
流表关联时数仓 DW 层把表打宽最主要的方式,项目中使用最多的维表存储是 hbase/mysql/redis,分别在大表、小表、高性能查询三种流表关联查询场景
最近调研和使用了一段时间的 starrocks,发现使用 starrocks 做维表的存储好像也很不错,所以做这样一次测试,测试 hbase/mysql/starrocks/redis 做维表的 tps 能达到什么级别,能否使用 starrocks 来替代 mysql、hbase。
测试服务器
CDH 6.2.1
服务器: 3 台 64G 16 核
CDH 所有组件都安装在这 3 台服务器上
流数据
测试流设计如下,从 kafka 读取数据,包含如下字段
CREATE TABLE user_log
(
user_id STRING,
item_id STRING,
category_id STRING,
behavior STRING,
page STRING,
position STRING,
sort STRING,
last_page STRING,
next_page STRING,
ts TIMESTAMP(3),
process_time as proctime(),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka'
,'topic' = 'user_behavior'
,'properties.bootstrap.servers' = 'localhost:9092'
,'properties.group.id' = 'user_log'
,'scan.startup.mode' = 'latest-offset'
,'format' = 'json'
);
维表设计
维表包含如下字段
user_id: 10位数字字符串,不足10位,补 0,反转
性别: man、woman、unknown
年龄:1-100 数字
学历:小学、初中、高中、本科、研究生、博士生
住址:uuid
工作地:uuid
收入范围:1-10 的随机数字
默认收货地址:uuid
注册时间:数据写入时间
修改时间:数据写入时间
维表写入流如下:
CREATE TABLE user_info
(
user_id STRING,
sex STRING,
age integer,
degree STRING,
address STRING,
work_address STRING,
income_range STRING,
default_shipping_address STRING,
register_date timestamp(3),
udpate_date TIMESTAMP(3),
) WITH (
'connector' = 'kafka'
,'topic' = 'user_behavior'
,'properties.bootstrap.servers' = 'dcmp10:9092,dcmp11:9092,dcmp12:9092'
