
Flink 版本:1.17.1
CDC 版本:2.3.0
StarRocks 版本:2.5.8
前言
最近需要实时同步几个 Mysql 表到 StarRocks,薅出之前写的 Demo 代码,简单改造了一下,加了个配置文件,可以通过修改配置文件指定 source、sink 表,这样就不用讲表名什么的写死到代码里面。
再利用 flink session 模式,把一堆任务放到一个 session(表的数据增量并不大),利用不太多的资源,同步一堆表。
DDL
StarRocks 的 flink connect,需要先在 StarRocks 上建表,直接基于 Mysql 表,把字段和类型拿出来,加上表类型、分桶和properties 就行
CREATE TABLE `ads_circle_guest_task_result` (
`sub_task_id` varchar(128) COMMENT '子任务id',
`task_id` bigint(20) COMMENT '任务id',
-- 字段忽略
`created_at` datetime COMMENT '子任务创建时间',
`created_by` varchar(64) COMMENT '创建人',
`created_time` datetime COMMENT '子任务创建时间',
`updated_time` datetime COMMENT '子任务修改时间',
`finish_time` datetime COMMENT '任务完成时间',
`updated_at` datetime COMMENT '子任务修改时间',
`updated_by` varchar(64) COMMENT '更新人',
`dr` tinyint(1) COMMENT '逻辑删除字段'
)
ENGINE=OLAP
PRIMARY KEY(sub_task_id)
DISTRIBUTED BY HASH(sub_task_id) BUCKETS 8
PROPERTIES(
"replication_num" = "1"
);
配置文件
用配置文件生成任务,所以任务名做成参数,在配置文件中传入,直接使用表名作为 任务名
将 Flink Cdc 需要的参数使用 source.xxx 的方式放在配置文件中
将 Flink 的 StarRocks connector 需要的参数使用 sink.xxx 的方式放在配置文件中
job_name=ads_circle_guest_task_result
## source mysql
source.host:localhost
source.port:3306
source.user:root
