
接上篇: Flink sql Group Windows 窗口源码解析
上篇写了 Group Windows 的源码解析,Group Windows 的源码是相对好阅读的,核心处理逻辑和 Stream api 一样: Window + trigger + agg function
而 Window TVF 就不太一样了
窗口样例
-- TUMBLE/HOP/CUMULATE 窗口
select date_format(now(), 'yyyy-MM-dd HH:mm:ss')
,date_format(window_start, 'yyyy-MM-dd HH:mm:ss') AS wStart
,date_format(window_end, 'yyyy-MM-dd HH:mm:ss') AS wEnd
,count(user_id) pv
,count(distinct user_id) uv
FROM TABLE(
TUMBLE(TABLE user_log, DESCRIPTOR(proc_time), INTERVAL '1' MINUTES )) t1
group by window_start, window_end
;
-- select date_format(now(), 'yyyy-MM-dd HH:mm:ss')
-- ,date_format(window_start, 'yyyy-MM-dd HH:mm:ss') AS wStart
-- ,date_format(window_end, 'yyyy-MM-dd HH:mm:ss') AS wEnd
-- ,count(user_id) pv
-- ,count(distinct user_id) uv
-- FROM TABLE(
-- CUMULATE(TABLE user_log, DESCRIPTOR(ts), INTERVAL '5' SECOND, INTERVAL '5' MINUTE)) t1
-- group by window_start, window_end
;
完整sql 参加 github sqlSubmit kafka_window_agg.sql
Windowing TVF 源码
先来个任务流图: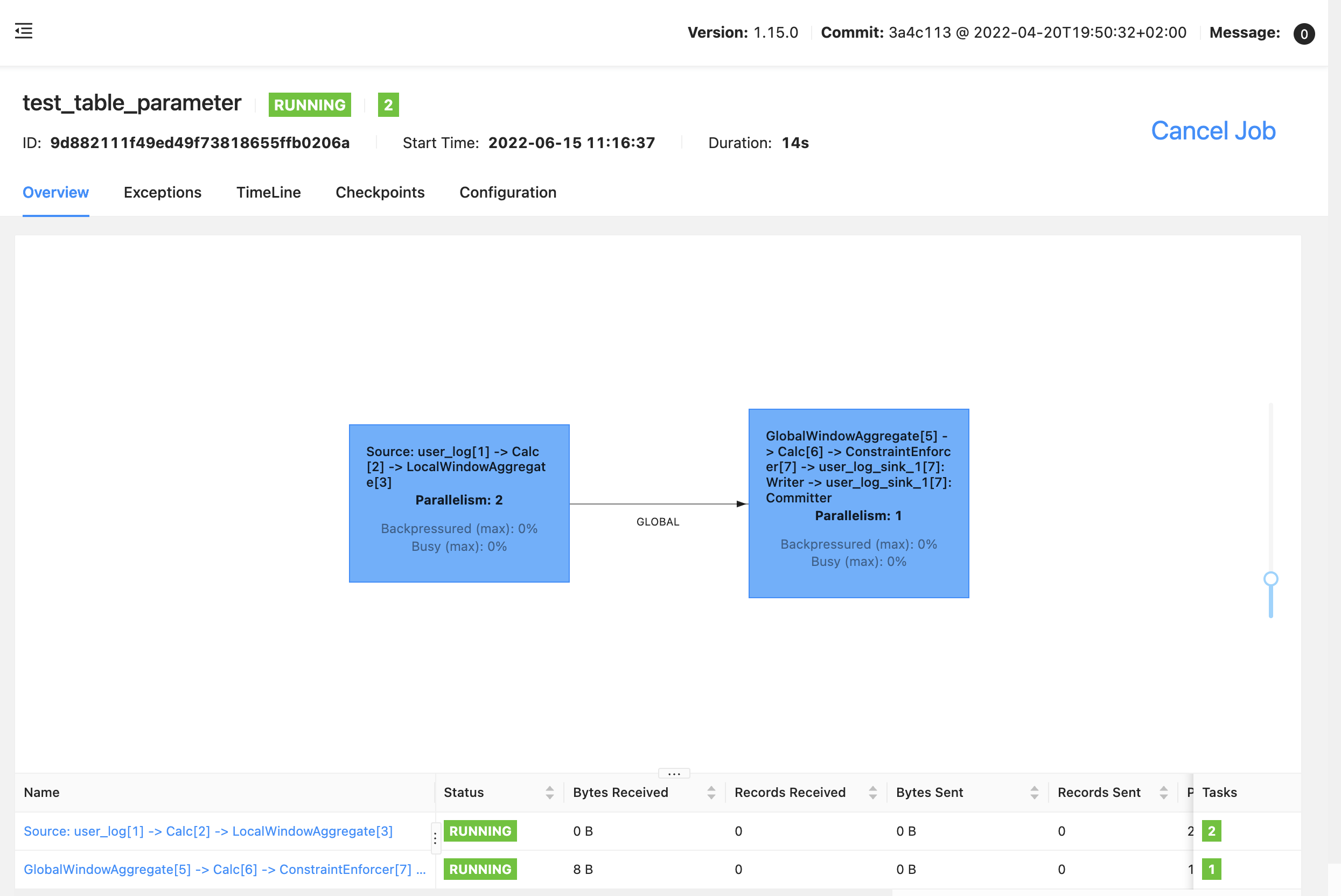
可以看到和 Group window 明显不同,windowing TVF 是结合 LocalWindowAggregate 和 GlobalWindowAggregate 实现
ExecGraph
第一次写这部分的源码解析,跳过 sql 解析部分,直接到 生成 execGraph 开始
PlannerBase.translate
override def translate(