,'properties.group.id' = 'user_log'
,'scan.startup.mode' = 'latest-offset'
,'format' = 'json'
);
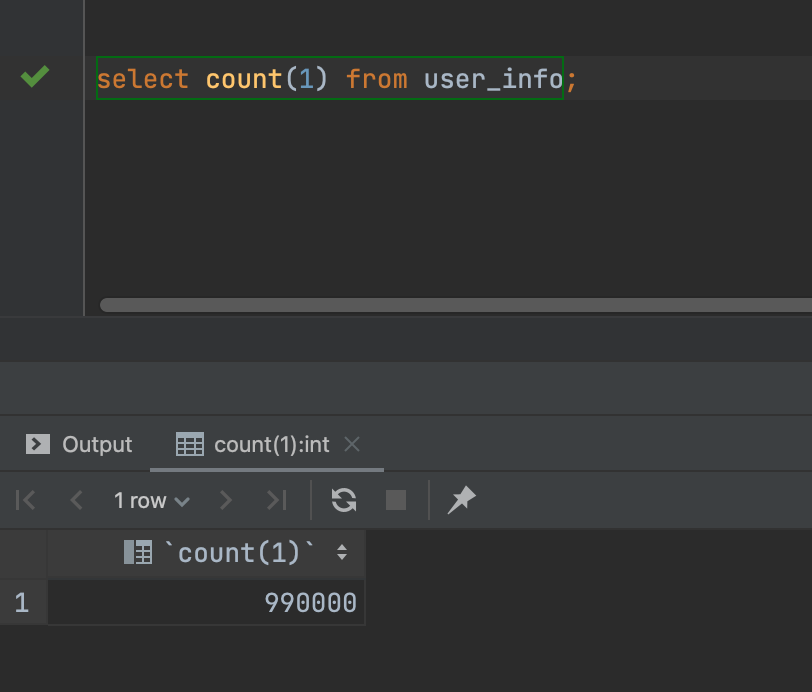
- 注:设计维表数据 100 万,实际写入 99 万条,剩下 1 万模拟流表关联找不到的情况
hbase 表
创建hbase 表
create 'user_info', { NAME => 'f',IN_MEMORY => 'true'}
写入数据
drop table if exists hbase_user_info_sink;
CREATE TABLE hbase_user_info_sink
(
user_id STRING,
f ROW(sex STRING,
age INTEGER,
degree STRING,
address STRING,
work_address STRING,
income_range STRING,
default_shipping_address STRING,
register_date TIMESTAMP(3),
udpate_date TIMESTAMP(3))
) WITH (
'connector' = 'hbase-2.2'
,'zookeeper.quorum' = 'dcmp10:2181,dcmp11:2181,dcmp12:2181'
,'zookeeper.znode.parent' = '/hbase'
,'table-name' = 'user_info'
,'sink.buffer-flush.max-size' = '10mb'
,'sink.buffer-flush.max-rows' = '2000'
);
insert into hbase_user_info_sink
select user_id, row(sex, age, degree, address, work_address, income_range,default_shipping_address, register_date, udpate_date)
from user_info;
hbase 数据
hbase(main):002:0> count 'user_info',INTERVAL=100000
(hbase):2: warning: already initialized constant INTERVAL
Current count: 100000, row: 1010090000
Current count: 200000, row: 2020190000
Current count: 300000, row: 3030290000
Current count: 400000, row: 4040390000
