
留存率是用于反映网站、互联网应用或网络游戏的运营情况的统计指标,其具体含义为在统计周期(周/月)内,每日活跃用户数在第N日仍启动该App的用户数占比的平均值。其中N通常取2、4、8、15、31,分别对应次日留存率、三日留存率、周留存率、半月留存率和月留存率。
留存率常用于反映用户粘性,当N取值越大、留存率越高时,用户粘性越高。
公式
新增用户留存率=新增用户中登录用户数/新增用户数*100%(一般统计周期为天)
新增用户数:在某个时间段(一般为第一整天)新登录应用的用户数;
登录用户数:登录应用后至当前时间,至少登录过一次的用户数;
第N日留存:指的是新增用户日之后的第N日依然登录的用户占新增用户的比例
第1日留存率(即“次留”):(当天新增的用户中,新增日之后的第1天还登录的用户数)/第一天新增总用户数;
第3日留存率:(当天新增的用户中,新增日之后的第3天还登录的用户数)/第一天新增总用户数;
第7日留存率:(当天新增的用户中,新增日之后的第7天还登录的用户数)/第一天新增总用户数;
第30日留存率:(当天新增的用户中,新增日之后的第30天还登录的用户数)/第一天新增总用户数;
- 偷个懒,算个“1日留存率”
分析
公式: 第1日留存率(即“次留”):(当天新增的用户中,新增日之后的第1天还登录的用户数)/第一天新增总用户数
从公式简单推理,只需要拿到“前一天新增用户数” 和 “前一天新增用户数今日登录数”
- 前一天新增用户数: 要获取新增的用户数,必须要有全量的用户列表,并且全量用户列表中应该有每个用户的注册时间(任务开始时,需要昨天的用户列表,计算当天的留存)
为了方便用户列表放到 mysql 中,表结构如下:
create table user_info
(
id bigint auto_increment primary key,
user_id bigint null,
register_day varchar(10) null comment '注册时间,格式yyyy-MM-dd',
create_time timestamp default CURRENT_TIMESTAMP null,
update_time timestamp default CURRENT_TIMESTAMP null
)
comment '用户注册时间';
user_info 表,全量用户列表,有每个用户的注册时间,任务启动时,加载全量用户列表,并提取昨日注册用户
- 新增日之后的第1天还登录的用户数: 已经有了昨日注册用户,这部分用户的登录就很容易获取
代码
flink 最近这几个版本用户界面的变化也挺多的,写个代码做个记录
任务 DAG 如下:
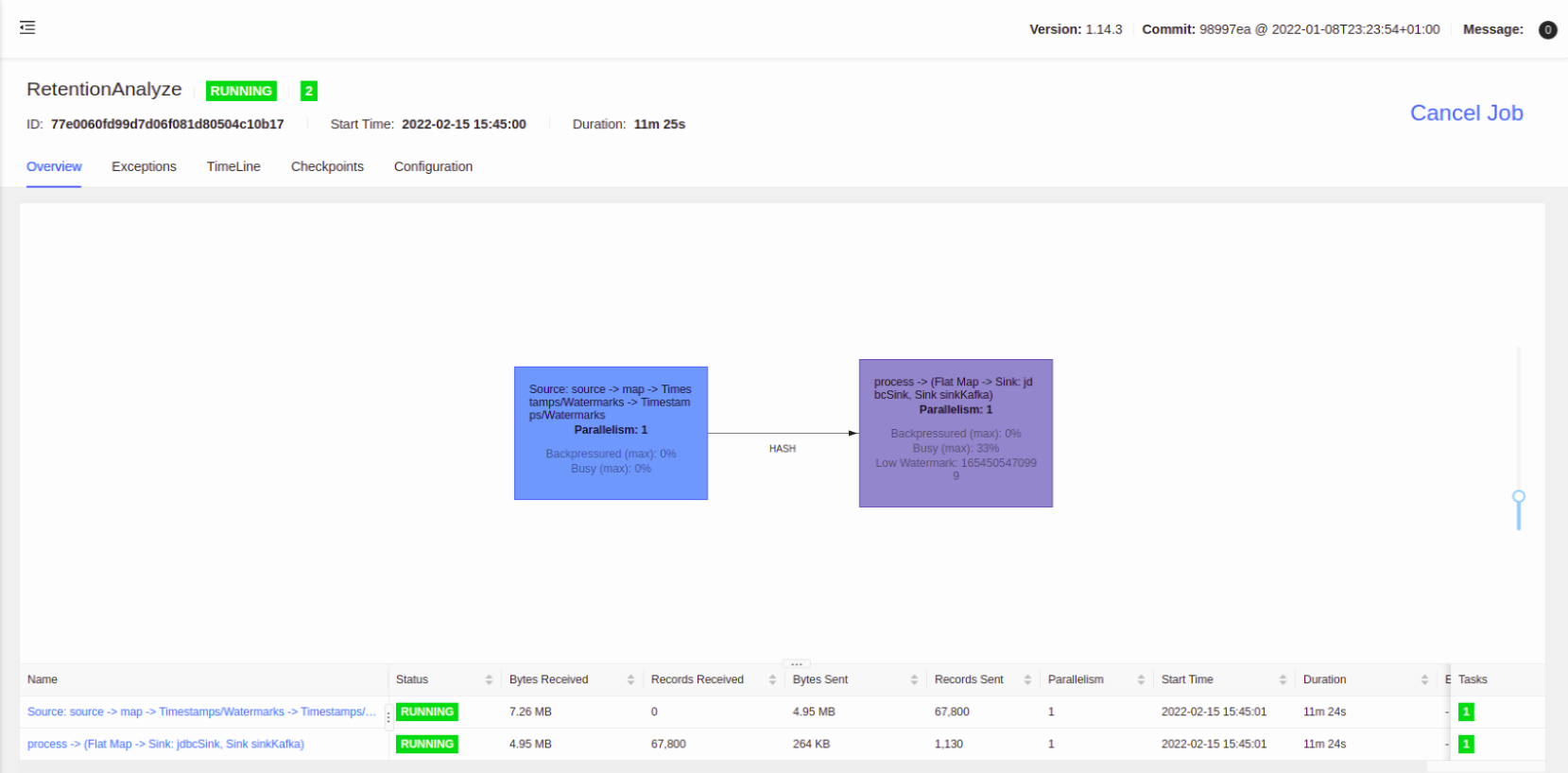
kafka source -> map 转换 json 成对象 -> 提取 timestamp -> 提取 watermark -> key 所以数据到一个 process -> window -> trigger -> process 计算 -> kafka sink 输出
Checkpoint 配置
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(5 * 60 * 1000)
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(5 * 60 * 1000)
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig.setCheckpointTimeout(10 * 60 * 1000)
// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(10)
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
env.getCheckpointConfig.setExternalizedCheckpointCleanup(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
// storage path
val checkpointStorage = new FileSystemCheckpointStorage(checkpointPath)
env.getCheckpointConfig.setCheckpointStorage(checkpointStorage)
// rocksdb
env.setStateBackend(new EmbeddedRocksDBStateBackend(true))
Kafka Source/Sink
val kafkaSource = KafkaSource
.builder[KafkaSimpleStringRecord]()
.setBootstrapServers(bootstrapServer)
.setGroupId("ra")
.setTopics(topic)
.setStartingOffsets(OffsetsInitializer.latest())
.setDeserializer(new SimpleKafkaRecordDeserializationSchema())
.build()
val kafkaSink = KafkaSink
.builder[String]()
