
这段时间开始调研使用 StarRocks 做准实时数据仓库:flink cdc 实时同步数据到 StarRocks,然后在 StarRocks 中做分层计算,直接把 StarRocks 中的 ADS 层提供给 BI 查询。架构如下:
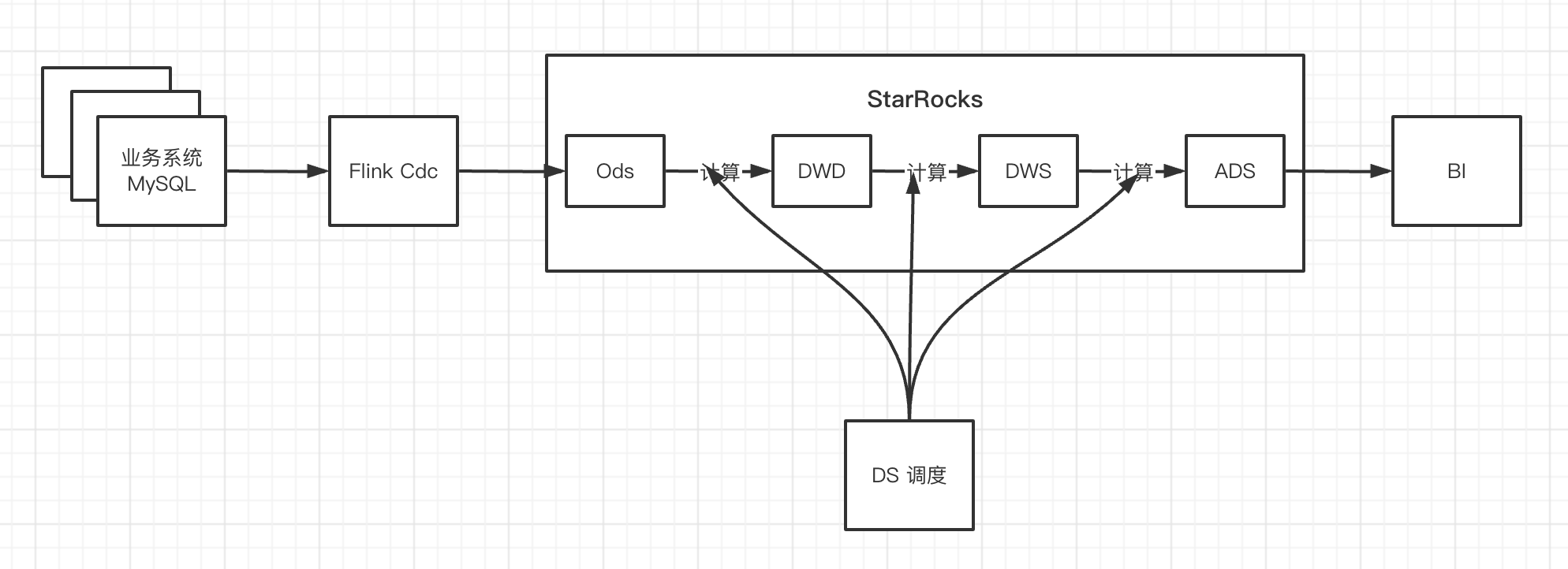
由于用到的表比较多,不能用 Flink SQL 给每个表都做个 CDC 的任务(任务太多不好维护、对数据库又可能有些压力),就用 Flink Stream Api 写了个 MySQL 整库同步到 StarRocks 的任务。
整体思路
- Flink cdc 采集 mysql 数据
- 将 cdc 采集到的数据转为 json
- 从 json 中获取 数据库、表和数据
- 用数据库和表对数据做 key by
- 使用 process function 处理每个表的数据,用状态缓存数据,缓存数据达到一定量或者缓存了一定时间(用 timer 触发缓存时间触发的场景)StarRocks 写数据
- sink 中拼接数据 使用 Stream Load 往 StarRocks 写数据
![]()
版本
Flink:1.14.4
StarRocks: 2.3.1
代码
主类 CdcToStarRocks
主要流程很简单: source -> map -> keyBy -> process -> sink,source 读取 mysql binlog(或者全量+增量),map 转换数据格式,keyBy 以数据库名 + 表名对数据分区,process 中对数据攒批,sink 输出数据到 StarRocks
核心代码如下:
env
.fromSource(sourceFunction, WatermarkStrategy.noWatermarks(), "cdc")
.name("source")
.uid("source")
// json 字符串转 CdcRecord
.map(new CdcStarMapFunction())
.name("map")
.keyBy( record -> record.getDb() + "_" + record.getTable())
.process(new CdcStarProcessFunction(batchSize, batchInterval))
.name("process")
.uid("process")
.addSink(new StarRocksSink(starrocksIp, starrocksPort, starrocksLoadPort, starrocksUser, starrocksPass, starrocksDb))
.name("sink");
Cdc Source
source 部分就是 flink cdc connector,监控一个数据库,用自定义的 CommonStringDebeziumDeserializationSchema 把 Debezium 格式的 SourceRecord, 转成 json 字符串
MySqlSource<String> sourceFunction = MySqlSource.<String>builder()
.hostname(ip)
.port(port)
// 获取两个数据库的所有表
.databaseList(db)
.tableList(table)
.username(user)
.password(pass)
.startupOptions(StartupOptions.latest())
// do not cache schema change
.includeSchemaChanges(false)