Current count: 500000, row: 5050490000
Current count: 600000, row: 6060590000
Current count: 700000, row: 7070690000
Current count: 800000, row: 8080790000
Current count: 900000, row: 9090890000
990000 row(s)
Took 30.5924 seconds
=> 990000
tpc 测试
测试sql 如下:
-- Lookup Source: Sync Mode
-- kafka source
CREATE TABLE user_log
(
user_id STRING,
item_id STRING,
category_id STRING,
behavior STRING,
page STRING,
`position` STRING,
sort STRING,
last_page STRING,
next_page STRING,
ts TIMESTAMP(3),
process_time as proctime(),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka'
,'topic' = 'user_log'
,'properties.bootstrap.servers' = 'dcmp10:9092,dcmp11:9092,dcmp12:9092'
,'properties.group.id' = 'user_log'
,'scan.startup.mode' = 'latest-offset'
,'format' = 'json'
);
drop table if exists hbase_behavior_conf;
CREATE
TEMPORARY TABLE hbase_behavior_conf (
user_id STRING,
f ROW(sex STRING,
age INTEGER,
degree STRING,
address STRING,
work_address STRING,
income_range STRING,
default_shipping_address STRING,
register_date TIMESTAMP(3),
udpate_date TIMESTAMP(3))
) WITH (
'connector' = 'hbase-2.2'
,'zookeeper.quorum' = 'dcmp10:2181,dcmp11:2181,dcmp12:2181'
,'zookeeper.znode.parent' = '/hbase'
,'table-name' = 'user_info'
,'lookup.cache.max-rows' = '100000'