.setBootstrapServers(bootstrapServer)
.setKafkaProducerConfig(Common.getProp)
.setRecordSerializer(KafkaRecordSerializationSchema.builder[String]()
.setTopic(sinkTopic)
.setKeySerializationSchema(new SimpleStringSchema())
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.build()
Kafka Source 自定义了一个 反序列化器 解析 Kafka 数据,将 TopicPartition、Offset、Key、Value、timestamp 添加到对象
public class KafkaSimpleStringRecord implements Serializable {
private static final long serialVersionUID = 4813439951036021779L;
// kafka topic partition
private final TopicPartition tp;
// record kafka offset
private final long offset;
// record key
private final String key;
// record timestamp
private final long timestamp;
// record value
private final String value;
}
Timestamp & Watermark
// default is IngestionTime, kafka source will add timestamp to StreamRecord,
// if not set assignAscendingTimestamps, use StreamRecord' timestamp, so is ingestion time
.assignAscendingTimestamps(userLog => DateTimeUtil.parse(userLog.ts).getTime)
// create watermark by all elements
.assignTimestampsAndWatermarks(new WatermarkStrategy[UserLog] {
override def createWatermarkGenerator(context: WatermarkGeneratorSupplier.Context): WatermarkGenerator[UserLog] = {
new WatermarkGenerator[UserLog] {
var watermark: Watermark = new Watermark(Long.MinValue)
override def onEvent(event: UserLog, eventTimestamp: Long, output: WatermarkOutput): Unit = {
val timestamp = DateTimeUtil.parse(event.ts).getTime
watermark = new Watermark(timestamp - 1)
output.emitWatermark(watermark)
}
override def onPeriodicEmit(output: WatermarkOutput): Unit = {
output.emitWatermark(watermark)
}
}
}
})
从数据中提取 ts 字段转为 Long 类型,作为数据的 timestamp
自定义 WatermarkGenerator,从每个输入数据中提取 ts 字段,创建 watermark(Flink 内部会过滤 当前 watermark 小于上一个 watermark 的 watermark)
窗口
天的窗口和10 分钟的 trigger
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.trigger(ContinuousEventTimeTrigger.of(Time.seconds(10 * 60)))
process 计算
open: 创建 状态对象
process: 从当日数据中计算昨日新增用户进入登录
clear: 每个窗口结束的时候,清空昨日新增用户map,将今日新增用户放入昨日新增用户map和全部用户map
open 方法
启动时调用,创建状态对象,连接 mysql,加载历史用户列表
/**
* open: load all user and last day new user
*
* @param parameters
*/
override def open(parameters: Configuration): Unit = {
LOG.info("RetentionAnalyzeProcessFunction open")
// create state
allUserState = getRuntimeContext.getState(new ValueStateDescriptor[util.HashMap[String, Int]]("allUser", classOf[util.HashMap[String, Int]]))