// .startupOptions(StartupOptions.initial())
// 自定义 反序列化器,将数据解析成 json
.deserializer(new CommonStringDebeziumDeserializationSchema(ip, port))
.build();
反序列化器 CommonStringDebeziumDeserializationSchema
反序列化器直接拿之前写的通用的 flink cdc 反序列化器过来,继承 DebeziumDeserializationSchema,主要是从数据中获取 数据库、表、操作类型和数据,需求特别注意以下几点:
- insert 类型的操心,只需要获取 after 中的数据
- update 类型的操作,需要同时解析 before 和 after 的数据,before 是修改前的,after 是修改后的,如果不需要修改前的,可以只获取 after
- delete 类型的操作,需要获取 before
- 如果有 ddl 操作,需要特殊处理(本次不包含)
转换成的 json:
insert 操作的数据:
{"host":"localhost","binlog":"","offset":"0","ts_sec":1665557408,"port":3306,"file":"","pos":0,"db":"venn","table":"user_log","operator_type":"r","after":{"id":47182,"user_id":8276240000,"item_id":10307,"category_id":10,"behavior":"buy","ts":"2022-07-28T03:29:30Z","create_time":"2022-07-28T03:29:49Z"},"parse_time":1665557412}
update 操作的数据:
{"host":"localhost","binlog":"binlog.000022","offset":"19183","ts_sec":1665557541,"port":3306,"file":"binlog.000022","pos":19183,"db":"venn","table":"user_log","operator_type":"u","after":{"id":47182,"user_id":8276240000,"item_id":10307,"category_id":10,"behavior":"view","ts":"2022-07-28T03:29:30Z","create_time":"2022-07-28T03:29:49Z"},"before":{"id":47182,"user_id":8276240000,"item_id":10307,"category_id":10,"behavior":"buy","ts":"2022-07-28T03:29:30Z","create_time":"2022-07-28T03:29:49Z"},"parse_time":1665557541}
delete 操作的数据:
{"host":"localhost","binlog":"binlog.000022","offset":"19571","ts_sec":1665557563,"port":3306,"file":"binlog.000022","pos":19571,"db":"venn","table":"user_log","operator_type":"d","before":{"id":47182,"user_id":8276240000,"item_id":10307,"category_id":10,"behavior":"view","ts":"2022-07-28T03:29:30Z","create_time":"2022-07-28T03:29:49Z"},"parse_time":1665557564}
