
上篇:Flink sql Group Windows 窗口源码解析
下篇:Flink sql Windowing TVF 源码解析
之前在 sqlSubmit 项目里面添加了解析 sql 文件中的参数的功能
就随手在一个 window tvf 的 sql 里面添加了设置并行度为 2 的语句
set table.exec.resource.default-parallelism = 2;
然后就没管了
------------------ 分割线 -----------------
这两天在看 flink sql tvf 的源码,恰巧用到了这个sql
sql 如下:
--- test flink window parameter
set pipeline.name = test_table_parameter;
set table.exec.resource.default-parallelism = 2;
-- kafka source
drop table if exists user_log;
CREATE TABLE user_log
(
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp' VIRTUAL, -- from Debezium format
`partition_id` BIGINT METADATA FROM 'partition' VIRTUAL, -- from Kafka connector
`offset` BIGINT METADATA VIRTUAL, -- from Kafka connector
user_id VARCHAR,
item_id VARCHAR,
category_id VARCHAR,
behavior VARCHAR,
proc_time as PROCTIME(),
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '1' SECOND
) WITH (
'connector' = 'kafka'
,'topic' = 'user_log'
,'properties.bootstrap.servers' = 'localhost:9092'
,'properties.group.id' = 'user_log'
,'scan.startup.mode' = 'latest-offset'
,'format' = 'json'
);
drop table if exists user_log_sink_1;
CREATE TABLE user_log_sink_1
(
wCurrent string
,wStart STRING
,wEnd STRING
,pv bigint
,uv bigint
,user_max STRING
,primary key(wCurrent,wStart,wEnd) not enforced
) WITH (
-- 'connector' = 'print'
'connector' = 'upsert-kafka'
,'topic' = 'user_log_sink'
,'properties.bootstrap.servers' = 'localhost:9092'
,'properties.group.id' = 'user_log'
-- ,'scan.startup.mode' = 'latest-offset'
,'key.format' = 'json'
,'value.format' = 'json'