modifyOperations: util.List[ModifyOperation]): util.List[Transformation[_]] = {
beforeTranslation()
if (modifyOperations.isEmpty) {
return List.empty[Transformation[_]]
}
val relNodes = modifyOperations.map(translateToRel)
// sql 节点优化
val optimizedRelNodes = optimize(relNodes)
// 生成 exec graph
val execGraph = translateToExecNodeGraph(optimizedRelNodes)
// 提交到远程执行
val transformations = translateToPlan(execGraph)
afterTranslation()
transformations
}
看过相关介绍、博客的同学应该都知道,Flink 的执行图是从 sink 开始构建的,从 sink 节点开始,然后根据 sink 的输入边,构建 sink 的上游节点, 这样依次构建到 source 节点
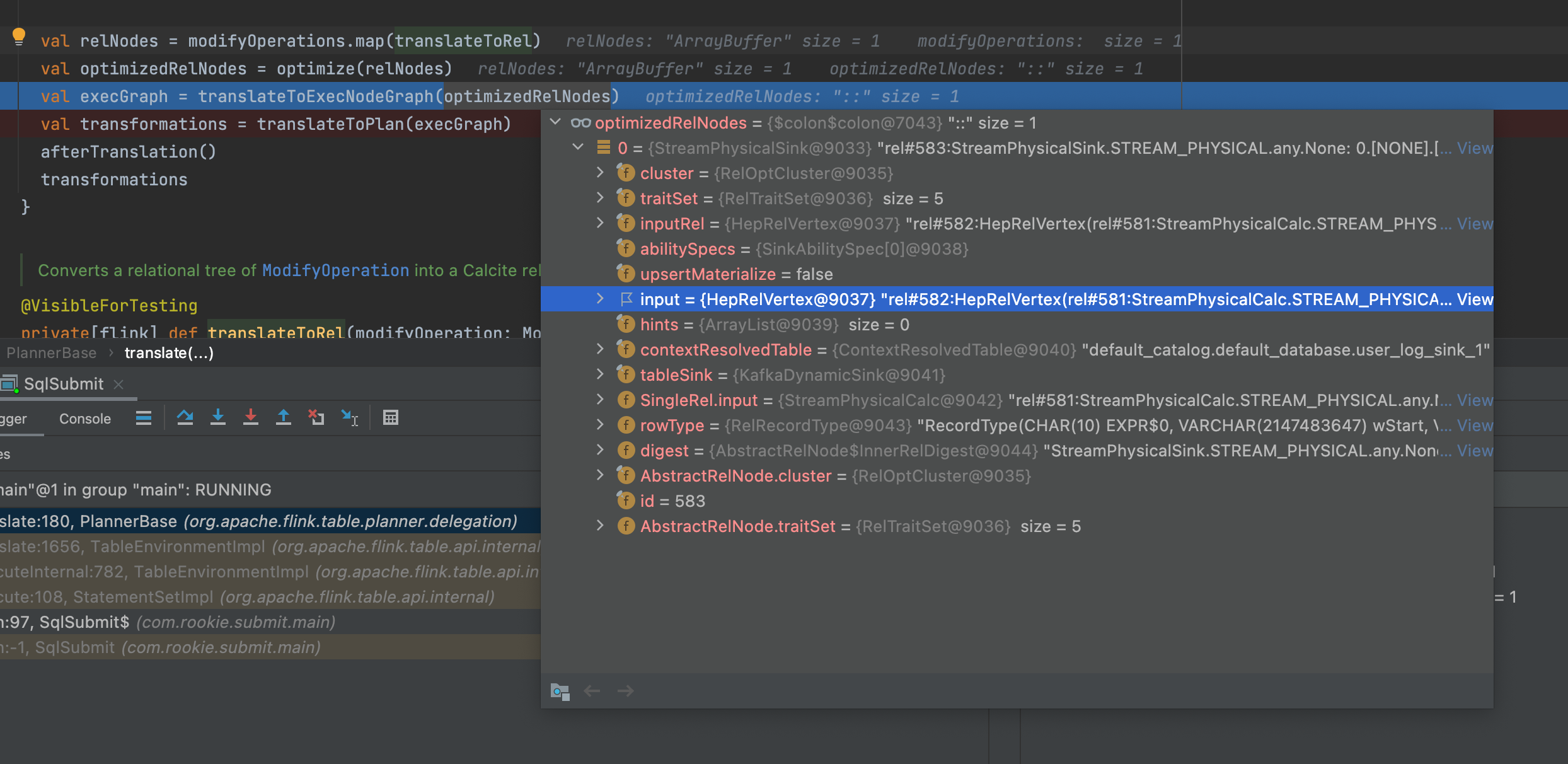
那我们就从 StreamPhysicalSink 开始构建 sql 对应的执行图
PlannerBasetranslateToExecNodeGraph
/**
Converts FlinkPhysicalRel DAG to ExecNodeGraph, tries to reuse duplicate sub-plans and transforms the graph based on the given processors.
*/
private[flink] def translateToExecNodeGraph(optimizedRelNodes: Seq[RelNode]): ExecNodeGraph = {
val nonPhysicalRel = optimizedRelNodes.filterNot(_.isInstanceOf[FlinkPhysicalRel])
if (nonPhysicalRel.nonEmpty) {
throw new TableException("The expected optimized plan is FlinkPhysicalRel plan, " +
s"actual plan is ${nonPhysicalRel.head.getClass.getSimpleName} plan.")