,'lookup.cache.ttl' = '10 minute' -- ttl time 超过这么长时间无数据才行
,'lookup.async' = 'true'
);
---sinkTable
CREATE TABLE user_log_sink
(
user_id STRING,
item_id STRING,
category_id STRING,
behavior STRING,
page STRING,
`position` STRING,
sort STRING,
last_page STRING,
next_page STRING,
ts TIMESTAMP(3),
sex STRING,
age INTEGER,
degree STRING,
address STRING,
work_address STRING,
income_range STRING,
default_shipping_address STRING,
register_date TIMESTAMP(3),
udpate_date TIMESTAMP(3)
-- ,primary key (user_id) not enforced
) WITH (
'connector' = 'kafka'
,'topic' = 'user_log_sink'
,'properties.bootstrap.servers' = 'dcmp10:9092,dcmp11:9092,dcmp12:9092'
,'properties.group.id' = 'user_log'
,'scan.startup.mode' = 'group-offsets'
,'format' = 'json'
);
INSERT INTO user_log_sink
SELECT a.user_id
,a.item_id
,a.category_id
,a.behavior
,a.page
,a.`position`
,a.sort
,a.last_page
,a.next_page
,a.ts
,b.sex
,b.age
,b.degree
,b.address
,b.work_address
,b.income_range
,b.default_shipping_address
,b.register_date
,b.udpate_date
FROM user_log a
left join hbase_behavior_conf FOR SYSTEM_TIME AS OF a.process_time AS b
ON a.user_id = b.user_id
where a.behavior is not null;
一个并行度
配置 10 万的缓存(总量的 10%),失效时间是 10 分钟
由于是测试lookup join 的tps,所以这里只看 lookupJoin 算子的 tps,可以看到 tps 稳定在 2.5w 左右
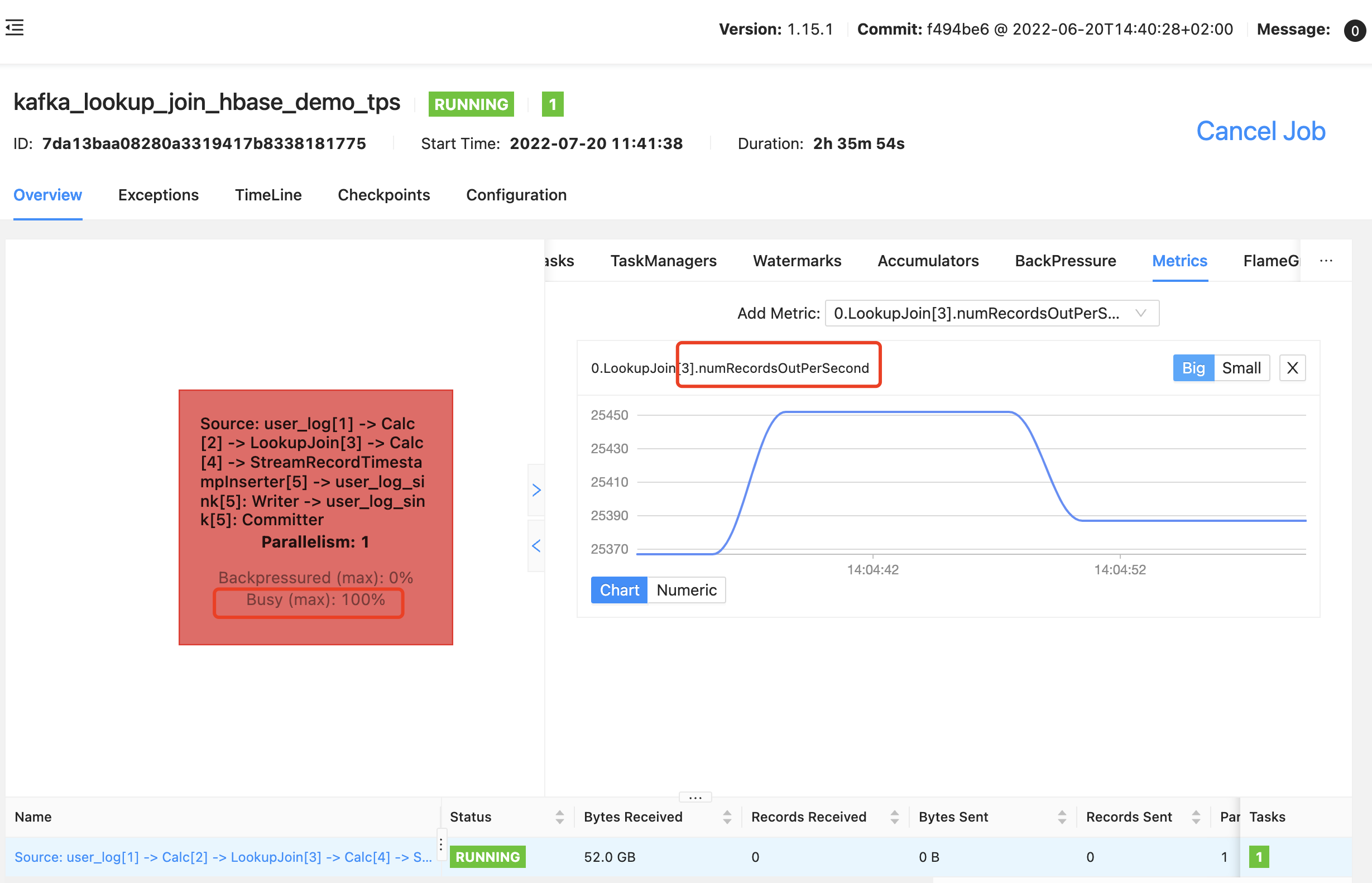