核心代码:
public void deserialize(SourceRecord record, Collector<String> out) {
JsonObject jsonObject = new JsonObject();
String binlog = record.sourceOffset().get("file").toString();
String offset = record.sourceOffset().get("pos").toString();
String ts_sec = record.sourceOffset().get("ts_sec").toString();
// System.out.println("binlog : " + binlog + ", offset = " + offset);
// todo get schame change
jsonObject.addProperty("host", host);
// add meta
jsonObject.addProperty("binlog", binlog);
jsonObject.addProperty("offset", offset);
jsonObject.addProperty("ts_sec", ts_sec);
jsonObject.addProperty("port", port);
jsonObject.addProperty("file", (String) record.sourceOffset().get("file"));
jsonObject.addProperty("pos", (Long) record.sourceOffset().get("pos"));
jsonObject.addProperty("ts_sec", (Long) record.sourceOffset().get("ts_sec"));
String[] name = record.valueSchema().name().split("\\.");
jsonObject.addProperty("db", name[1]);
jsonObject.addProperty("table", name[2]);
Struct value = ((Struct) record.value());
String operatorType = value.getString("op");
jsonObject.addProperty("operator_type", operatorType);
// c : create, u: update, d: delete, r: read
// insert update
if (!"d".equals(operatorType)) {
Struct after = value.getStruct("after");
JsonObject afterJsonObject = parseRecord(after);
jsonObject.add("after", afterJsonObject);
}
// update & delete
if ("u".equals(operatorType) || "d".equals(operatorType)) {