}
require(optimizedRelNodes.forall(_.isInstanceOf[FlinkPhysicalRel]))
// Rewrite same rel object to different rel objects
// in order to get the correct dag (dag reuse is based on object not digest)
val shuttle = new SameRelObjectShuttle()
val relsWithoutSameObj = optimizedRelNodes.map(_.accept(shuttle))
// reuse subplan
val reusedPlan = SubplanReuser.reuseDuplicatedSubplan(relsWithoutSameObj, tableConfig)
// convert FlinkPhysicalRel DAG to ExecNodeGraph
val generator = new ExecNodeGraphGenerator()
// 调用 ExecNodeGraphGenerator 生成 执行图
val execGraph = generator.generate(reusedPlan.map(_.asInstanceOf[FlinkPhysicalRel]))
// process the graph
val context = new ProcessorContext(this)
val processors = getExecNodeGraphProcessors
processors.foldLeft(execGraph)((graph, processor) => processor.process(graph, context))
}
ExecNodeGraphGenerator.generate, 输入参数 List
在这里我们仔细看下任务流图的算子和上下游关系:
Source --> Calc --> LocalWindowAggregate --> GlobalWindowAggregate --> Calc --> Sink
所以在生成执行图时,就是反过来的:
Sink --> Calc --> GlobalWindowAggregate --> LocalWindowAggregate --> Calc --> Source
ExecNodeGraphGenerator.generate
public ExecNodeGraph generate(List<FlinkPhysicalRel> relNodes) {
List<ExecNode<?>> rootNodes = new ArrayList<>(relNodes.size());
for (FlinkPhysicalRel relNode : relNodes) {
rootNodes.add(generate(relNode));
}
return new ExecNodeGraph(rootNodes);
}
ExecNodeGraphGenerator.generate
private ExecNode<?> generate(FlinkPhysicalRel rel) {
// 构建之前先判断一下 节点是否已经构建过了(多sink 任务,部分算子有两个输出)
ExecNode<?> execNode = visitedRels.get(rel);
if (execNode != null) {
return execNode;
}
if (rel instanceof CommonIntermediateTableScan) {
throw new TableException("Intermediate RelNode can't be converted to ExecNode.");
}
List<ExecNode<?>> inputNodes = new ArrayList<>();
// 获取当前节点的所有输入边,递归调用 generate 方法,构建上游节点,依次递归直达 source 节点(source 节点没有输入边)
for (RelNode input : rel.getInputs()) {
inputNodes.add(generate((FlinkPhysicalRel) input));
}
// 构建节点: 调用节点对应的 translateToExecNode 初始化 节点
execNode = rel.translateToExecNode();
// 添加输入边
// connects the input nodes
List<ExecEdge> inputEdges = new ArrayList<>(inputNodes.size());
for (ExecNode<?> inputNode : inputNodes) {
inputEdges.add(ExecEdge.builder().source(inputNode).target(execNode).build());
}
execNode.setInputEdges(inputEdges);
