
最近遇到个场景,需要对大表进行 Table Scan,使用官方的 jdbc connect, 发现在执行的时候,如果表的数据量很大(百万级别),在 select 阶段会消耗大量的时间,如下:
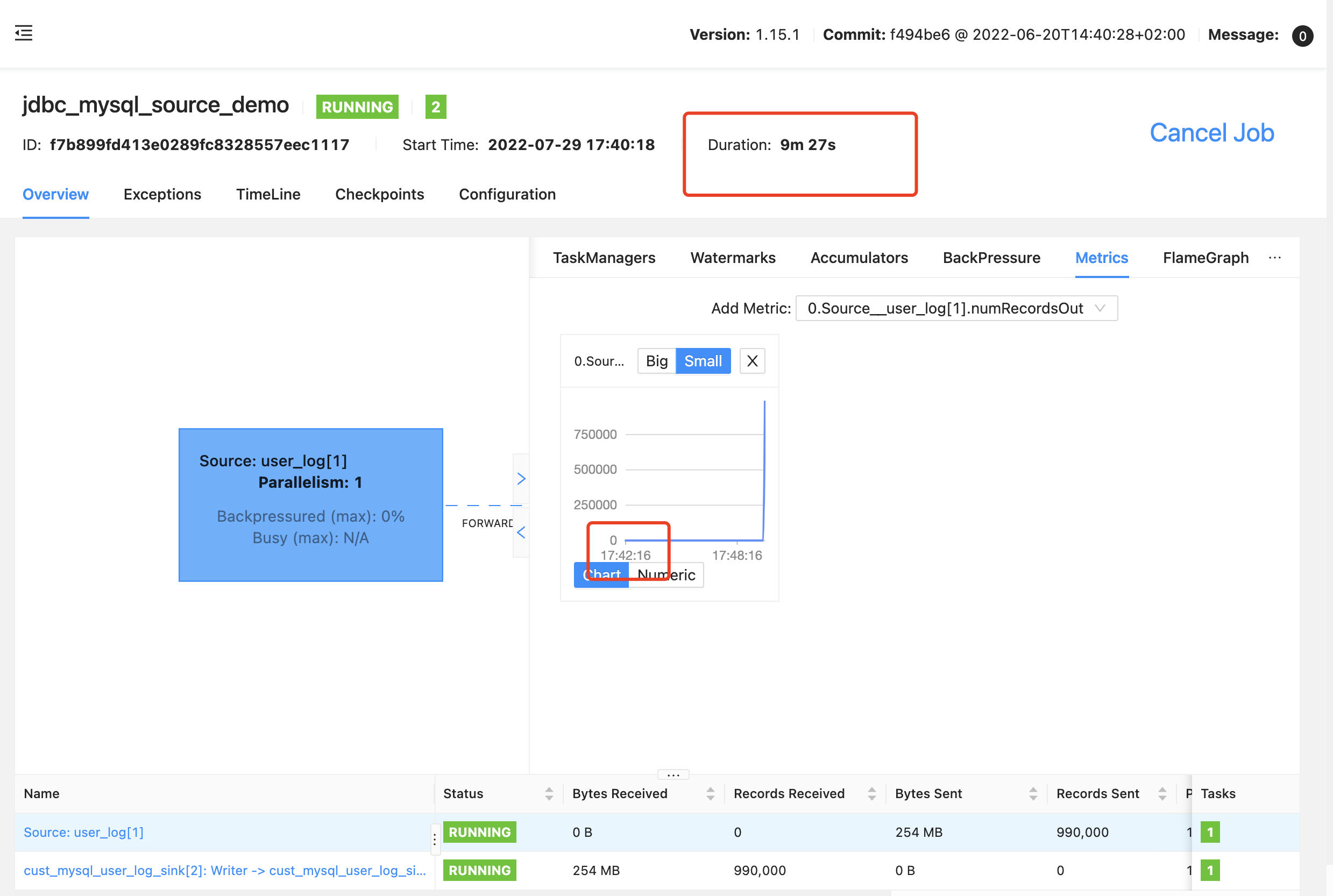
任务执行了 9 分钟多,数据才上来,数据上来后,差不多一批就全部上来了
差不多 10 分钟读完,还不能通过增加并行度的方式提高读取速度
并行 mysql source 实现
在自定义的 mysql lookup source 基础上添加 TableScan 的 Source
Source 继承 RichParallelSourceFunction
- 构造方法中接收配置参数
- open 方法中创建 jdbc 连接,基于主键查询表中的最大值,最小值
- run 方法中,基于任务的并行度,将数据按主键,均分给每个并行度
- 每个并行度分批次读取分给自己的数据
MysqlOption
并行 source,最重要的是基于键,将数据均分到每个并行度;同时在读取的时候,加入了批次概念,避免一次性读取太多数据(其实是抄的 flink cdc 的概念)
MysqlOption.java
public static final ConfigOption<Integer> TIME_OUT = ConfigOptions.key("timeout")
.intType()
.defaultValue(10);
public static final ConfigOption<Long> BATCH_SIZE = ConfigOptions.key("batch.size")
.longType()
.defaultValue(10000l)
.withDescription("if batch.size max than (totalsize / subtask num), set batch.size as (totalsize / subtask num)");
TableFactory
在 factory 中添加为非必需参数,因为是和 lookup source 共用的
MysqlDynamicTableFactory.optionalOptions
@Override
public Set<ConfigOption<?>> optionalOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
// no optional option
options.add(MysqlOption.CACHE_MAX_SIZE);
options.add(MysqlOption.CACHE_EXPIRE_MS);
options.add(MysqlOption.MAX_RETRY_TIMES);
options.add(MysqlOption.TIME_OUT);
// add for table scan source
options.add(MysqlOption.KEY);
options.add(MysqlOption.BATCH_SIZE);
return options;
}
DynamicTableSource
在 DynamicTableSource 中添加一个 TableScan 的 source
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext runtimeProviderContext) {
final SourceFunction<RowData> sourceFunction