source.pass:123456
source.database:test
source.table_list:test.ads_circle_guest_task_result
source.time_zone:Asia/Shanghai
# init latest
source.startup_option:LATEST
source.startup_option_time:2024-03-07 00:00:00
## sink starrocks
sink.jdbc-url=jdbc:mysql://localhost:9030
sink.load-url=localhost:18030
sink.username=root
sink.password=123456
sink.database-name=test
sink.table-name=ads_circle_guest_task_result
sink.batch=64000
sink.interval=5000
Source
Flink cdc Source,参数都通过参数的方式传进来
// cdc source
val source = MySqlSource.builder[String]()
.hostname(parameterTool.get("source.host"))
.port(parameterTool.get("source.port").toInt)
.username(parameterTool.get("source.user"))
.password(parameterTool.get("source.pass"))
.databaseList(parameterTool.get("source.database"))
.tableList(parameterTool.get("source.table_list"))
.serverTimeZone(parameterTool.get("source.time_zone"))
// 包含 schema change
.includeSchemaChanges(false)
.debeziumProperties(prop)
// .startupOptions(StartupOptions.latest())
.startupOptions(startupOption)
.deserializer(new DdlDebeziumDeserializationSchema(parameterTool.get("source.host"), parameterTool.get("source.port").toInt))
.build()
Sink