// 记录所有构建的节点
visitedRels.put(rel, execNode);
return execNode;
}
6 层递归,依次创建所有算子: 
列举一下: StreamPhysicalLocalWindowAggregate、StreamPhysicalGlobalWindowAggregate
StreamPhysicalLocalWindowAggregate.translateToExecNode
override def translateToExecNode(): ExecNode[_] = {
checkEmitConfiguration(FlinkRelOptUtil.getTableConfigFromContext(this))
new StreamExecLocalWindowAggregate(
unwrapTableConfig(this),
grouping,
aggCalls.toArray,
windowing,
InputProperty.DEFAULT,
FlinkTypeFactory.toLogicalRowType(getRowType),
getRelDetailedDescription)
}
StreamPhysicalGlobalWindowAggregate.translateToExecNode
override def translateToExecNode(): ExecNode[_] = {
checkEmitConfiguration(FlinkRelOptUtil.getTableConfigFromContext(this))
new StreamExecGlobalWindowAggregate(
unwrapTableConfig(this),
grouping,
aggCalls.toArray,
windowing,
namedWindowProperties.toArray,
InputProperty.DEFAULT,
FlinkTypeFactory.toLogicalRowType(inputRowTypeOfLocalAgg),
FlinkTypeFactory.toLogicalRowType(getRowType),
getRelDetailedDescription)
}
生成执行图后就调用 translateToPlan 提交任务到 TM 执行
PlannerBase.translate
override def translate(
modifyOperations: util.List[ModifyOperation]): util.List[Transformation[_]] = {
beforeTranslation()
if (modifyOperations.isEmpty) {
return List.empty[Transformation[_]]
}
val relNodes = modifyOperations.map(translateToRel)
// sql 节点优化
val optimizedRelNodes = optimize(relNodes)
// 生成 exec graph
val execGraph = translateToExecNodeGraph(optimizedRelNodes)
// 提交到远程执行
val transformations = translateToPlan(execGraph)
afterTranslation()
transformations
}
然后又是递归,依次调用每个节点的 translateToPlanInternal 方法,创建算子实例
比如 source:
CommonExecTableSourceScan.translateToPlanInternal
@Override
protected Transformation<RowData> translateToPlanInternal(
PlannerBase planner, ExecNodeConfig config) {
final ScanTableSource tableSource =
tableSourceSpec.getScanTableSource(planner.getFlinkContext());
ScanTableSource.ScanRuntimeProvider provider =
tableSource.getScanRuntimeProvider(ScanRuntimeProviderContext.INSTANCE);
if (provider instanceof SourceFunctionProvider) {
final SourceFunctionProvider sourceFunctionProvider = (SourceFunctionProvider) provider;
final SourceFunction<RowData> function = sourceFunctionProvider.createSourceFunction();
final Transformation<RowData> transformation =