);
insert into user_log_sink_1
select 'window_tvf'
,date_format(window_start, 'yyyy-MM-dd HH:mm:ss') AS wStart
,date_format(window_end, 'yyyy-MM-dd HH:mm:ss') AS wEnd
,count(user_id) pv
,count(distinct user_id) uv
,behavior
FROM TABLE(
TUMBLE(TABLE user_log, DESCRIPTOR(ts), INTERVAL '10' second )) t1
group by window_start, window_end, behavior
;
程序流图:
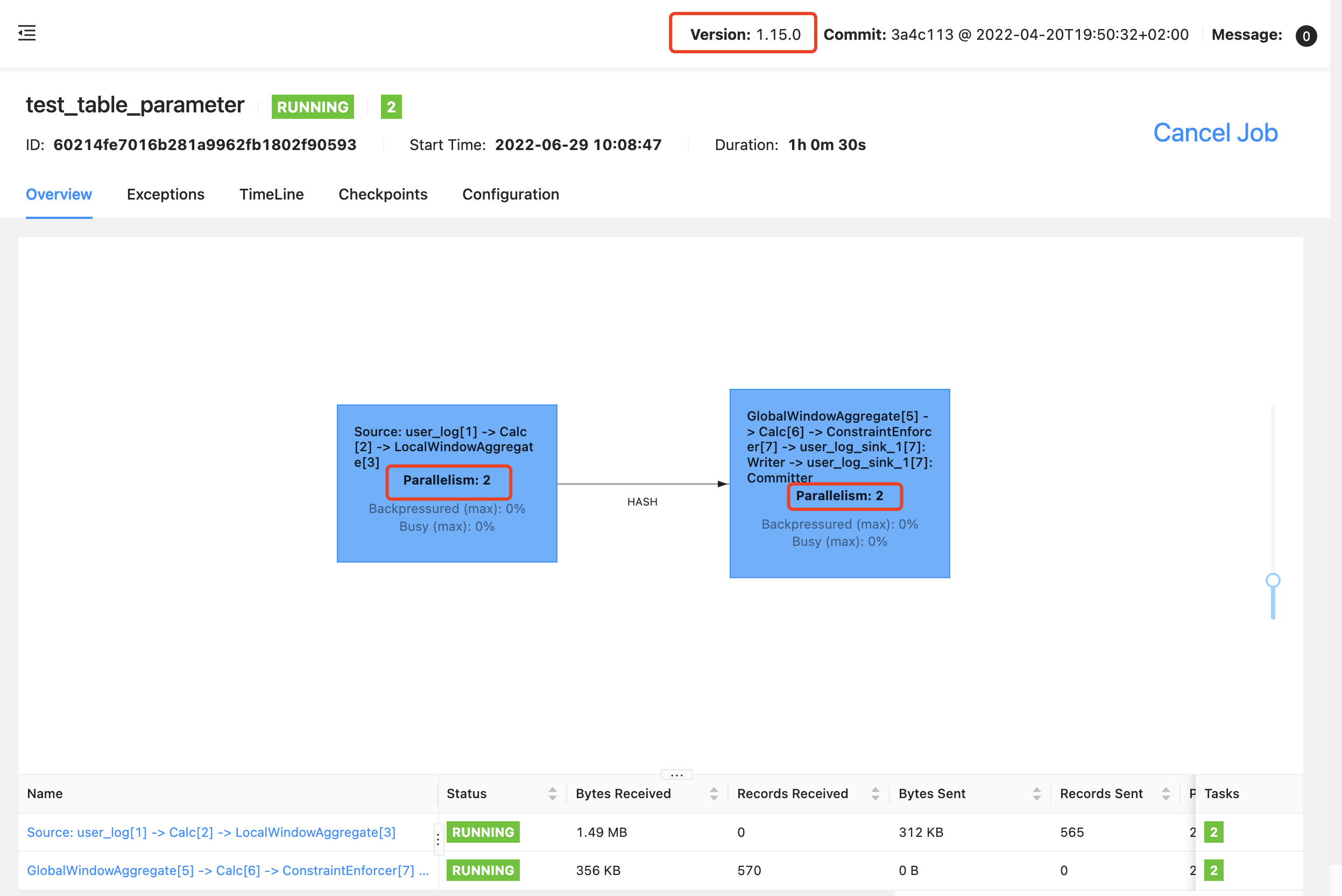
结果是输出到 kafka 的,最开始也没太在意输出的结果,没管有没有输出了
直到看到 SlicingWindowOperator ,具体数据处理的部分,在 onEventTime 方法上添加断点,想 debug 窗口计算部分的代码
onEventTime 方法竟然一直没有触发,查看 webui 算子 watermark 发现
GlobalWindowAggregate 算子的 watermark:
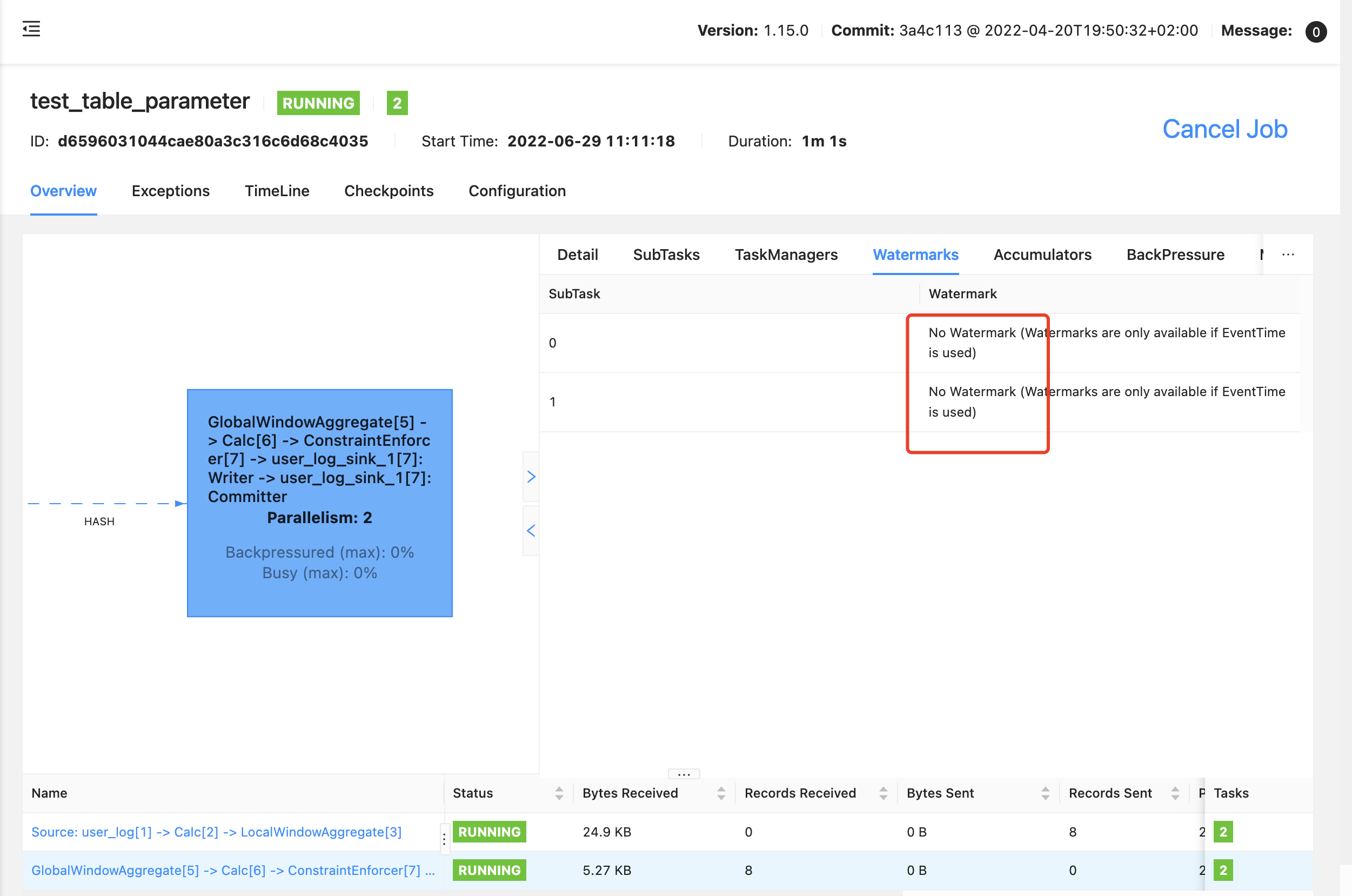
wtf??
明明是用的事件时间,debug 代码,算子也都是 事件时间的,在页面上竟然说 ”No Watermark (Watermarks are only available if EventTime is used)“