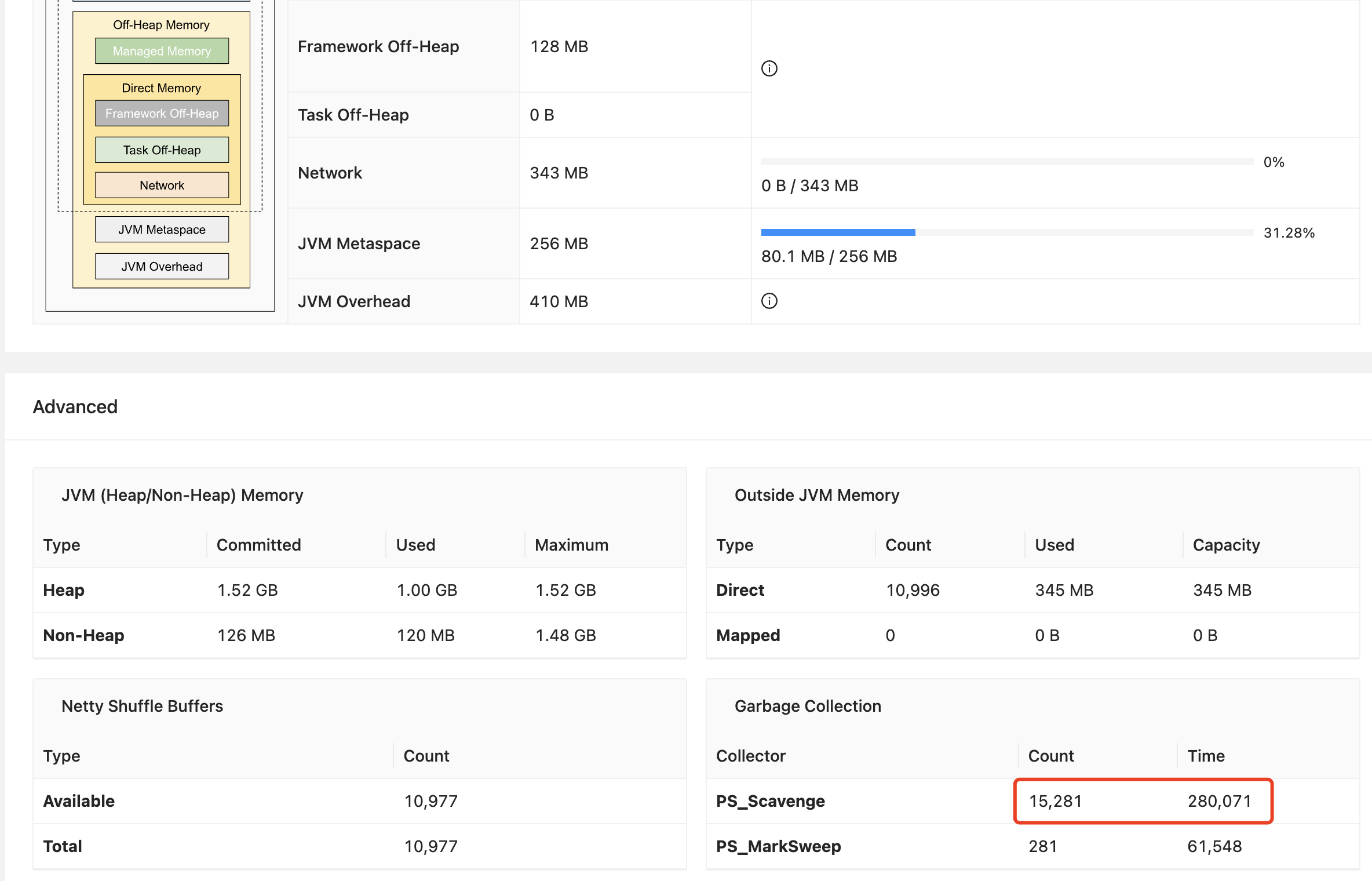
taskmanager 配置 4G 的内存,看起来 tasmnager 的 gc 有点严重,还能接受
三个并行度
同样配置,tps 最高可以跑到 6W,整体服务器 CPU 都跑到了 40%+

mysql
mysql 表结构
-- auto-generated definition
create table user_info
(
id int auto_increment
primary key,
user_id varchar(12) null,
sex varchar(10) null,
age int null,
degree varchar(10) null,
address varchar(50) null,
work_address varchar(50) null,
income_range varchar(50) null,
default_shipping_address varchar(50) null,
register_date datetime null,
udpate_date datetime null
)
comment '用户信息';
create index index_user_info_user_id
on user_info (user_id);
数据量 99 万
tpc 测试
drop table if exists mysql_behavior_conf;
CREATE
TEMPORARY TABLE mysql_behavior_conf (
user_id STRING,
sex STRING,
age INTEGER,
degree STRING,
address STRING,
work_address STRING,
income_range STRING,
default_shipping_address STRING,
register_date TIMESTAMP(3),
udpate_date TIMESTAMP(3)
) WITH (
'connector' = 'jdbc'
,'url' = 'jdbc:mysql://10.201.0.166:3306/shell1'
,'table-name' = 'user_info'
,'username' = 'root'
,'password' = 'daas2020'
,'lookup.cache.max-rows' = '100000'
,'lookup.cache.ttl' = '10 minute' -- ttl time 超过这么长时间无数据才行
);
---sinkTable
CREATE TABLE user_log_sink
(
user_id STRING,
item_id STRING,
category_id STRING,
behavior STRING,
page STRING,
