

前段时间,一个客户现场的Hadoop看起来很不正常,有的机器的存储占用达到95%,有的机器只有40%左右,刚好前任的负责人走了,这边还没有明确接班人的时候。
我负责的大数据计算部分,又要依赖Hadoop的基础平台,要是Hadoop死了,我的报表也跑不出来(专业背锅)。
做下balance,让各个节点的存储均衡一下。
1、首先需要配上这个参数:
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>62914560</value>
<description>hdfs做balance的占用的网络带宽,建议配置网卡带宽的一半(62914560/1024/1024*8=480MBps)</description>
</property>
2、重启datanode
# 停止datanode [hadoop@venn06 sbin]$ ./hadoop-daemon.sh stop datanode stopping datanode # 启动datanode [hadoop@venn06 sbin]$ ./hadoop-daemon.sh start datanode starting datanode, logging to /opt/hadoop/hadoop3/logs/hadoop-hadoop-datanode-venn06.out
服务器网卡的带宽有限,不设置这个参数,做balance的时候,会把网卡的带宽跑满。需要移动的block很多,执行时间就会很长,会导致集群网络资源不足,任务跑得很慢。
3、执行balance
[hadoop@venn05 bin]$ pwd
/opt/hadoop/hadoop3/bin
[hadoop@venn05 bin]$ nohup ./hdfs balancer -threshold 1 &
由于执行时间会很长,所以把命令放到后台执行。
HDFS做balance的方式大概如下:
1、计算集群中需要移动的block数量,计算需要移动的文件大小。
2、并发的从资源占用高的机器,往资源占用低的机器移数据。一批一批的移,一批的大小,会根据需要移动的文件大小计算。
3、重复第1步,直到资源均衡(1%左右的差距)
HDFS做balance的时候,会先移动block,成功后才会删除数据,只要集群网络资源充足,可以不警慎的执行balance操作,随时停也不影响,不会丢数据。
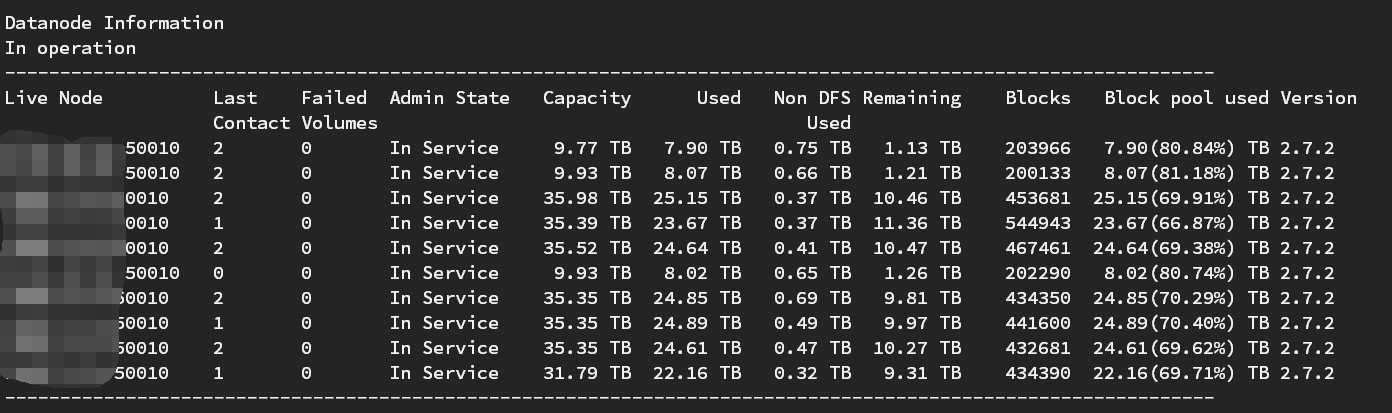
由于datanode 空间大小不同,所以有的机器磁盘占用会高一点。