createSourceFunctionTransformation(
env,
function,
sourceFunctionProvider.isBounded(),
meta.getName(),
outputTypeInfo);
return meta.fill(transformation);
。。。。
}
这里多一重递归是算子 local 和 globa 算子是断开的,涉及数据分区策略
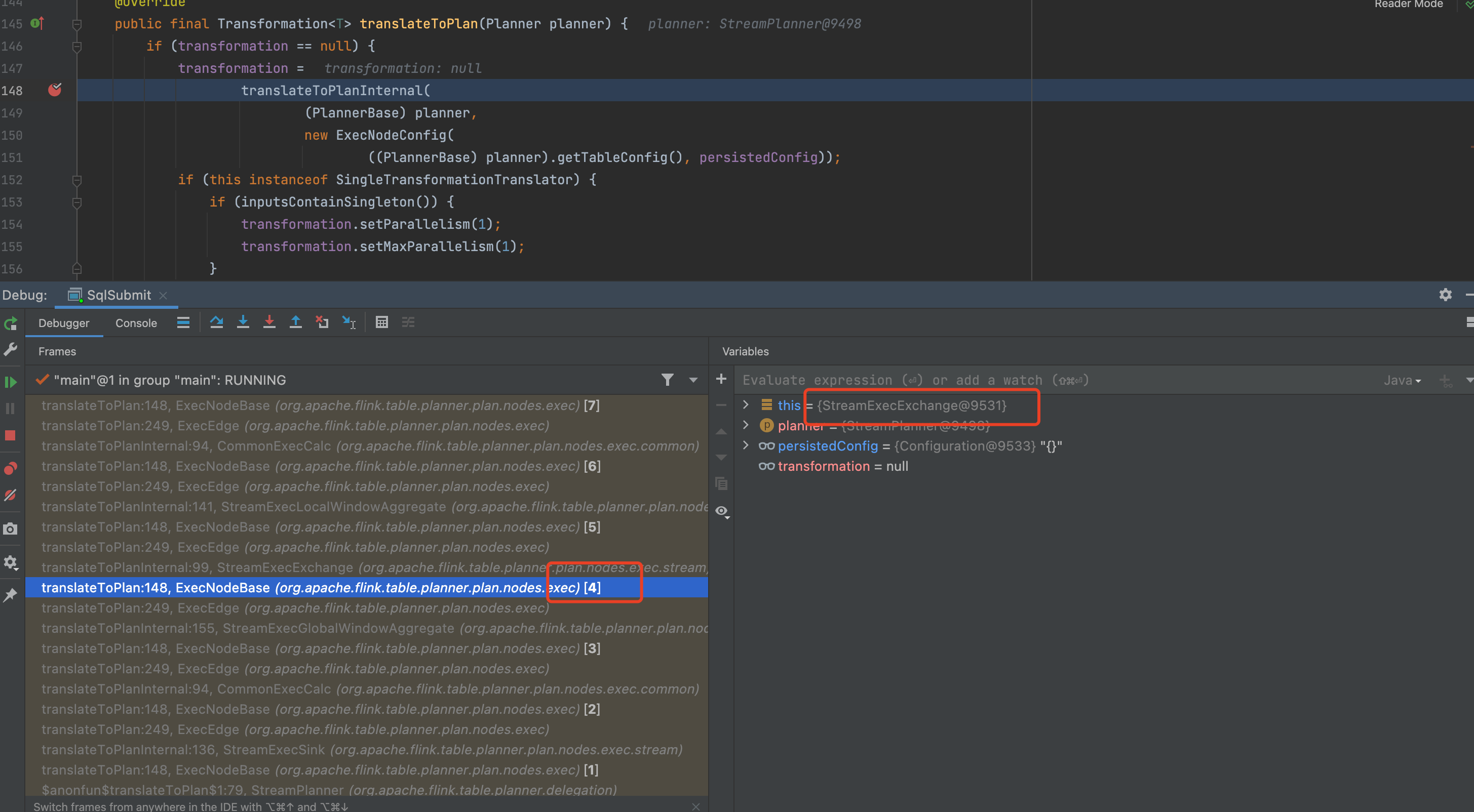
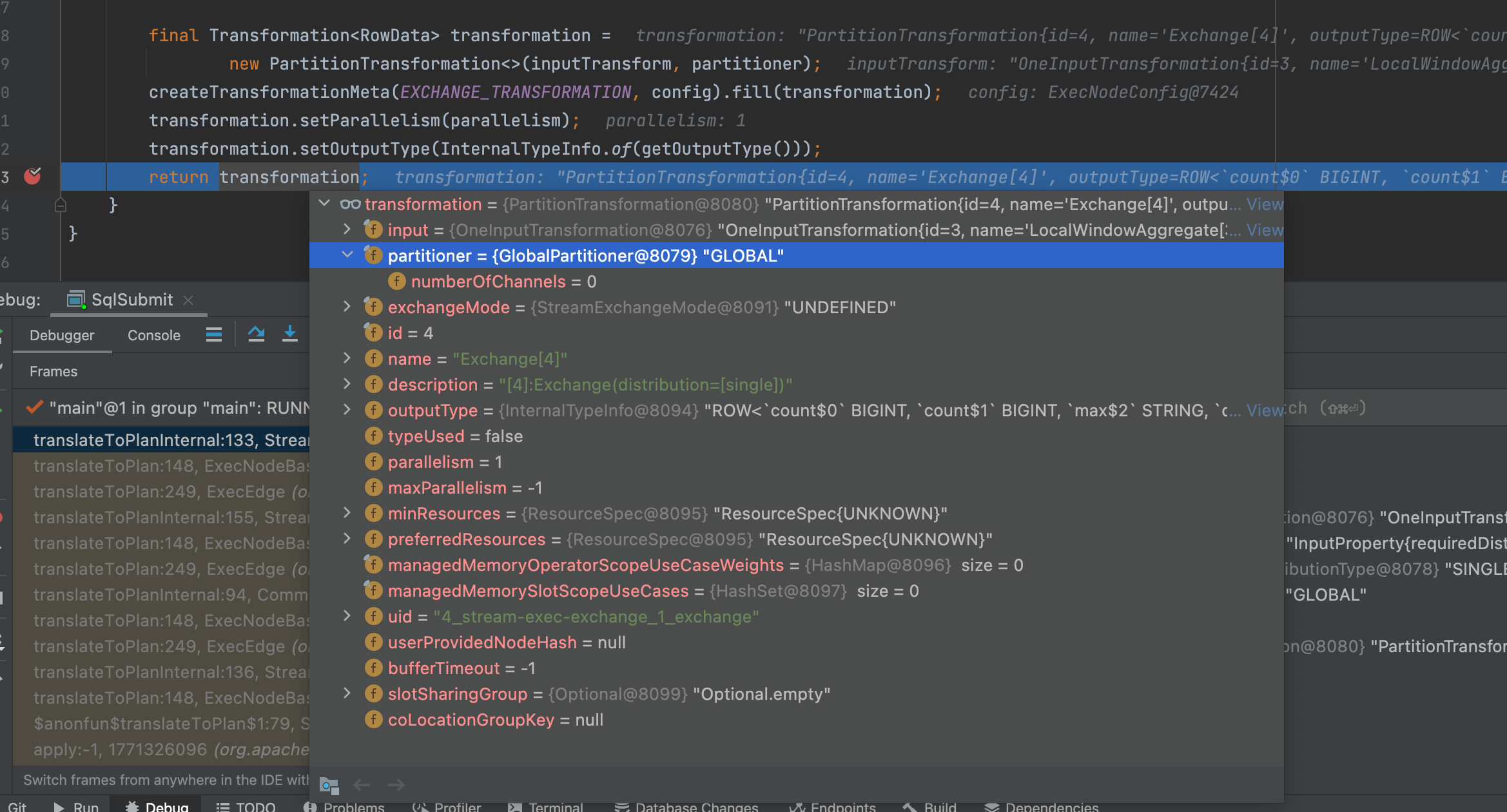
然后我们终于进到 windowing TVF 具体的代码上了
GlobalWindowAggregate 源码
StreamExecGlobalWindowAggregate.translateToPlanInternal
@Override
protected Transformation<RowData> translateToPlanInternal(
PlannerBase planner, ExecNodeConfig config) {
final ExecEdge inputEdge = getInputEdges().get(0);
final Transformation<RowData> inputTransform =
(Transformation<RowData>) inputEdge.translateToPlan(planner);
// 获取上游算子输出数据类型,即当前算子输入数据类型
final RowType inputRowType = (RowType) inputEdge.getOutputType();
// 获取时区
final ZoneId shiftTimeZone =
TimeWindowUtil.getShiftTimeZone(
windowing.getTimeAttributeType(),
TableConfigUtils.getLocalTimeZone(config));
// 创建 ”分片分配器“,类似于 窗口分配器
final SliceAssigner sliceAssigner = createSliceAssigner(windowing, shiftTimeZone);
// local agg 方法列表
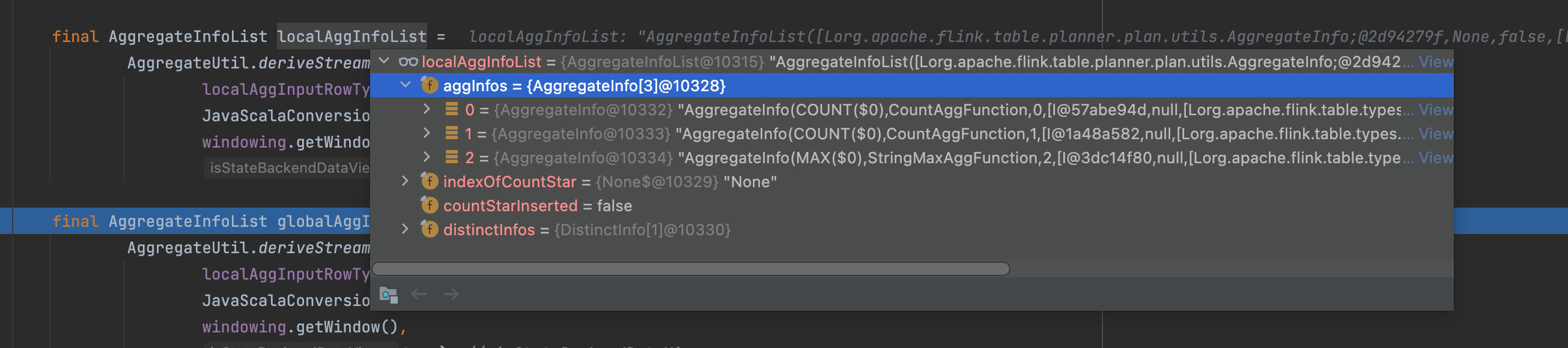
final AggregateInfoList localAggInfoList =
AggregateUtil.deriveStreamWindowAggregateInfoList(
localAggInputRowType, // should use original input here
JavaScalaConversionUtil.toScala(Arrays.asList(aggCalls)),
windowing.getWindow(),
false); // isStateBackendDataViews
// global agg 方法列表
final AggregateInfoList globalAggInfoList =
AggregateUtil.deriveStreamWindowAggregateInfoList(
localAggInputRowType, // should use original input here
JavaScalaConversionUtil.toScala(Arrays.asList(aggCalls)),
windowing.getWindow(),
true); // isStateBackendDataViews
// 生成 local agg function 代码,
// handler used to merge multiple local accumulators into one accumulator,用于将多个本地累加器合并为一个累加器的处理程序,
// where the accumulators are all on memory,累加器都在内存中
final GeneratedNamespaceAggsHandleFunction<Long> localAggsHandler =
createAggsHandler(
"LocalWindowAggsHandler",
sliceAssigner,
localAggInfoList,
grouping.length,
true,
localAggInfoList.getAccTypes(),
config,
planner.getRelBuilder(),
shiftTimeZone);
// 生成 global agg function 代码
// handler used to merge the single local accumulator (on memory) into state accumulator
// 用于将单个本地累加器(在内存上)合并到状态累加器的处理程序