直接把 窗口的 时间改成 "处理时间",发现是正常的,有结果输出
这让我一度开始怀疑 难道 window tvf 不支持 ”事件时间“ (很明显是支持的)
这个问题困扰了好几天
今天突然发现算子的并行度是 2,幡然醒悟
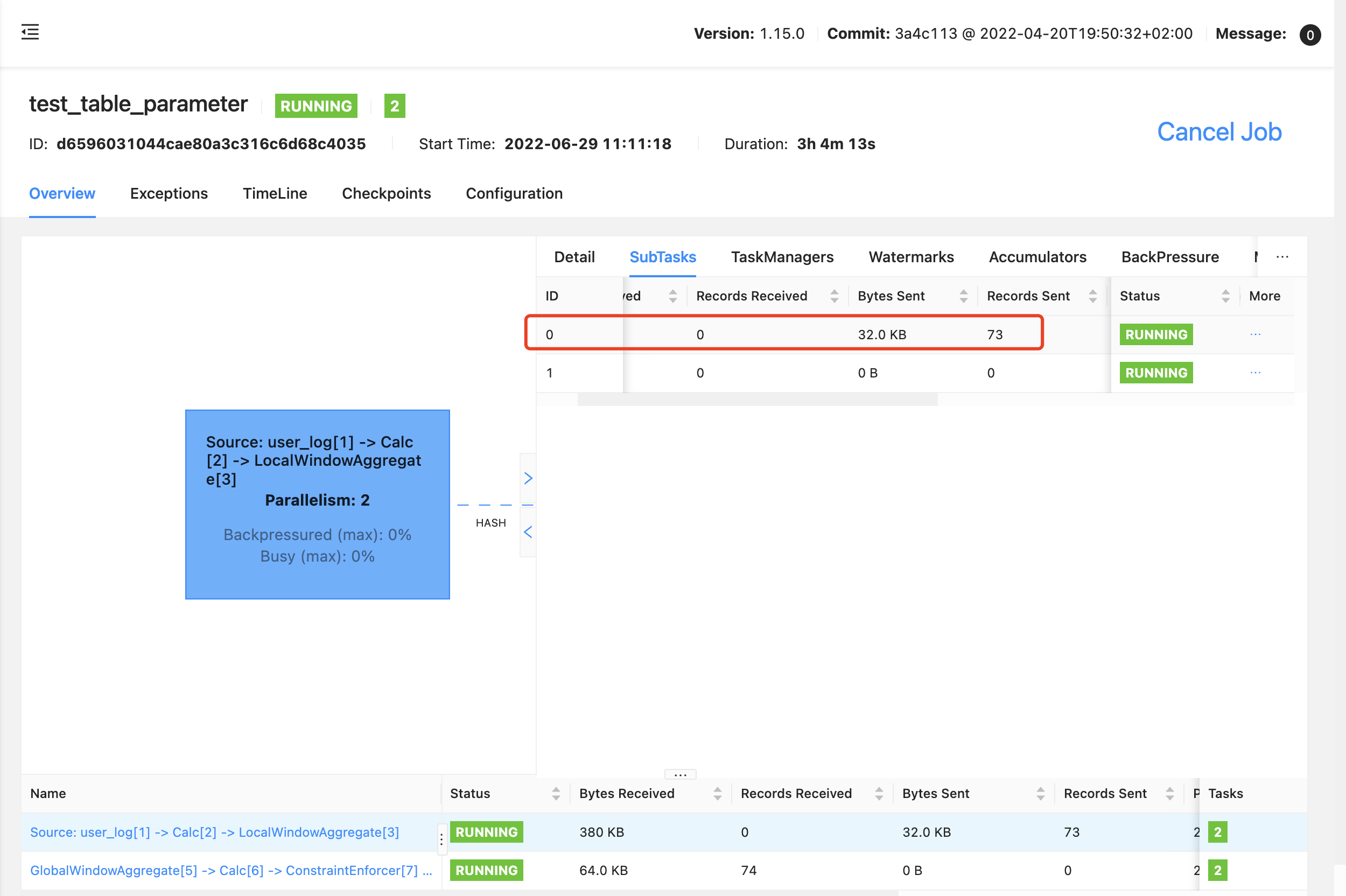
source 的 kafka topic 只有一个分区,那在 flink 里面就只有一个 并行度有数据,到 GlobalWindowAggregate 算子的时候,就会出现: 上游有两个并行度,一个有值,一个没有,在 watermark 对齐的情况下,会让算子的 watermark 一直处以 Long.MIN_VALUE(就是没有 watermark)
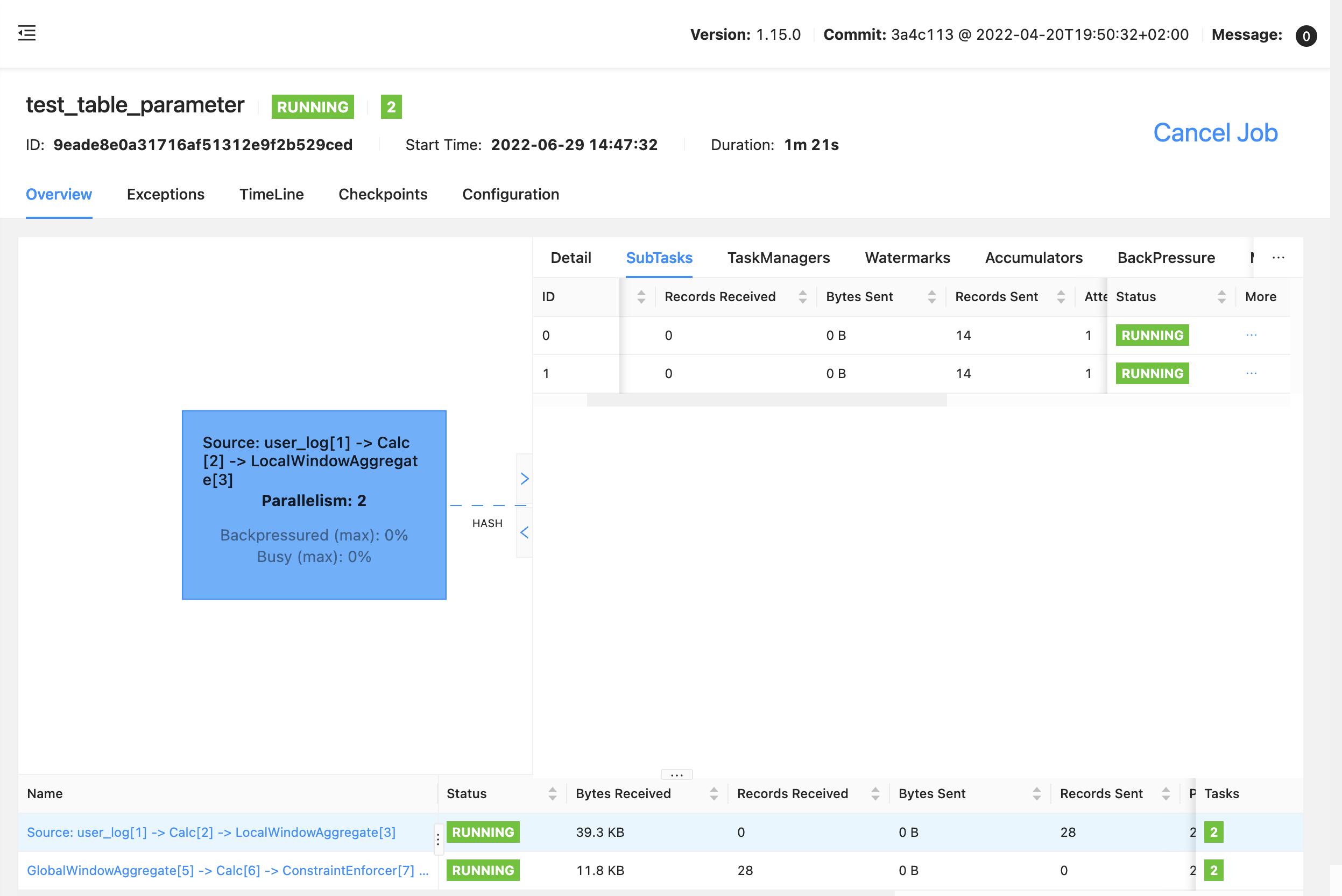
上游算子只有一个 subtask 有数据:
watermark 源码
看完了表象,我们再来看下源码
跳过网络发送、接收的部分,直接看数据类型处理的部分
AbstractStreamTaskNetworkInput.processElement
private void processElement(StreamElement recordOrMark, DataOutput<T> output) throws Exception {
// 判断输入的元素是 数据、watermark、延迟、watermark 状态
if (recordOrMark.isRecord()) {
// 数据
output.emitRecord(recordOrMark.asRecord());
} else if (recordOrMark.isWatermark()) {
// watermark
statusWatermarkValve.inputWatermark(
recordOrMark.asWatermark(), flattenedChannelIndices.get(lastChannel), output);
} else if (recordOrMark.isLatencyMarker()) {
// 延迟标记
output.emitLatencyMarker(recordOrMark.asLatencyMarker());
} else if (recordOrMark.isWatermarkStatus()) {
// watermark status : active/idea
statusWatermarkValve.inputWatermarkStatus(
recordOrMark.asWatermarkStatus(),
flattenedChannelIndices.get(lastChannel),
output);
} else {
throw new UnsupportedOperationException("Unknown type of StreamElement");
}
}
输入的 watermark 处理
StatusWatermarkValve.inputWatermark
/**
* Feed a {@link Watermark} into the valve. If the input triggers the valve to output a new
* Watermark, {@link DataOutput#emitWatermark(Watermark)} will be called to process the new
* Watermark.