Struct source = value.getStruct("before");
JsonObject beforeJsonObject = parseRecord(source);
jsonObject.add("before", beforeJsonObject);
}
jsonObject.addProperty("parse_time", System.currentTimeMillis() / 1000);
out.collect(jsonObject.toString());
}
转换函数 CdcStarMapFunction
CdcStarMapFunction 比较简单,将 json 字符串,转成 CdcRecord 类型的对象,只获取了需要的 数据库、表、操作类型和数据。
获取数据时,insert 和 update 只获取 after 的值
- 代码忽略
public class CdcRecord {
private String db;
private String table;
private String op;
private Map<String, String> data = new LinkedHashMap<>();
}
处理函数 CdcStarProcessFunction
CdcStarProcessFunction 有三部分逻辑:
- 三个状态cacheTimer、cacheSize、cache,分别存下一次timer 触发时间、缓存的数据条数、缓存的数据
- process 处理每个表的数据,每个表的数据第一次到的时候,基于当前时间 + batchInterval,注册下次时间触发的 timer。数据存储到 cache 中,如果数据量超过预定的 batchSize,触发 flushData 方法往下游输出数据,并删除之前注册的定时器,清理状态
- timer 触发 flushData 方法往下游输出数据,清理状态
@Override
public void processElement(CdcRecord element, KeyedProcessFunction<String, CdcRecord, List<CdcRecord>>.Context ctx, Collector<List<CdcRecord>> out) throws Exception {
// cache size + 1
if(cacheSize.value() != null){
cacheSize.update(cacheSize.value() + 1);
}else{
cacheSize.update(1);
// add timer for interval flush
long nextTimer = System.currentTimeMillis() + batchInterval;
cacheTimer.update(nextTimer);
ctx.timerService().registerProcessingTimeTimer(nextTimer);
}
// add data to cache state
cache.add(element);
// cache size max than batch Size
if(cacheSize.value() > batchSize){
// remove next timer
ctx.timerService().deleteEventTimeTimer(cacheTimer.value());
// flush data to down stream
flushData(out);
}
}
/**
* flush data to down stream