final GeneratedNamespaceAggsHandleFunction<Long> globalAggsHandler =
createAggsHandler(
"GlobalWindowAggsHandler",
sliceAssigner,
globalAggInfoList,
0,
true,
localAggInfoList.getAccTypes(),
config,
planner.getRelBuilder(),
shiftTimeZone);
// handler used to merge state accumulators for merging slices into window,
// 用于合并状态累加器以将切片合并到窗口中的处理程序,
// e.g. Hop and Cumulate
final GeneratedNamespaceAggsHandleFunction<Long> stateAggsHandler =
createAggsHandler(
"StateWindowAggsHandler",
sliceAssigner,
globalAggInfoList,
0,
false,
globalAggInfoList.getAccTypes(),
config,
planner.getRelBuilder(),
shiftTimeZone);
final RowDataKeySelector selector =
KeySelectorUtil.getRowDataSelector(grouping, InternalTypeInfo.of(inputRowType));
final LogicalType[] accTypes = convertToLogicalTypes(globalAggInfoList.getAccTypes());
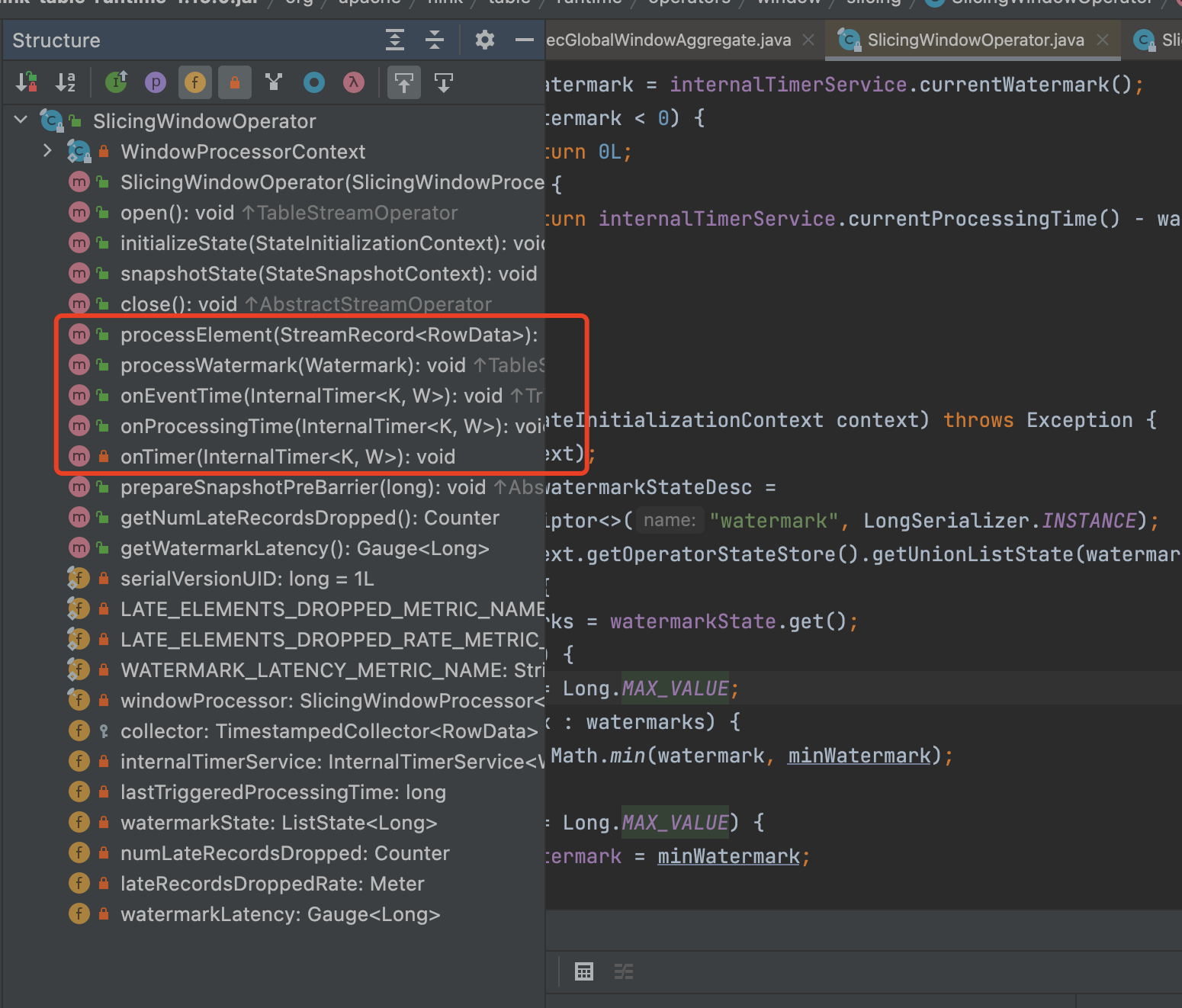
// 生成窗口算子 SlicingWindowOperator,又到了熟悉的地方了,类似于 WindowOperator 的算子
final OneInputStreamOperator<RowData, RowData> windowOperator =
SlicingWindowAggOperatorBuilder.builder()
.inputSerializer(new RowDataSerializer(inputRowType))
.shiftTimeZone(shiftTimeZone)
.keySerializer(
(PagedTypeSerializer<RowData>)
selector.getProducedType().toSerializer())
.assigner(sliceAssigner)
.countStarIndex(globalAggInfoList.getIndexOfCountStar())
.globalAggregate(
localAggsHandler,
globalAggsHandler,
stateAggsHandler,
new RowDataSerializer(accTypes))
.build();
// 生成 算子的 transform
final OneInputTransformation<RowData, RowData> transform =
ExecNodeUtil.createOneInputTransformation(
inputTransform,
createTransformationMeta(GLOBAL_WINDOW_AGGREGATE_TRANSFORMATION, config),
SimpleOperatorFactory.of(windowOperator),
InternalTypeInfo.of(getOutputType()),
inputTransform.getParallelism(),
WINDOW_AGG_MEMORY_RATIO);
// set KeyType and Selector for state
transform.setStateKeySelector(selector);
transform.setStateKeyType(selector.getProducedType());
return transform;
}
agg info 列表:
SlicingWindowOperator:
StreamExecWindowAggregateBase.createSliceAssigner
protected SliceAssigner createSliceAssigner(
WindowSpec windowSpec, int timeAttributeIndex, ZoneId shiftTimeZone) {
// 基于不同窗口类型,创建对应的 分片分配器
// tumble
if (windowSpec instanceof TumblingWindowSpec) {
Duration size = ((TumblingWindowSpec) windowSpec).getSize();
SliceAssigners.TumblingSliceAssigner assigner =