lastUserState = getRuntimeContext.getState(new ValueStateDescriptor[util.HashMap[String, Int]]("lastUser", classOf[util.HashMap[String, Int]]))
currentUserState = getRuntimeContext.getState(new ValueStateDescriptor[util.HashMap[String, Int]]("currentUser", classOf[util.HashMap[String, Int]]))
// connect mysql
reconnect()
// load history user
loadUser()
}
clear 方法
每个窗口结束的时候调用,用于处理窗口结束事件,在这里处理了一下 当天、昨日、全量用户map, side 当日用户
/**
* output current day new user
*
* @param context
*/
override def clear(context: Context): Unit = {
val window = context.window
LOG.info(String.format("window start : %s, end: %s, clear", DateTimeUtil.formatMillis(window.getStart, DateTimeUtil.YYYY_MM_DD_HH_MM_SS), DateTimeUtil.formatMillis(window.getEnd - 1, DateTimeUtil.YYYY_MM_DD_HH_MM_SS)))
// clear last user, add current user as last/all user map
lastUserMap.clear()
lastUserMap.putAll(currentUser)
allUserMap.putAll(currentUser)
lastUserState.update(lastUserMap)
allUserState.update(allUserMap)
// export current user to mysql userInfo
// exportCurrentUser(window)
val day = DateTimeUtil.formatMillis(window.getStart, DateTimeUtil.YYYY_MM_DD)
context.output(sideTag, (day, currentUser))
// currentUser.keySet().forEach(item => {
// context.output(sideTag, (day, item))
// })
// clear current user
currentUser.clear()
}
process 方法
创建一个 HashMap 用了存放昨日新增用户进入的登录情况,一个用户可以多次登录,所以用 map 重复的直接去掉
把不在 全量用户map 里的 user_id 放到 当天用户 map
// loop window element, find last user and current user
val it = elements.iterator
val lastUserLog = new util.HashMap[String, Int]
while (it.hasNext) {
val userLog = it.next()
if (lastUserMap.containsKey(userLog.userId)) {
lastUserLog.put(userLog.userId, 1)
}
if (!allUserMap.containsKey(userLog.userId)) {
currentUser.put(userLog.userId, 1)
}
}
如果昨日用户map 为 null,留存率为 0,反之,用 “昨日新增用户今日登录数 / 昨日新增用户数”(取 double)
var str: String = null
var retention: Double = 0
if (!lastUserMap.isEmpty) {
retention = lastUserLog.size().toDouble / lastUserMap.size()
}
str = day + "," + time + "," + allUserMap.size() + "," + lastUserMap.size() + "," + currentUser.size() + "," + retention
out.collect(str)
side 当日新增用户
写 mysql 有点慢,要比较长时间,就改用 side output 输出,还是慢(是 mysql 的原因,可以先写到 kafka,再转到 mysql),就这样了
// sink current day user to mysql, cost a lot time
val sideTag = new OutputTag[(String, util.HashMap[String, Int])]("side")