= new MysqlSource(producedDataType, options);
return SourceFunctionProvider.of(sourceFunction, false);
}
MysqlSource
主要的逻辑都在 MysqlSource
open 方法
创建 jdbc 连接,获取基于主键的最大、最小值
counter = new SimpleCounter();
this.counter = getRuntimeContext()
.getMetricGroup()
.counter("myCounter");
// jdbc connection
conn = DriverManager.getConnection(this.options.getUrl(), this.options.getUsername(), this.options.getPassword());
// 获取主键
String key = this.options.getKey();
// 如果没有配置主键
if (key != null) {
// find min/max
String sql = "select min(" + key + ") as min, max(" + key + ") as max from " + this.options.getTable();
PreparedStatement ps = conn.prepareStatement(sql);
ResultSet resultSet = ps.executeQuery();
resultSet.next();
// todo cdc data split algorithm ChunkSplitter.splitTableIntoChunks
// flink cdc key only support number type
min = resultSet.getLong(1);
max = resultSet.getLong(2);
} else {
hasKey = false;
}
LOG.info("load table min {}, max {}", min, max);
run 方法
核心方法:计算当前并行度的数据范围,并执行查询
@Override
public void run(SourceContext<RowData> ctx) throws Exception {
// splicing query sql
String sql = makeupSql();
PreparedStatement ps = conn.prepareStatement(sql);
// Split by primary key for subtask
int index = getRuntimeContext().getIndexOfThisSubtask();
int total = getRuntimeContext().getNumberOfParallelSubtasks();
// cal current subtask data range, if not config key, data ranger (-1,0)
long size = (max - min);
long avg = (long) Math.floor(size / total);
if (this.options.getBatchSize() > size) {
this.batchSize = avg;
}
// subtask start index : min + index * 平均数量
