNet(num_inputs=3, num_channels=[3, 2, 1], kernel_size=2, dropout=0.2) 154 criterion = nn.MSELoss() 155 optimizer = torch.optim.Adam(model.parameters(), lr=1e-2) # 1e-2 156 NEED_TRAIN = True 157 if NEED_TRAIN: 158 for epoch in range(500): 159 for step, (batch_x, batch_y) in enumerate(loader): 160 x = batch_x 161 y = batch_y 162 output = model(x) 163 164 loss = criterion(output, y) 165 model.zero_grad() 166 loss.backward(retain_graph=True) # 167 optimizer.step() 168 169 if epoch % 100 == 0: # 每 10 次输出结果 170 print('Epoch: {}, Loss: {:.5f}'.format(epoch, loss.item())) 171 # 保存模型参数 172 # torch.save(model, '.\\5-6-7-18\\7\\TCN_net.pth') 173 torch.save(model, '.\\TCN.pth') 174 else: 175 # 加载网络参数 176 model = torch.load('.\\TCN.pth') 177 pre = model(df[2]) # shape=(48) 178 fake = list(pre.detach().numpy().reshape(-1)) 179 180 plt.figure(figsize=(8, 6)) 181 plt.plot(range(296), data.iloc[296:, 0]) 182 plt.plot(fake) 183 # plt.axvline(x=75, ymin=0, ymax=0.8, c="black", ls="--", lw=2) 184 plt.legend(['真实值', '预测值']) 185 plt.title('评估结果') 186 plt.xlabel('循环次数') 187 plt.ylabel('容量') 188 # plt.savefig('.\\Pic_out\\7TCN75out', dpi=1000) 189 plt.show() 190 out = pd.DataFrame([list(data.iloc[296:, 0]), fake]).T 191 out.columns = ['real', 'TCN'] 192 out.to_csv("TCN实验结果.csv", index=False) 193 out

 浙公网安备 33010602011771号
浙公网安备 33010602011771号