*/
private void flushData(Collector<List<CdcRecord>> out) throws Exception {
List<CdcRecord> tmpCache = new ArrayList<>();
Iterator<CdcRecord> it = cache.get().iterator();
while (it.hasNext()){
tmpCache.add(it.next());
}
out.collect(tmpCache);
// finish flush all cache data, clear state
cache.clear();
cacheSize.clear();
cacheTimer.clear();
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction<String, CdcRecord, List<CdcRecord>>.OnTimerContext ctx, Collector<List<CdcRecord>> out) throws Exception {
LOG.info("{} trigger timer to flush data", ctx.getCurrentKey());
// batch interval trigger flush data
flushData(out);
}
输出函数 StarRocksSink
StarRocksSink 稍微复杂一点,需要基于数据中的表名,去目标数据库中获取对应的表结构(为了避免每次查询数据库,将获取到的表结构存到内存中),基于目标表的字段顺序从数据中获取对应列的值,拼接上数据的操作类型。
-
StarRocksSink 在往 StarRocks 写数据的时候,实现了 upsert 和 delete 操作,需要在数据中拼接上 0/1,0 代表 UPSERT 操作,1 代表 DELETE 操作
-
见参考文档1
invoke 方法
StarRocksSink 的核心逻辑都在 invoke 方法中,逻辑如下:
- 从数据中获取数据库和表,拼接成 key
- 获取目标表的 schema(整库映射,源端和目标端表名一致),先从缓存中获取,如果不存在就从数据库中获取
- 组装数据
- 拼接 load url
- 用 http 方式往 StarRocks 写数据
invoke 方法代码如下:
public void invoke(List<CdcRecord> element, Context context) throws Exception {
LOG.info("write batch size: " + element.size());
// use StarRocks db name
// String db = cache.get(0).getDb();
String table = element.get(0).getTable();
String key = db + "_" + table;
// get table schema
List<String> columnList;
if (!columnMap.containsKey(key)) {
// db.table is first coming, load column, put to spliceColumnMap & columnMap
loadTargetTableSchema(key, db, table);
}
String columns = spliceColumnMap.get(key);
columnList = columnMap.get(key);