val jdbcSink = JdbcSink
.sink("insert into user_info(user_id, login_day) values(?, ?)", new JdbcStatementBuilder[(String, String)] {
override def accept(ps: PreparedStatement, element: (String, String)): Unit = {
ps.setString(1, element._2)
ps.setString(2, element._1)
}
}, JdbcExecutionOptions.builder()
.withBatchSize(100)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/venn?useUnicode=true&characterEncoding=utf8&useSSL=false&allowPublicKeyRetrieval=true")
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUsername("root")
.withPassword("123456")
.build())
stream.getSideOutput(sideTag)
.flatMap(new RichFlatMapFunction[(String, util.HashMap[String, Int]), (String, String)]() {
override def flatMap(element: (String, util.HashMap[String, Int]), out: Collector[(String, String)]): Unit = {
val day = element._1
val keySet = element._2.keySet()
keySet.forEach(item => {
out.collect((day, item))
})
}
})
.addSink(jdbcSink)
.name("jdbcSink")
.uid("jdbcSink")
测试数据
{"category_id":22,"user_id":"257054","item_id":"22732","behavior":"pv","ts":"2022-04-12 22:56:51.000"}
{"category_id":83,"user_id":"506782","item_id":"83818","behavior":"pv","ts":"2022-04-12 22:57:01.000"}
{"category_id":15,"user_id":"196658","item_id":"15335","behavior":"pv","ts":"2022-04-12 22:57:11.000"}
{"category_id":78,"user_id":"715098","item_id":"78131","behavior":"pv","ts":"2022-04-12 22:57:21.000"}
{"category_id":0,"user_id":"374494","item_id":"0714","behavior":"pv","ts":"2022-04-12 22:57:31.000"}
{"category_id":41,"user_id":"651691","item_id":"41995","behavior":"fav","ts":"2022-04-12 22:57:41.000"}
{"category_id":55,"user_id":"725849","item_id":"55589","behavior":"pv","ts":"2022-04-12 22:57:51.000"}
注: 为了方便测试,在模拟数据中给每条数据都递增 10 s,并且视所有数据都是用户登录
输出结果
逗号分割,依次为: 日期,时间,全量用户数,昨日新增用户数,今日新增用户数,留存率
第一天执行时无昨日数据,流程率为 0
后续执行就有留存率
2022-04-25,12:00:00,0,0,873,0.0
2022-04-25,12:10:00,0,0,933,0.0
2022-04-25,12:20:00,0,0,993,0.0
.....
2022-04-26,00:40:00,5170,5170,240,1.9342359767891682E-4
2022-04-26,00:50:00,5170,5170,300,1.9342359767891682E-4
2022-04-26,01:00:00,5170,5170,359,3.8684719535783365E-4
2022-04-26,01:10:00,5170,5170,419,3.8684719535783365E-4
每天的数据,随着登录的用户越来越多,留存率会越来越大
- 注: 每个窗口结束时会发现任务有积压,是写 mysql 比较慢,导致积压的,可以先写 kafka 再转 mysql
全部代码参考 Github flink-rookie
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号