*
* @param watermark the watermark to feed to the valve , watermark 值
* @param channelIndex the index of the channel that the fed watermark belongs to (index
* starting from 0), 通道 id
*/
public void inputWatermark(Watermark watermark, int channelIndex, DataOutput<?> output)
throws Exception {
// ignore the input watermark if its input channel, or all input channels are idle (i.e.
// overall the valve is idle).
// 判断上次输出的 watermark status 是否为 active && 当前通道的 watermark status 是否为 active
if (lastOutputWatermarkStatus.isActive()
&& channelStatuses[channelIndex].watermarkStatus.isActive()) {
// watermark 毫秒值
long watermarkMillis = watermark.getTimestamp();
// if the input watermark's value is less than the last received watermark for its input
// channel, ignore it also.
// 当前 watermark 大于上次 watermark
if (watermarkMillis > channelStatuses[channelIndex].watermark) {
// 保存当前 watermark 值
channelStatuses[channelIndex].watermark = watermarkMillis;
// previously unaligned input channels are now aligned if its watermark has caught
// up
// 如果它的水印已经赶上,以前未对齐的输入通道现在对齐
if (!channelStatuses[channelIndex].isWatermarkAligned
&& watermarkMillis >= lastOutputWatermark) {
channelStatuses[channelIndex].isWatermarkAligned = true;
}
// now, attempt to find a new min watermark across all aligned channels
// 现在,尝试在所有对齐的通道中找到一个新的最小水印
findAndOutputNewMinWatermarkAcrossAlignedChannels(output);
}
}
}
StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels
private void findAndOutputNewMinWatermarkAcrossAlignedChannels(DataOutput<?> output)
throws Exception {
// 一个极大值变量,用来存 最小的 watermark
long newMinWatermark = Long.MAX_VALUE;
boolean hasAlignedChannels = false;
// determine new overall watermark by considering only watermark-aligned channels across all
// channels
// 从 所有输入通道中获取 最小的 watermark 值
for (InputChannelStatus channelStatus : channelStatuses) {
if (channelStatus.isWatermarkAligned) {
hasAlignedChannels = true;
newMinWatermark = Math.min(channelStatus.watermark, newMinWatermark);
}
}
// we acknowledge and output the new overall watermark if it really is aggregated
// from some remaining aligned channel, and is also larger than the last output watermark
// 已经对齐了, 新的 watermark 大于上次的 watermark
if (hasAlignedChannels && newMinWatermark > lastOutputWatermark) {
lastOutputWatermark = newMinWatermark;
output.emitWatermark(new Watermark(lastOutputWatermark));
}
}
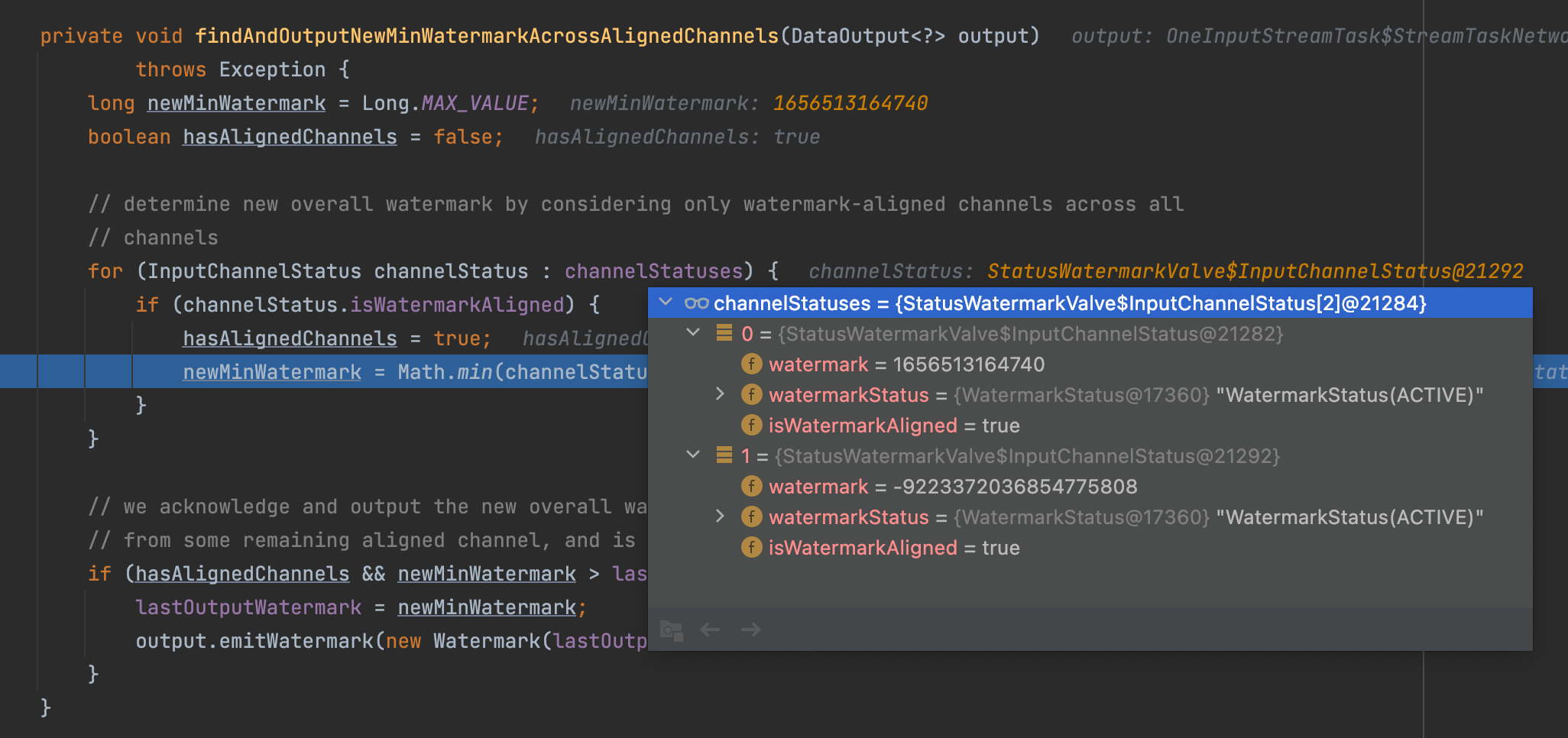
从代码看, GlobalWindowAggregate 算子有两个输入通道,其中一个正常输入 数据和 watermark,另一个没有数据和 watermark(默认 Long.MIN_VALUE),所以 GlobalWindowAggregate 算子的 watermark 永远是 Long.MIN_VALUE,永远也不会触发
看debug:
解决
给 source topic 添加一个 并行度
venn@venn sqlSubmit % kafka-topics.sh --zookeeper venn:2181 --topic user_log --describe
Topic:user_log PartitionCount:1 ReplicationFactor:1 Configs:
Topic: user_log Partition: 0 Leader: 0 Replicas: 0 Isr: 0
venn@venn sqlSubmit % kafka-topics.sh --zookeeper venn:2181 --topic user_log --alter --partitions 2
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!