long indexStart = min + index * avg;
long indexEnd = min + (index + 1) * avg;
// if index 是最大那个,把结尾哪些一块包含进去
if (index == total - 1) {
// include max id
indexEnd = max + 1;
}
LOG.info("subtask index : {}, data range : {} to {}, -1 means no split", index, indexStart, indexEnd);
// query data in batch
for (; indexStart < indexEnd; indexStart += batchSize) {
long currentEnd = indexStart + this.options.getBatchSize() > indexEnd ? indexEnd : indexStart + this.options.getBatchSize();
LOG.info("subtask index {} start process : {} to {}", index, indexStart, currentEnd);
if (hasKey) {
ps.setLong(1, indexStart);
ps.setLong(2, currentEnd);
}
ResultSet resultSet = ps.executeQuery();
// loop result set
while (isRunning && resultSet.next()) {
queryAndEmitData(ctx, resultSet);
}
// if no key, only exec once
if (!hasKey) {
break;
}
}
LOG.info("subtask {} finish scan", index);
}
查询数据库,发出结果
// 查询 数据库,发出返回结果
private void queryAndEmitData(SourceContext<RowData> ctx, ResultSet resultSet) throws SQLException {
GenericRowData result = new GenericRowData(fieldCount);
result.setRowKind(RowKind.INSERT);
for (int i = 0; i < fieldCount; i++) {
LogicalType type = rowType.getTypeAt(i);
String value = resultSet.getString(i + 1);
Object fieldValue = RowDataConverterBase.createConverter(type, value);
result.setField(i, fieldValue);
// out result
}
ctx.collect(result);
this.counter.inc();
}
构造 sql
private String makeupSql() {
StringBuilder builder = new StringBuilder();
builder.append("select ");
for (int i = 0; i < fieldCount; i++) {
if (i == fieldCount - 1) {