`position` STRING,
sort STRING,
last_page STRING,
next_page STRING,
ts TIMESTAMP(3),
sex STRING,
age INTEGER,
degree STRING,
address STRING,
work_address STRING,
income_range STRING,
default_shipping_address STRING,
register_date TIMESTAMP(3),
udpate_date TIMESTAMP(3)
-- ,primary key (user_id) not enforced
) WITH (
'connector' = 'kafka'
,'topic' = 'user_log_sink'
,'properties.bootstrap.servers' = 'dcmp10:9092,dcmp11:9092,dcmp12:9092'
,'properties.group.id' = 'user_log'
,'scan.startup.mode' = 'group-offsets'
,'format' = 'json'
);
INSERT INTO user_log_sink
SELECT a.user_id
,a.item_id
,a.category_id
,a.behavior
,a.page
,a.`position`
,a.sort
,a.last_page
,a.next_page
,a.ts
,b.sex
,b.age
,b.degree
,b.address
,b.work_address
,b.income_range
,b.default_shipping_address
,b.register_date
,b.udpate_date
FROM user_log a
left join mysql_behavior_conf FOR SYSTEM_TIME AS OF a.process_time AS b
ON a.user_id = b.user_id
where a.behavior is not null;
mysql 数据百万(十万也差不多),加了索引和lookup 缓存,tps 稳定在 3600 左右 (GC 情况还比较好,就不贴图了)
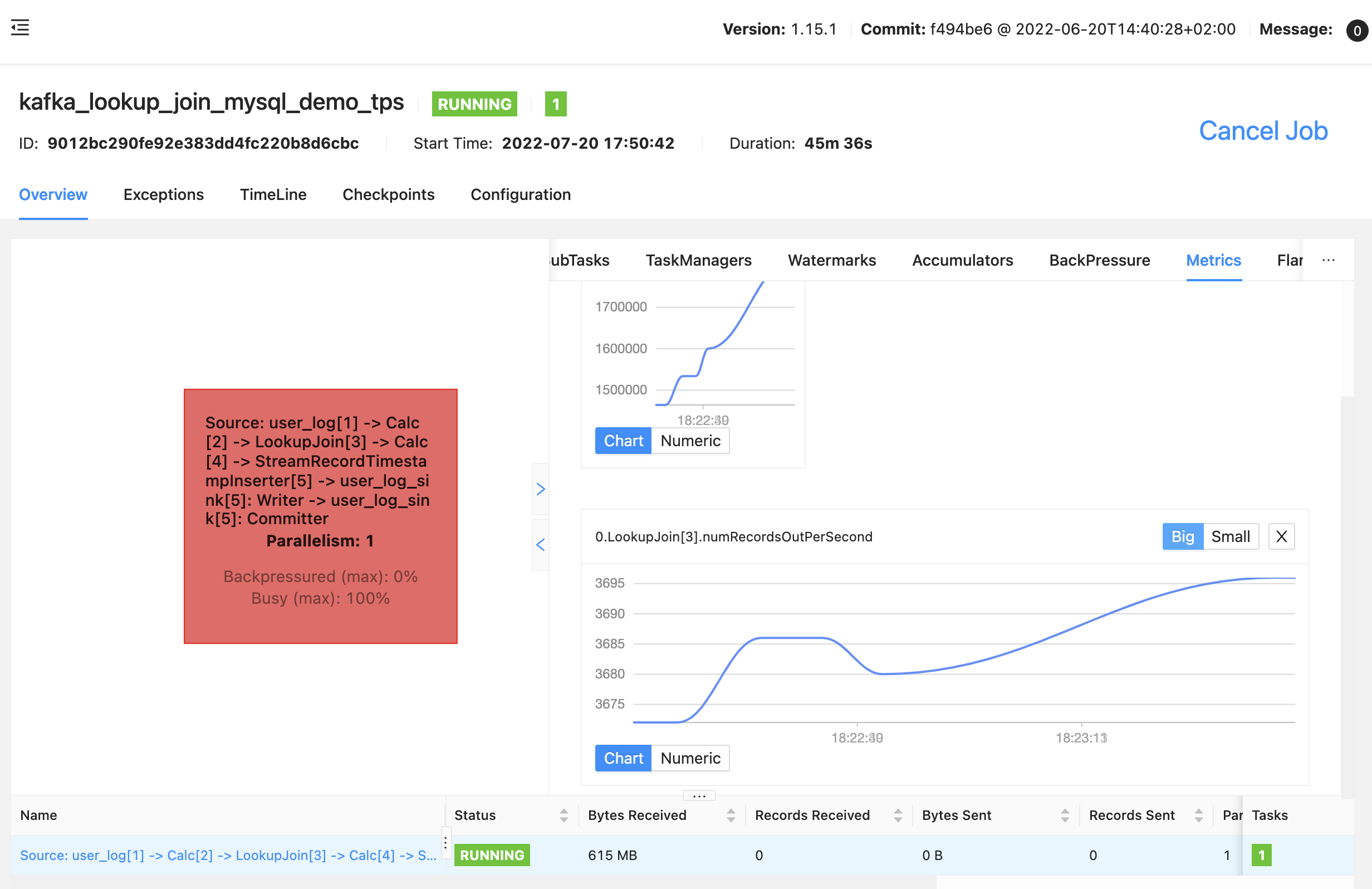
- 一个并行度就达到 mysql 的性能瓶颈,就不再测试多并行度的场景了
starrocks
万万没想到,starrocks 做维表是个战力只有 5 的渣渣,初步测试 tps 才 200 多,符合官网介绍,毕竟不是使用场景不同,跳过,跳过
redis
没环境跳过了
完整代码参考: github sqlSubmit
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号