Source 输出的数据是自定义 反序列化器输出的嵌套 Json,使用 operator_type 标识数据的修改类型:c 创建,u 修改,d 删除,r 读,输出的数据是 json 类型,c u r 类型都使用 after ,delete 使用 before
val sink = StarRocksSink.sink(
// the sink options
StarRocksSinkOptions.builder()
.withProperty("jdbc-url", parameterTool.get("sink.jdbc-url"))
.withProperty("load-url", parameterTool.get("sink.load-url"))
.withProperty("username", parameterTool.get("sink.username"))
.withProperty("password", parameterTool.get("sink.password"))
.withProperty("database-name", parameterTool.get("sink.database-name"))
.withProperty("table-name", parameterTool.get("sink.table-name"))
// 自 2.4 版本,支持更新主键模型中的部分列。您可以通过以下两个属性指定需要更新的列。
// .withProperty("sink.properties.partial_update", "true")
// .withProperty("sink.properties.columns", "k1,k2,k3")
.withProperty("sink.properties.format", "json")
.withProperty("sink.properties.strip_outer_array", "true")
// .withProperty("sink.properties.row_delimiter", ROW_SEP)
// .withProperty("sink.properties.column_separator", COL_SEP)
// 设置并行度,多并行度情况下需要考虑如何保证数据有序性
.withProperty("sink.parallelism", "1")
.withProperty("sink.version", "v1")
.withProperty("sink.buffer-flush.max-rows", parameterTool.get("sink.batch"))