SliceAssigners.tumbling(timeAttributeIndex, shiftTimeZone, size);
Duration offset = ((TumblingWindowSpec) windowSpec).getOffset();
if (offset != null) {
assigner = assigner.withOffset(offset);
}
return assigner;
// hop
} else if (windowSpec instanceof HoppingWindowSpec) {
Duration size = ((HoppingWindowSpec) windowSpec).getSize();
Duration slide = ((HoppingWindowSpec) windowSpec).getSlide();
if (size.toMillis() % slide.toMillis() != 0) {
throw new TableException(
String.format(
"HOP table function based aggregate requires size must be an "
+ "integral multiple of slide, but got size %s ms and slide %s ms",
size.toMillis(), slide.toMillis()));
}
SliceAssigners.HoppingSliceAssigner assigner =
SliceAssigners.hopping(timeAttributeIndex, shiftTimeZone, size, slide);
Duration offset = ((HoppingWindowSpec) windowSpec).getOffset();
if (offset != null) {
assigner = assigner.withOffset(offset);
}
return assigner;
// cumulate
} else if (windowSpec instanceof CumulativeWindowSpec) {
Duration maxSize = ((CumulativeWindowSpec) windowSpec).getMaxSize();
Duration step = ((CumulativeWindowSpec) windowSpec).getStep();
if (maxSize.toMillis() % step.toMillis() != 0) {
throw new TableException(
String.format(
"CUMULATE table function based aggregate requires maxSize must be an "
+ "integral multiple of step, but got maxSize %s ms and step %s ms",
maxSize.toMillis(), step.toMillis()));
}
SliceAssigners.CumulativeSliceAssigner assigner =
SliceAssigners.cumulative(timeAttributeIndex, shiftTimeZone, maxSize, step);
Duration offset = ((CumulativeWindowSpec) windowSpec).getOffset();
if (offset != null) {
assigner = assigner.withOffset(offset);
}
return assigner;
// 不支持其他
} else {
throw new UnsupportedOperationException(windowSpec + " is not supported yet.");
}
}
翻滚窗口: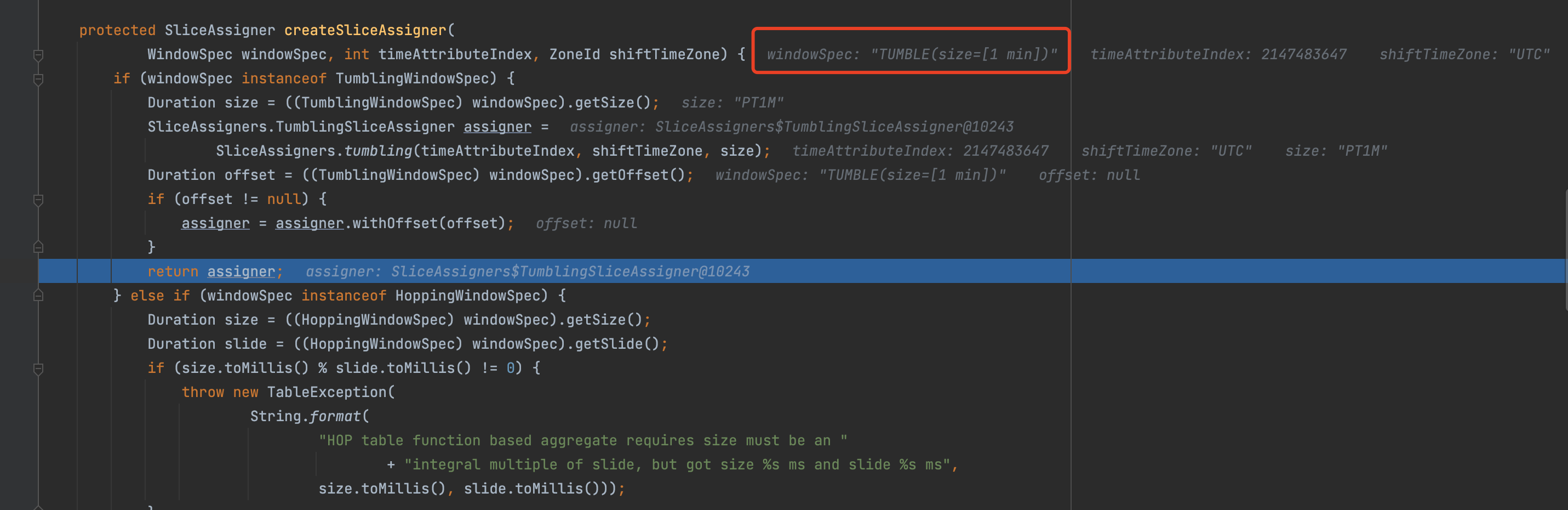
SlicingWindowOperator 通过 onTimer 事件来触发窗口计算:
SlicingWindowOperator.onTimer
private void onTimer(InternalTimer<K, W> timer) throws Exception {
setCurrentKey(timer.getKey());
W window = timer.getNamespace();
// 触发窗口计算
windowProcessor.fireWindow(window);
// 清理完成的窗口
windowProcessor.clearWindow(window);
// we don't need to clear window timers,
// because there should only be one timer for each window now, which is current timer.