builder.append(fieldNames[i]).append(" ");
} else {
builder.append(fieldNames[i]).append(",");
}
}
builder.append("from ");
builder.append(this.options.getDatabase()).append(".");
builder.append(this.options.getTable());
if (hasKey) {
builder.append(" where " + this.options.getKey() + " >= ?");
builder.append(" and " + this.options.getKey() + " < ?");
}
return builder.toString();
}
测试
基于自定义的 TableScan source,查询一个 99 万数据的表
sql 如下:
create table cust_mysql_user_log
(
user_id STRING,
sex STRING,
age INTEGER,
degree STRING,
address STRING,
work_address STRING,
income_range STRING,
default_shipping_address STRING,
register_date TIMESTAMP(3)
) WITH (
'connector' = 'cust-mysql'
,'url' = 'jdbc:mysql://10.201.0.166:3306/shell1?useUnicode=true&characterEncoding=utf8&useSSL=false&allowPublicKeyRetrieval=true'
,'username' = 'root'
,'password' = 'daas2020'
,'database' = 'shell1'
,'table' = 'user_info'
-- ,'key' = 'id'
,'batch.size' = '10000'
)
;
create table cust_mysql_user_log_sink
(
user_id STRING,
sex STRING,
age INTEGER,
degree STRING,
address STRING,
work_address STRING,
income_range STRING,
default_shipping_address STRING,
register_date TIMESTAMP(3)
) WITH (
'connector' = 'kafka'
,'topic' = 'user_log_sink'
,'properties.bootstrap.servers' = 'localhost:9092'
,'properties.group.id' = 'user_log'
,'scan.startup.mode' = 'latest-offset'
,'format' = 'json'
)
;
insert into cust_mysql_user_log_sink
select user_id, sex, age, degree, address, work_address, income_range,default_shipping_address, register_date
from cust_mysql_user_log;
6并行度执行并查看结果(单并行度的执行没有意义)