.withProperty("sink.buffer-flush.interval-ms", parameterTool.get("sink.interval"))
.build())
map
使用 map 算子,调整一下输入的数据格式,在 json 中添加 "__op" 参数,标明数据操作类型,主要是将 删除的数据标记为 1
val map = env.fromSource(source, WatermarkStrategy.noWatermarks[String](), "cdc")
.map(new RichMapFunction[String, String] {
var jsonParser: JsonParser = _
override def open(parameters: Configuration): Unit = {
jsonParser = new JsonParser()
}
override def map(in: String): String = {
val json = jsonParser.parse(in).getAsJsonObject
val sqlOperator = json.get("operator_type").getAsString
var data: JsonObject = null
var result = ""
if ("r".equals(sqlOperator) || "u".equals(sqlOperator) || "c".equals(sqlOperator)) {
// read / create / u
data = json.get("after").getAsJsonObject
// add
data.addProperty("__op", "0")
} else if ("d".equals(sqlOperator)) {
//
data = json.get("before").getAsJsonObject
data.addProperty("__op", "1")
}
if (data != null && !data.isJsonNull) {
result = data.toString
}
result
}
})
.name("map")
.uid("map")
部署
session
使用 Flink session 启动一个 session,配置 slot 数据为 5
./bin/yarn-session.sh -d -nm cdc -s 4 -jm 2g -tm 4g # -s 参数要写在前面,不然不生效
任务