if (columnList.size() == 0) {
LOG.info("{}.{} not exists in target starrocks, ingore data change", db, table);
}
// make up data
String data = parseUploadData(element, columnList);
final String loadUrl = String.format("http://%s:%s/api/%s/%s/_stream_load", ip, loadPort, db, table);
String label = db + "_" + table + "_" + System.currentTimeMillis();
// send data to starrocks
doHttp(loadUrl, data, label, columns);
}
loadTargetTableSchema 方法
执行 desc db.table 获取目标表的表结构,组装成两种结果: 将所有列名用 "," 拼接成字符串,再拼接 "__op" 用于 http header 请求中标识数据的列;将所有列按顺序添加到 list 中,用于从源数据中获取对应列的数据
/**
* load table schema, parse to http column and column list for load source data
*/
private void loadTargetTableSchema(String key, String db, String table) throws SQLException {
List<String> columnList = new ArrayList<>();
StringBuilder builer = new StringBuilder();
try {
// load table schema
PreparedStatement insertPS = connection.prepareStatement("desc " + db + "." + table);
ResultSet result = insertPS.executeQuery();
while (result.next()) {
String column = result.getString(1);
builer.append(column).append(",");
columnList.add(column);
}
} catch (SQLException e) {
LOG.warn("load {}.{} schema error. {}", db, table, e.getStackTrace());
}
builer.append("__op");
String columns = builer.toString();
spliceColumnMap.put(key, columns);
columnMap.put(key, columnList);
}
parseUploadData 方法
用目标表列顺序,从数据中获取对应列的值,使用列分隔符拼接数据,最后基于操作类型拼接 0/1,删除拼接 1,其他类型拼接 0
private String parseUploadData(List<CdcRecord> cache, List<String> columnList) {
StringBuilder builder = new StringBuilder();
for (CdcRecord element : cache) {