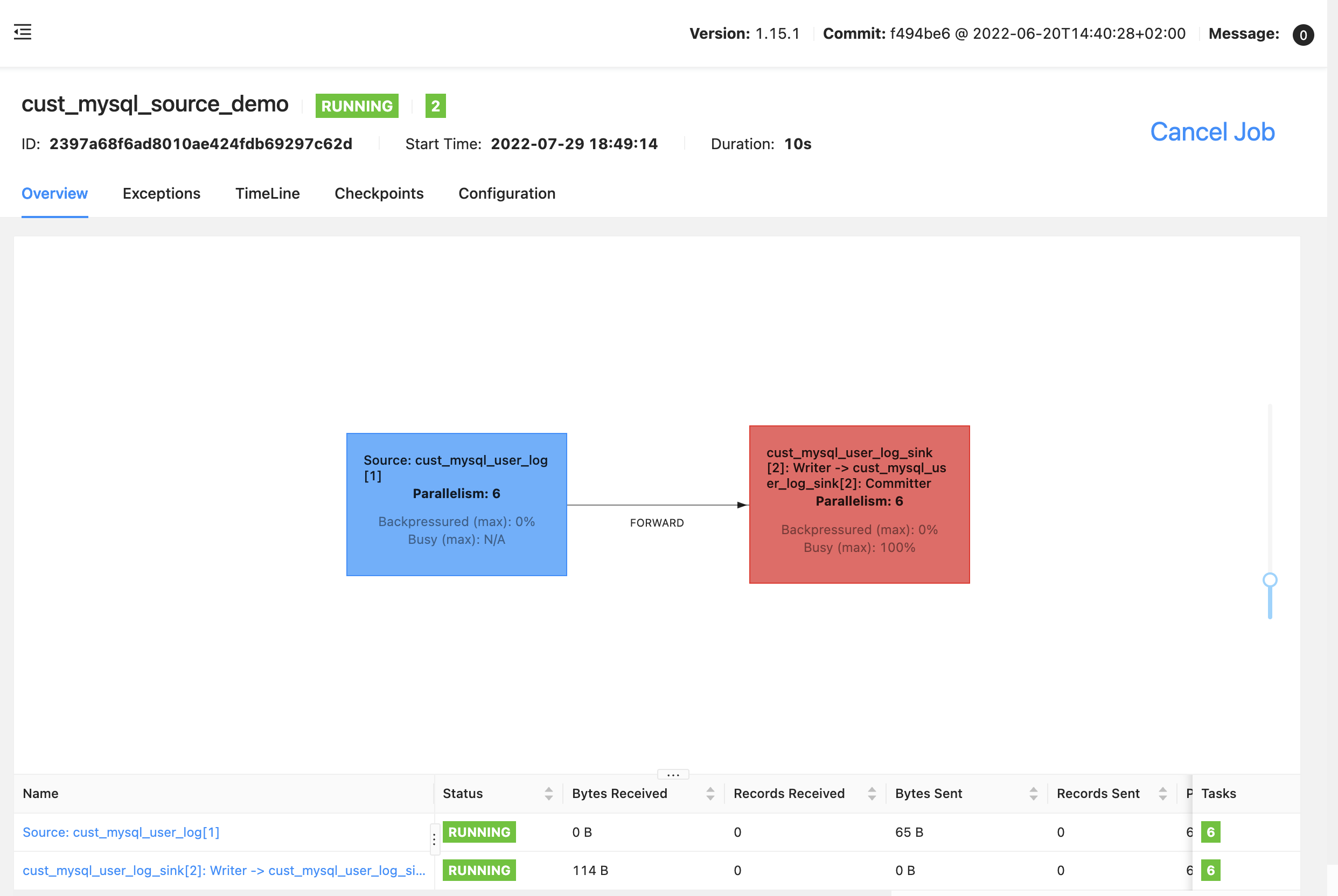
数据分片
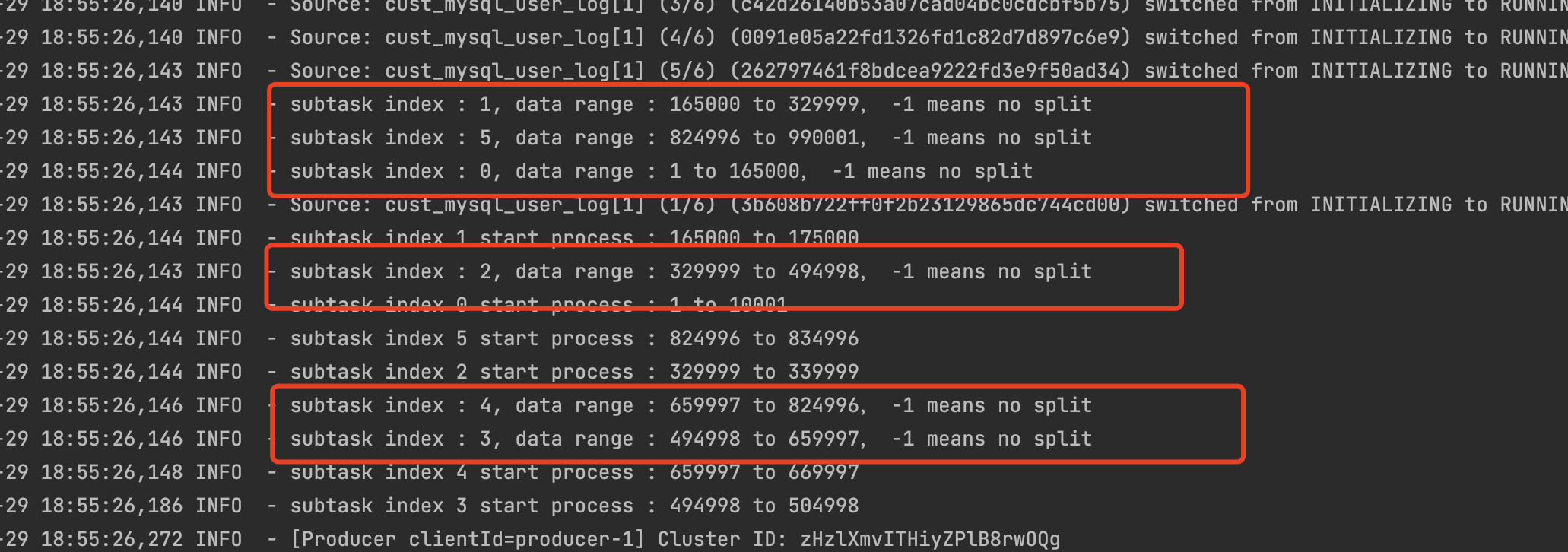
查看任务执行日志可以看到 1分半,数据就全部就读取完成了
2022-07-29 18:55:30,965 INFO - subtask index 3 start process : 504998 to 514998
2022-07-29 18:55:30,975 INFO - subtask index 4 start process : 669997 to 679997
2022-07-29 18:55:30,990 INFO - subtask index 1 start process : 175000 to 185000
2022-07-29 18:55:30,990 INFO - subtask index 0 start process : 10001 to 20001
2022-07-29 18:55:30,996 INFO - subtask index 5 start process : 834996 to 844996
2022-07-29 18:55:31,084 INFO - subtask index 2 start process : 339999 to 349999
2022-07-29 18:55:34,567 INFO - subtask index 1 start process : 185000 to 195000
.....
2022-07-29 18:56:48,251 INFO - subtask index 1 start process : 325000 to 329999
2022-07-29 18:56:50,902 INFO - subtask 1 finish scan
2022-07-29 18:56:52,590 INFO - subtask index 4 start process : 819997 to 824996
2022-07-29 18:56:53,657 INFO - subtask index 5 start process : 984996 to 990001
2022-07-29 18:56:55,418 INFO - subtask 4 finish scan
2022-07-29 18:56:56,356 INFO - subtask 5 finish scan
2022-07-29 18:57:02,572 INFO - subtask index 0 start process : 160001 to 165000
2022-07-29 18:57:02,861 INFO - subtask index 2 start process : 489999 to 494998
2022-07-29 18:57:03,451 INFO - subtask index 3 start process : 654998 to 659997
2022-07-29 18:57:04,079 INFO - subtask 0 finish scan
2022-07-29 18:57:04,325 INFO - subtask 2 finish scan
2022-07-29 18:57:04,836 INFO - subtask 3 finish scan
完整代码参数:github sqlSubmit
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号