venn@venn sqlSubmit % kafka-topics.sh --zookeeper venn:2181 --topic user_log --describe
Topic:user_log PartitionCount:2 ReplicationFactor:1 Configs:
Topic: user_log Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: user_log Partition: 1 Leader: 0 Replicas: 0 Isr: 0
venn@venn sqlSubmit %
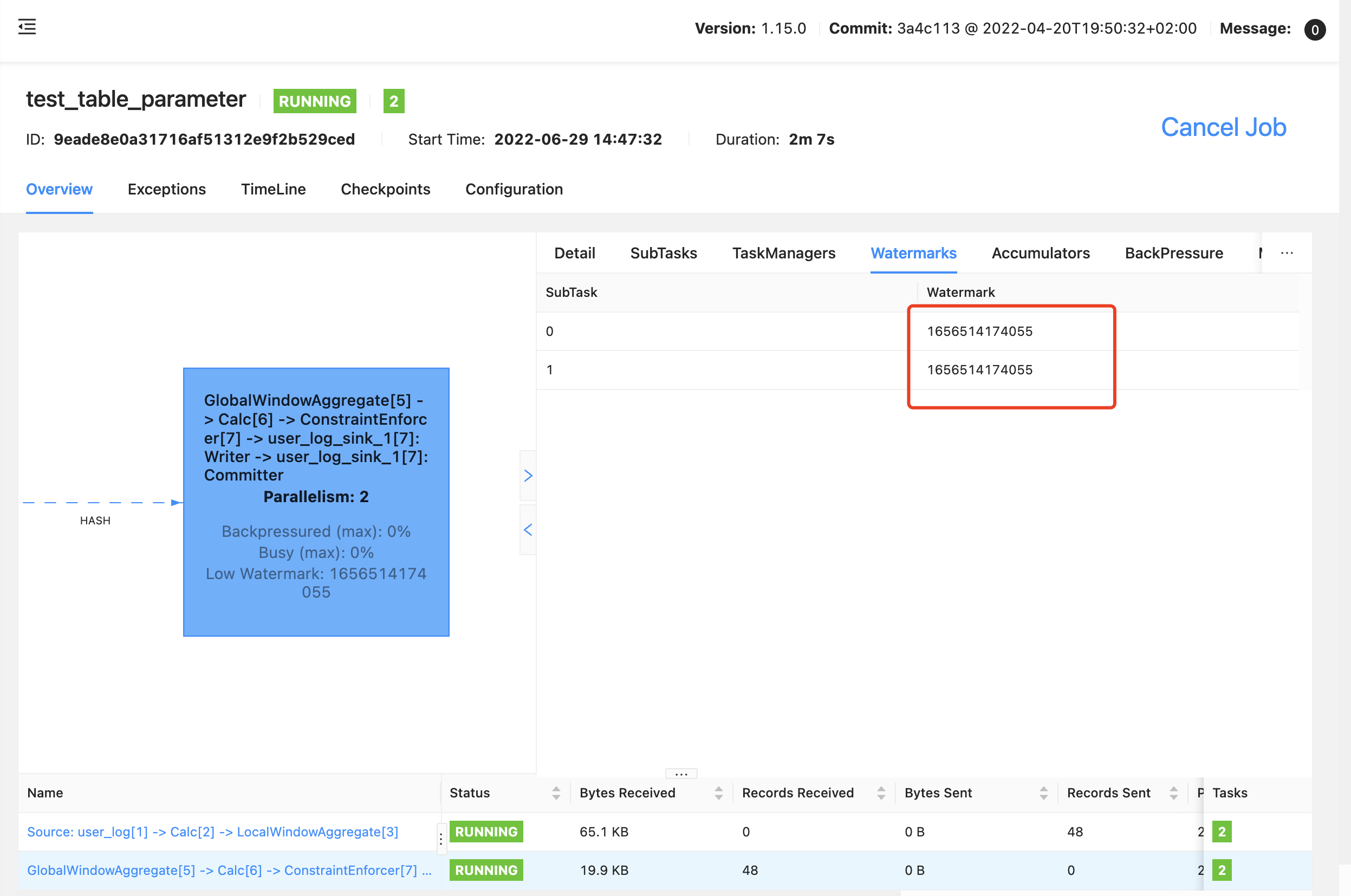
Source 块的算子两个 subtask 都有数据:
GlobalWindowAggregate 算子 watermark 就正常了
搞完收工
完整代码参见 github sqlSubmit
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号