Map<String, String> data = element.getData();
for (String column : columnList) {
if (data.containsKey(column)) {
builder.append(data.get(column)).append(COL_SEP);
} else {
// if target column not exists in source data, set as null
builder.append(NULL_COL).append(COL_SEP);
}
}
// add __op
if ("d".equals(element.getOp())) {
// delete
builder.append("1");
} else {
// upsert
builder.append("0");
}
// add row separator
builder.append(ROW_SEP);
}
// remove last row sep
builder = builder.delete(builder.length() - 5, builder.length());
String data = builder.toString();
return data;
}
doHttp 方法
用 http 的方式往 StarRocks 中写数据,没什么特别的,忽略
运行与测试
待同步的本地数据库:
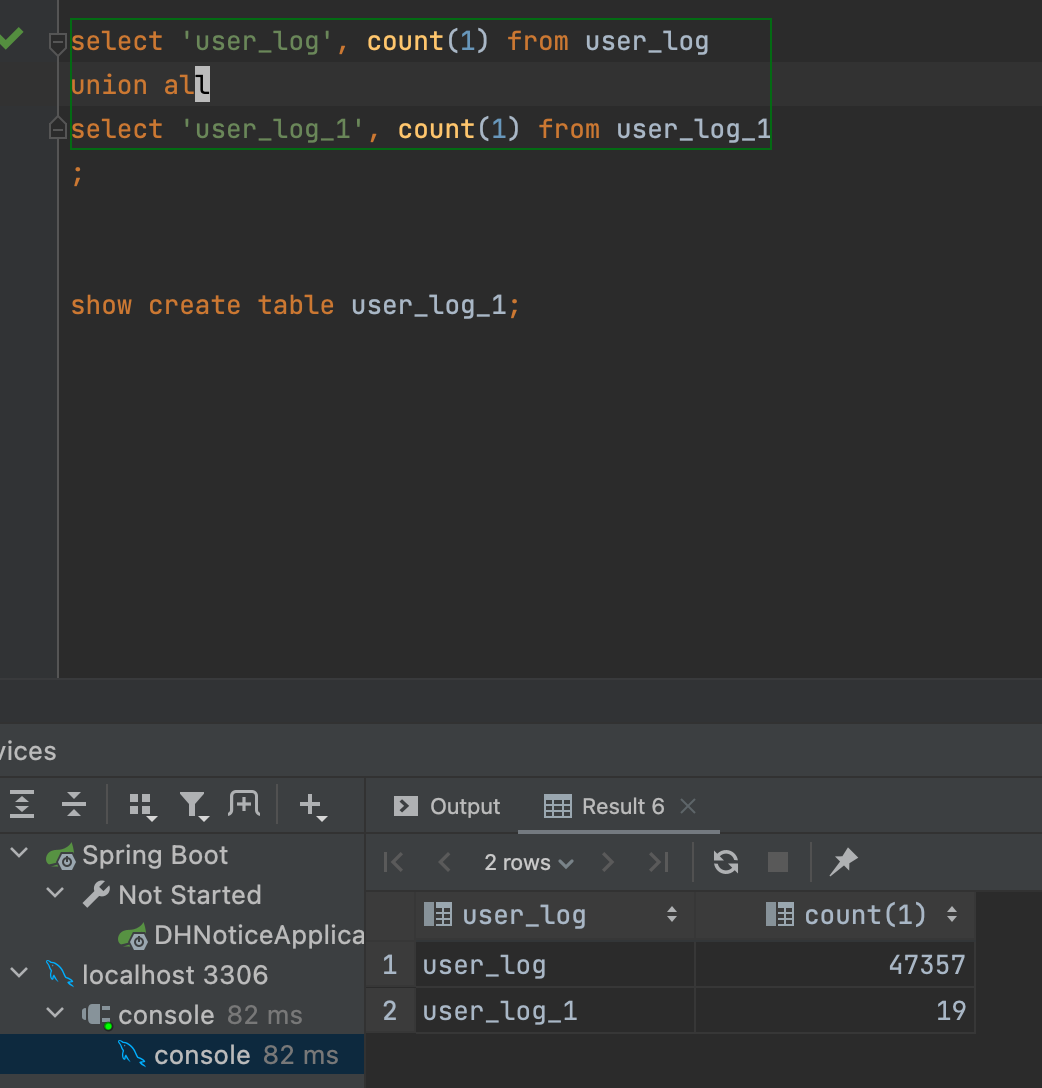
测试选取了数据库中的两个表: user_log 和 user_log_1,目标数据库中只创建这两个表(代码中有控制,如果获取不到表结构,会忽略对应表的数据导入操作)
测试全量同步
修改 cdc source 参数,改为 initial,启动任务初始化同步所有历史数据到 StarRocks 中 :
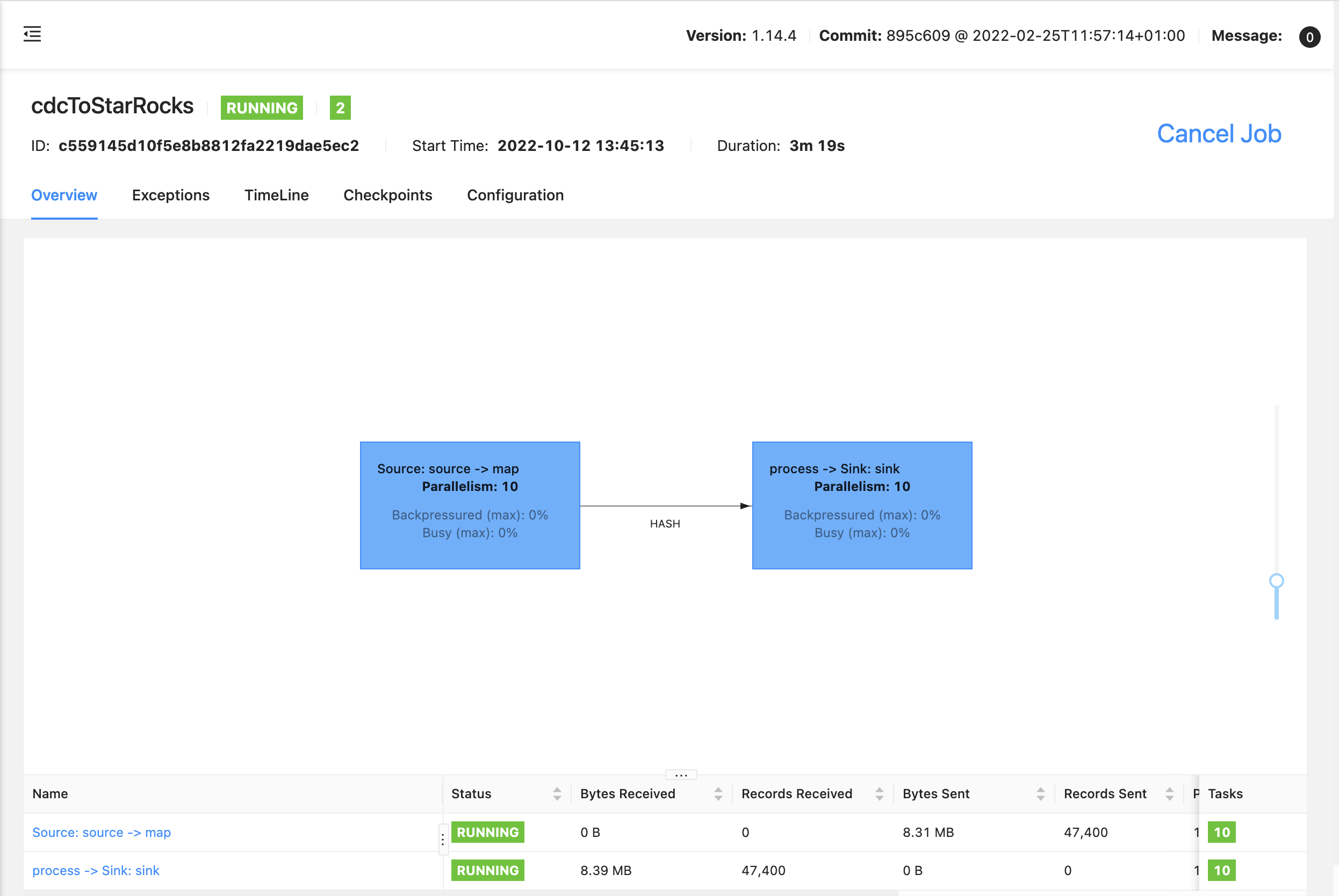
查看目标库 user_log 和 user_log_1 数据量:

可以看到表 user_log 和 user_log_1 的全部数据都同步到 StarRocks 中
目标库不存在的表,sink 时过滤:
write batch size: 1
write batch size: 1
write batch size: 3
write batch size: 3
write batch size: 10
test.pv_uv not exists in target starrocks, ingore data change
test.user_info_sink not exists in target starrocks, ingore data change
test.lookup_join_config_1 not exists in target starrocks, ingore data change
test.lookup_join_config not exists in target starrocks, ingore data change
test.tbls not exists in target starrocks, ingore data change
测试插入数据
往 user_log 和 user_log_1 插入一条数据:
insert into user_log(id, user_id, item_id, category_id, behavior, ts, create_time)
select 1008017 id
, 1008611 user_id