使用 flink run 启动任务,使用 -yid 参数指定任务的 application id,最后一个参数指定任务的配置文件
bin/flink run -yd -yid application_1682501108615_0788 -c com.venn.connector.starrocks.CdcSingleMysqlTableToStarRocks /data/jar/flink-rookie-1.0.jar ../jar/prd/cdc_asset_available_month.properties
bin/flink run -yd -yid application_1682501108615_0788 -c com.venn.connector.starrocks.CdcSingleMysqlTableToStarRocks /data/jar/flink-rookie-1.0.jar ../jar/prd/cdc_reservation.properties
bin/flink run -yd -yid application_1682501108615_0788 -c com.venn.connector.starrocks.CdcSingleMysqlTableToStarRocks /data/jar/flink-rookie-1.0.jar ../jar/prd/cdc_ads_circle_guest_task_result.properties
bin/flink run -yd -yid application_1682501108615_0788 -c com.venn.connector.starrocks.CdcSingleMysqlTableToStarRocks /data/jar/flink-rookie-1.0.jar ../jar/prd/cdc_oc_project_extract_record.properties
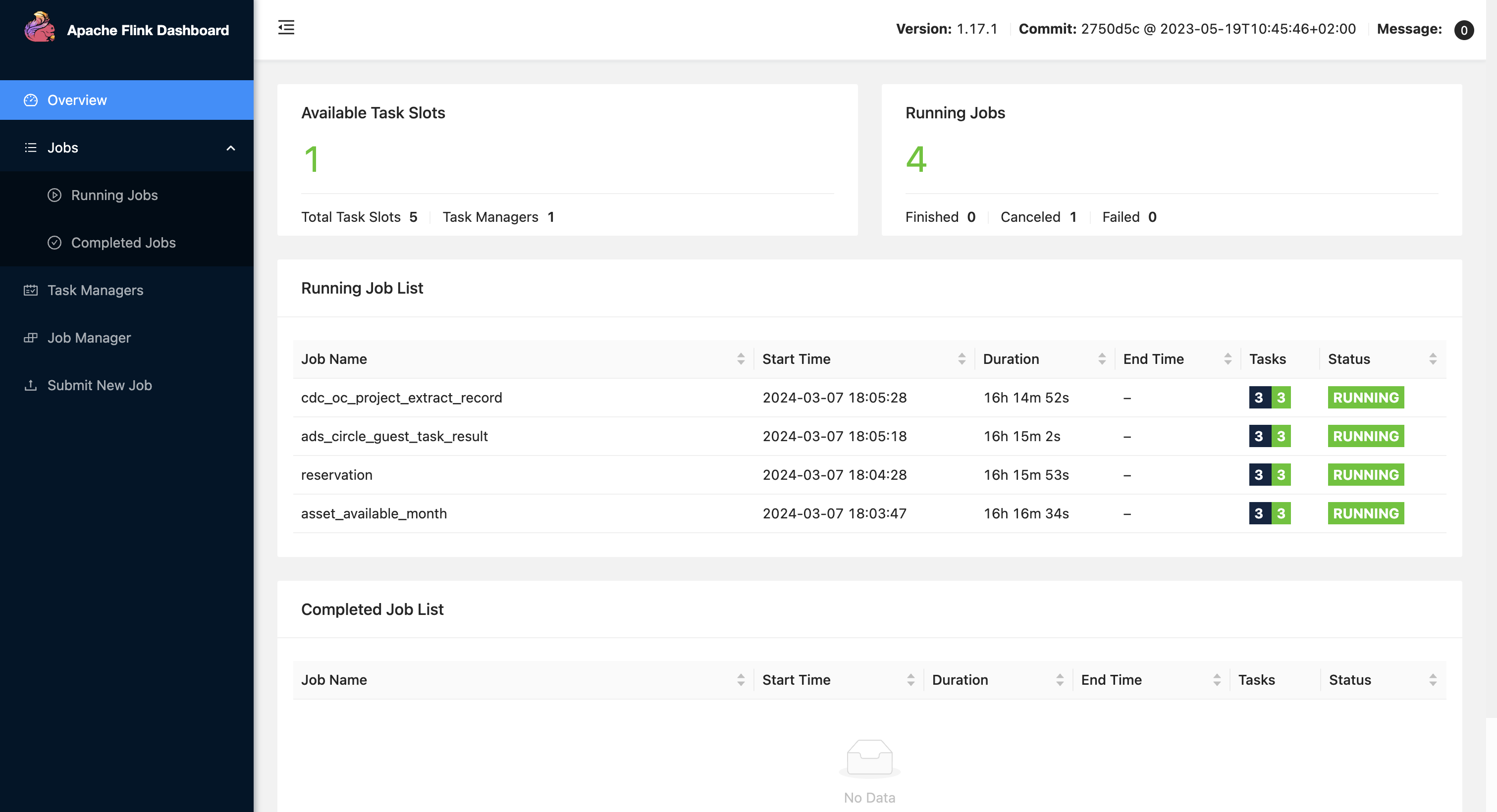
flink web overview页面:
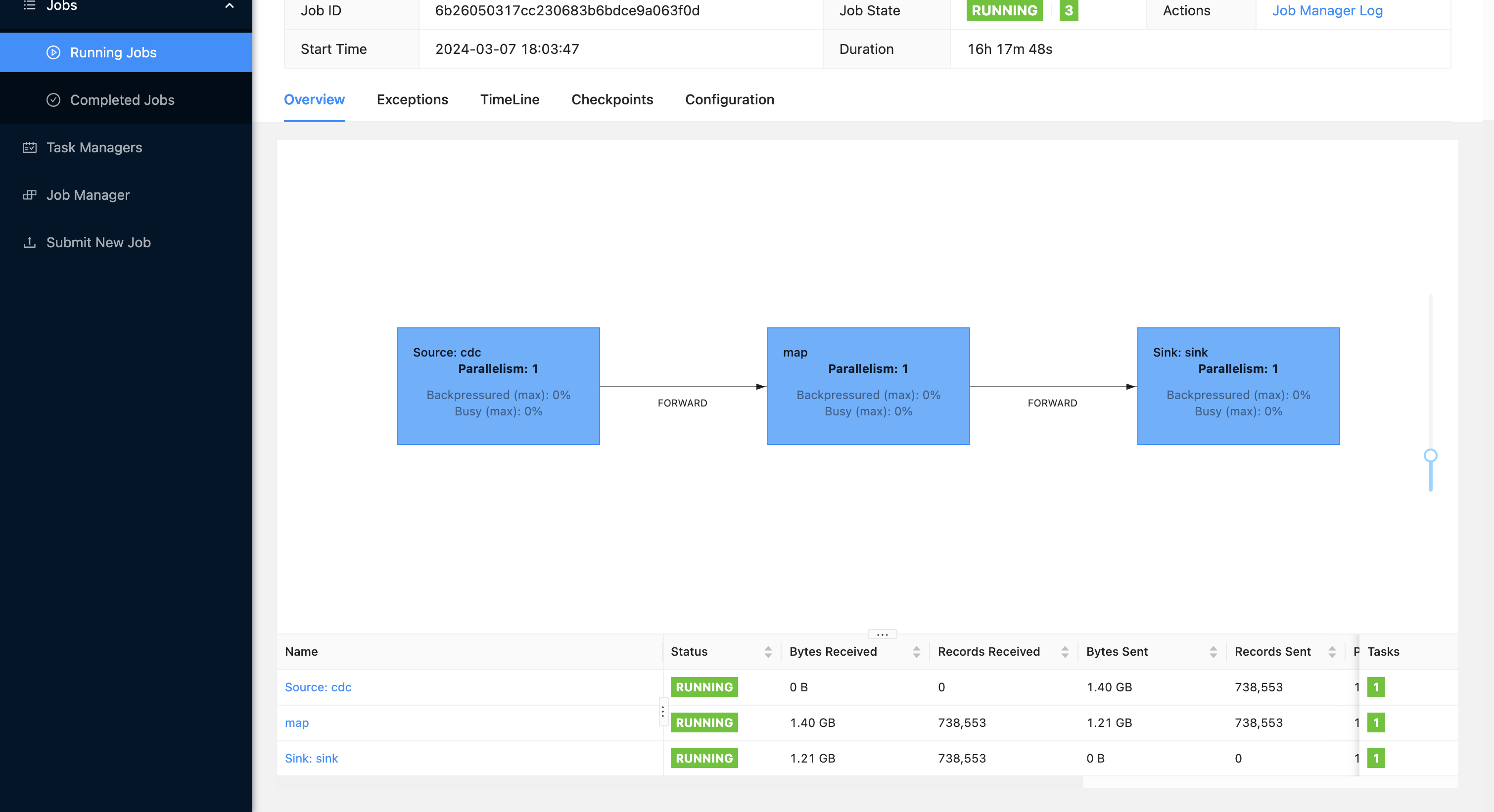
flink web 任务详情:
taskmanager gc(任务跑了 16 小时):
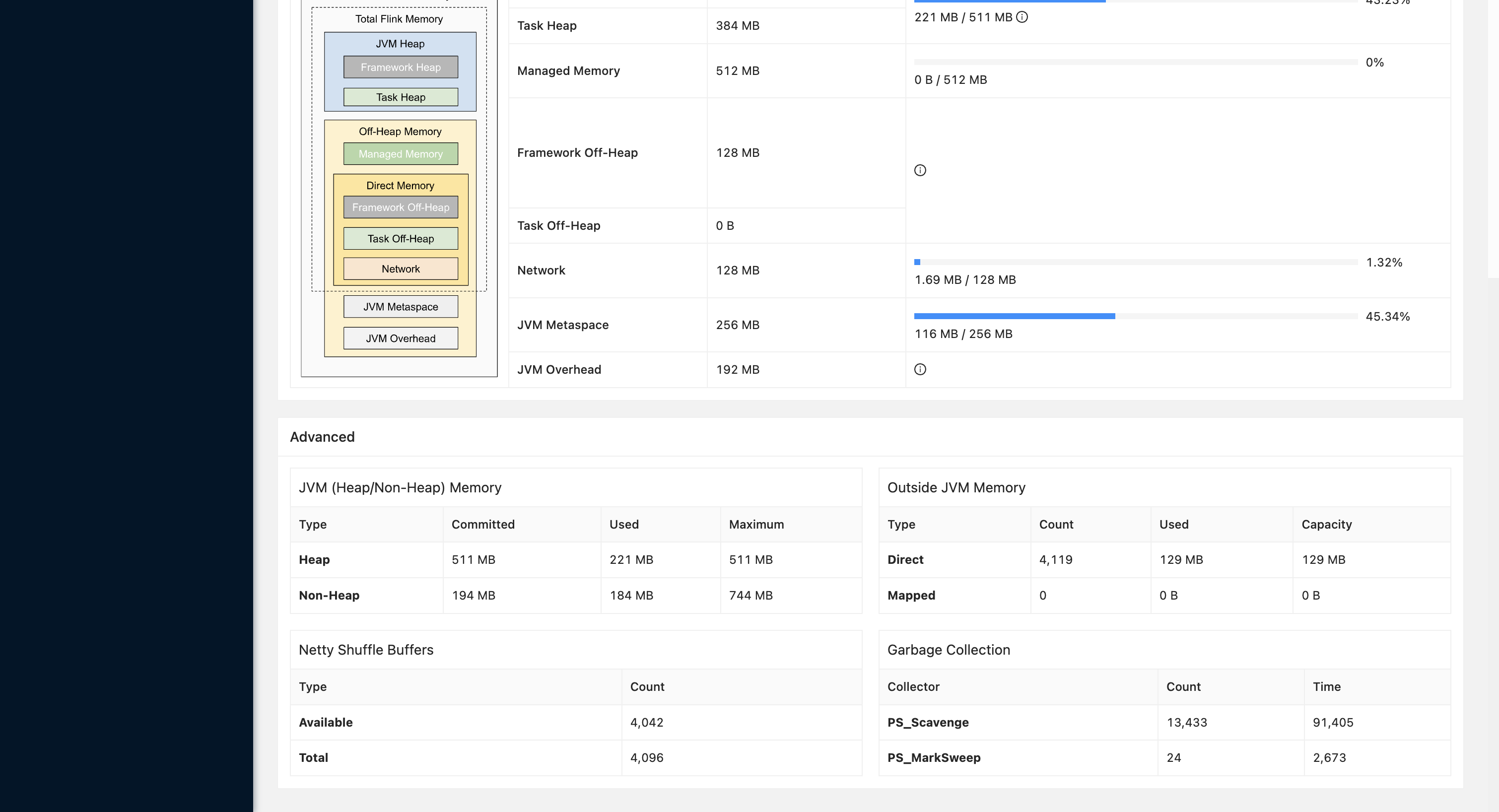
同步的表数据量都是千万,但是增量都不太大,预测 1 个 yarn 的 container (4 G内存),可以跑 10 个以上的任务
完整代码参考: github flink-rookie
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号