}
SliceUnsharedWindowAggProcessor.fireWindow: 通过获取窗口累加器,获取累加器的结果,输出数据
@Override
public void fireWindow(Long windowEnd) throws Exception {
RowData acc = windowState.value(windowEnd);
if (acc == null) {
acc = aggregator.createAccumulators();
}
aggregator.setAccumulators(windowEnd, acc);
RowData aggResult = aggregator.getValue(windowEnd);
collect(aggResult);
}
然后 GlobalWindowAggregate 部分就完成了
LocalWindowAggregate 源码
LocalWindowAggregate 部分的源码,比 GlobalWindowAggregate 部分的简单很多,一样有 sliceAssigner/ aggInfoList/generatedAggsHandler, 然后再接一个简单的 LocalSlicingWindowAggOperator
StreamExecLocalWindowAggregate.translateToPlanInternal
protected Transformation<RowData> translateToPlanInternal(
PlannerBase planner, ExecNodeConfig config) {
final ExecEdge inputEdge = getInputEdges().get(0);
final Transformation<RowData> inputTransform =
(Transformation<RowData>) inputEdge.translateToPlan(planner);
final RowType inputRowType = (RowType) inputEdge.getOutputType();
// 时区
final ZoneId shiftTimeZone =
TimeWindowUtil.getShiftTimeZone(
windowing.getTimeAttributeType(),
TableConfigUtils.getLocalTimeZone(config));
// 分片分配器
final SliceAssigner sliceAssigner = createSliceAssigner(windowing, shiftTimeZone);
// agg 方法列表
final AggregateInfoList aggInfoList =
AggregateUtil.deriveStreamWindowAggregateInfoList(
inputRowType,
JavaScalaConversionUtil.toScala(Arrays.asList(aggCalls)),
windowing.getWindow(),
false); // isStateBackendDataViews
// 生成的代码
final GeneratedNamespaceAggsHandleFunction<Long> generatedAggsHandler =
createAggsHandler(
sliceAssigner,
aggInfoList,
config,
planner.getRelBuilder(),
inputRowType.getChildren(),
shiftTimeZone);
final RowDataKeySelector selector =
KeySelectorUtil.getRowDataSelector(grouping, InternalTypeInfo.of(inputRowType));
PagedTypeSerializer<RowData> keySer =
(PagedTypeSerializer<RowData>) selector.getProducedType().toSerializer();
AbstractRowDataSerializer<RowData> valueSer = new RowDataSerializer(inputRowType);
WindowBuffer.LocalFactory bufferFactory =
new RecordsWindowBuffer.LocalFactory(
keySer, valueSer, new LocalAggCombiner.Factory(generatedAggsHandler));
// 窗口算子
final OneInputStreamOperator<RowData, RowData> localAggOperator =
new LocalSlicingWindowAggOperator(
selector, sliceAssigner, bufferFactory, shiftTimeZone);
return ExecNodeUtil.createOneInputTransformation(
inputTransform,
createTransformationMeta(LOCAL_WINDOW_AGGREGATE_TRANSFORMATION, config),
SimpleOperatorFactory.of(localAggOperator),
InternalTypeInfo.of(getOutputType()),
inputTransform.getParallelism(),
// use less memory here to let the chained head operator can have more memory
WINDOW_AGG_MEMORY_RATIO / 2);
}
数据的处理流程也比较简单:
- LocalSlicingWindowAggOperator 处理数据输入:
LocalSlicingWindowAggOperator.processElement 获取数据属于的窗口分片(已分片结尾时间命名),将数据暂存到 windowBuffer
@Override
public void processElement(StreamRecord<RowData> element) throws Exception {
RowData inputRow = element.getValue();
RowData key = keySelector.getKey(inputRow);
long sliceEnd = sliceAssigner.assignSliceEnd(inputRow, CLOCK_SERVICE);
// may flush to output if buffer is full
windowBuffer.addElement(key, sliceEnd, inputRow);
}
RecordsWindowBuffer.addElement
@Override
public void addElement(RowData key, long sliceEnd, RowData element) throws Exception {
// track the lowest trigger time, if watermark exceeds the trigger time,
// it means there are some elements in the buffer belong to a window going to be fired,
// and we need to flush the buffer into state for firing.
minSliceEnd = Math.min(sliceEnd, minSliceEnd);
reuseWindowKey.replace(sliceEnd, key);
LookupInfo<WindowKey, Iterator<RowData>> lookup = recordsBuffer.lookup(reuseWindowKey);
try {
recordsBuffer.append(lookup, recordSerializer.toBinaryRow(element));
} catch (EOFException e) {
// buffer is full, flush it to state
flush();
// remember to add the input element again
addElement(key, sliceEnd, element);
}
}
watermark 触发 LocalSlicingWindowAggOperator.processWatermark 根据 watermark 和窗口时间,触发窗口
LocalSlicingWindowAggOperator.processWatermark
@Override
public void processWatermark(Watermark mark) throws Exception {
if (mark.getTimestamp() > currentWatermark) {
currentWatermark = mark.getTimestamp();
if (currentWatermark >= nextTriggerWatermark) {
// we only need to call advanceProgress() when current watermark may trigger window
// 创发窗口
windowBuffer.advanceProgress(currentWatermark);
nextTriggerWatermark =
getNextTriggerWatermark(
currentWatermark, windowInterval, shiftTimezone, useDayLightSaving);
}
}
super.processWatermark(mark);
}
RecordsWindowBuffer.advanceProgress 判断是否触发窗口
@Override
public void advanceProgress(long progress) throws Exception {
if (isWindowFired(minSliceEnd, progress, shiftTimeZone)) {
// there should be some window to be fired, flush buffer to state first
flush();
}
}
RecordsWindowBuffer.isWindowFired
public static boolean isWindowFired(
long windowEnd, long currentProgress, ZoneId shiftTimeZone) {
// Long.MAX_VALUE is a flag of min window end, directly return false
if (windowEnd == Long.MAX_VALUE) {
return false;
}
long windowTriggerTime = toEpochMillsForTimer(windowEnd - 1, shiftTimeZone);
// 当前时间大于窗口触发时间
return currentProgress >= windowTriggerTime;
}
触发窗口计算是调用 flush , 调用 combineFunction 先合并每个 key 本地数据
RecordsWindowBuffer.flush
@Override
public void flush() throws Exception {
if (recordsBuffer.getNumKeys() > 0) {
KeyValueIterator<WindowKey, Iterator<RowData>> entryIterator =
recordsBuffer.getEntryIterator(requiresCopy);
while (entryIterator.advanceNext()) {
combineFunction.combine(entryIterator.getKey(), entryIterator.getValue());
}
recordsBuffer.reset();
// reset trigger time
minSliceEnd = Long.MAX_VALUE;
}
LocalAggCombiner.combine,执行 agg 流程: 创建累加器,执行累加,最后输出数据到下游
@Override
public void combine(WindowKey windowKey, Iterator<RowData> records) throws Exception {
// always not copy key/value because they are not cached.
final RowData key = windowKey.getKey();
final Long window = windowKey.getWindow();
// step 1: create an empty accumulator
RowData acc = aggregator.createAccumulators();
// step 2: set accumulator to function
aggregator.setAccumulators(window, acc);
// step 3: do accumulate
while (records.hasNext()) {
RowData record = records.next();
if (isAccumulateMsg(record)) {
aggregator.accumulate(record);
} else {
aggregator.retract(record);
}
}
// step 4: get accumulator and output accumulator
acc = aggregator.getAccumulators();
output(key, window, acc);
}
LocalWindowAggregate 搞定
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号