, 1011 item_id
, 11 category_id
, 'view' behavior
,now() ts
,now() create_time
;
insert into user_log_1(id, user_id, item_id, category_id, behavior, ts, create_time)
select 1008017 id
, 1008611 user_id
, 1011 item_id
, 11 category_id
, 'view' behavior
,now() ts
,now() create_time
;
查看程序日志,可以看到 user_log 和 user_log_1 各采集到了一条数据:
venn_user_log trigger timer to flush data
write batch size: 1
venn_user_log_1 trigger timer to flush data
write batch size: 1
查看 StarRocks user_log 和 user_log_1 表,新数据已经写入:

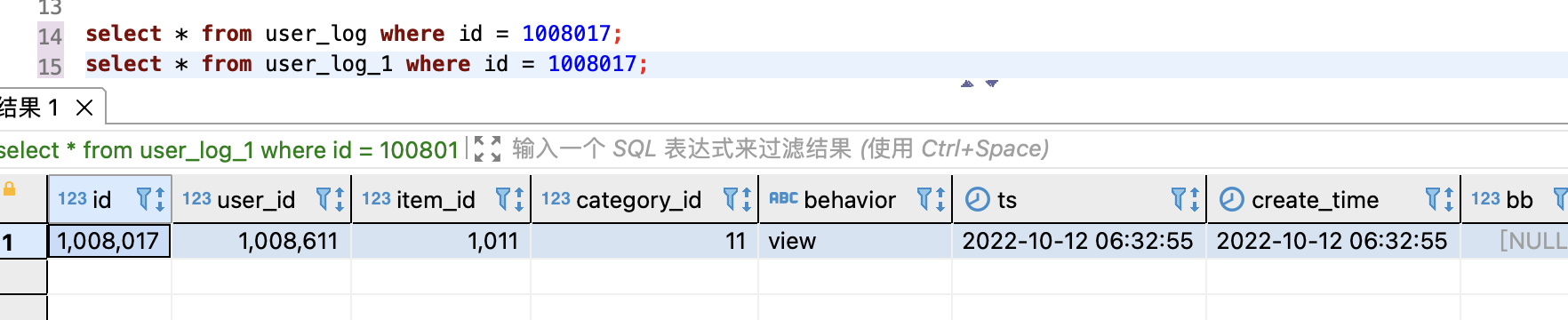
测试修改数据
分别修改两个表的数据:
update user_log set behavior = 'buy' where id = 1008017;
update user_log_1 set behavior = 'buy' where id = 1008017;
查看 StarRocks 中 user_log 和 user_log_1 表,对 id 1008017 的修改已经同步到 StarRocks 中:
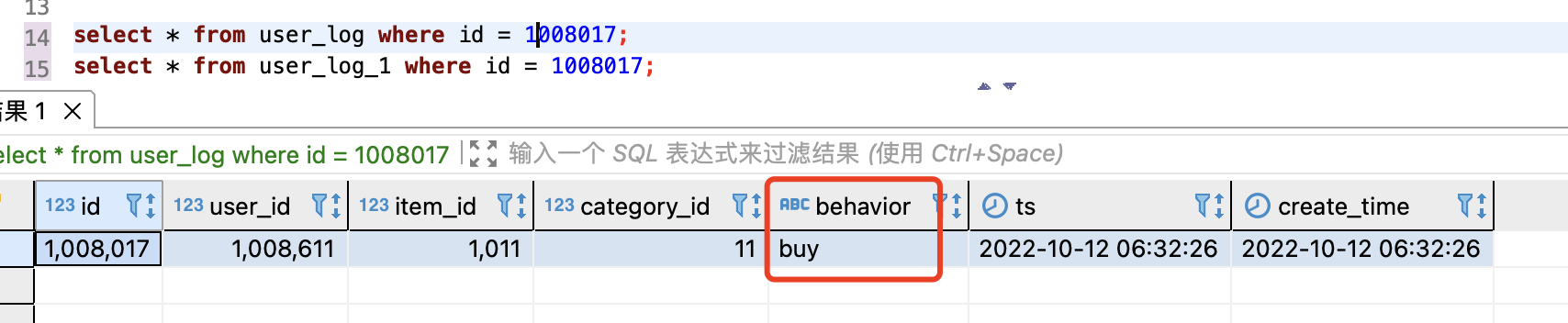

测试删除数据
直接删除 user_log 和 user_log_1 表中,刚写入的数据:
delete from user_log where id = 1008017;
delete from user_log_1 where id = 1008017;
查看 StarRocks 中 user_log 和 user_log_1 表,id 1008017 的数据已删除
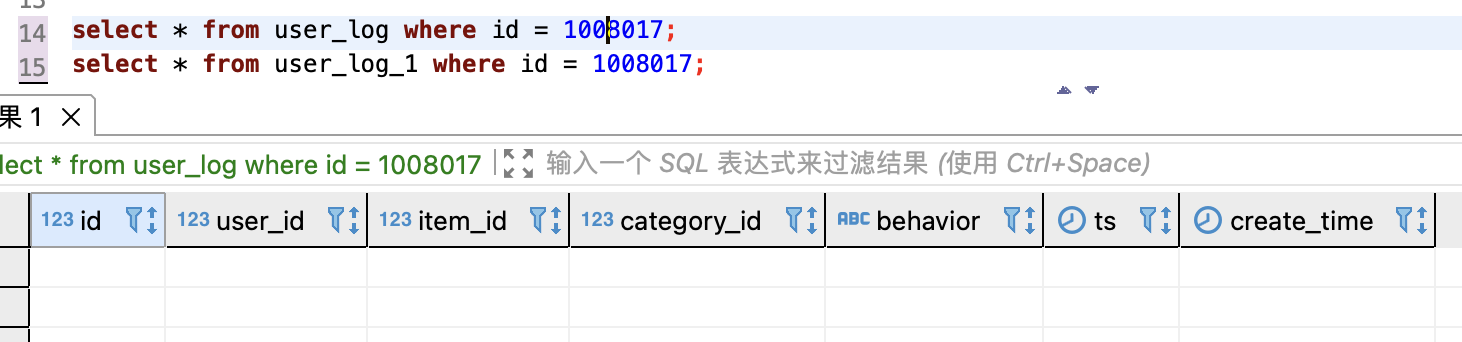
局限
- 还未实现 starrocks 端表结构跟随 源端表结构同步变更
- 为了保证效率,仅会在每一个表第一次来的时候判断目标段是否存在该表,如果已经判定该表不存在,后续直接忽略该表的数据变更
- 部分不导入的表,只在sink 的时候做了过滤,前面的操作还是要继续,可以考虑在 反序列化活map中过滤掉目标库中不存在的表数据
问题
1. 如果数据库中存在表没有主键,任务异常且不会读取后续数据,不报错
ChunkSplitter: org.apache.flink.table.api.ValidationException: Incremental snapshot for tables requires primary key, but table venn.columns_v2 doesn't have primary key.
参考文档
参考文档1:https://docs.starrocks.io/zh-cn/latest/loading/PrimaryKeyLoad#upsert-和-delete
完整代码参见 github: https://github.com/springMoon/flink-rookie
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号