

之前在 Lookup join mysql 的时候,因为只能使用 rowke 做关联键,所以一直想写个带缓存的 udtf,通过 udtf 的方式关联非主键的字段,同时由于 udf 里面加了缓存,所以用起来和 lookup join 差不多(关于 udf 的内容之前的博客已经写过了)。
最近实现了几个自定义的 TableSource,想着也实现一个 Lookup 的 Table Source,最近这段时间,花了点时间,自己写 + 从 Flink 源码里面抄,实现了一套自定义的 mysq Table Source 和 Lookup Source(随后可能还会有 Hbase 的 Lookup Source,或许也会写个 kudu 的)。
“参考” Flink 的 JdbcRowDataLookupFunction(大部分内容都是抄过来的,少造轮子,构造了和 Flink 源码里面一样的参数,主要 eval 方法就直接抄 Flink 源码了)
DynamicTableSource 有两种实现: ScanTableSource 和 LookupTableSource,需要先实现 ScanTableSource, LookupTableSource, 分别实现对应的的方法。
说明: LookupTableSource 也是一种 Table Source,不是 ScanTableSouce 的一部分。ScanTableSource 和 LookupTableSource 的选择,是在优化 SQL 的时候确定的。
核心代码:
override def translate(
modifyOperations: util.List[ModifyOperation]): util.List[Transformation[_]] = {
validateAndOverrideConfiguration()
if (modifyOperations.isEmpty) {
return List.empty[Transformation[_]]
}
val relNodes = modifyOperations.map(translateToRel)
// 优化 SQL
val optimizedRelNodes = optimize(relNodes)
val execGraph = translateToExecNodeGraph(optimizedRelNodes)
// 后续解析流程和 Stream Api 一样,用 transformations 生成 StreamGraph,再生成 JobGraph
val transformations = translateToPlan(execGraph)
cleanupInternalConfigurations()
transformations
}
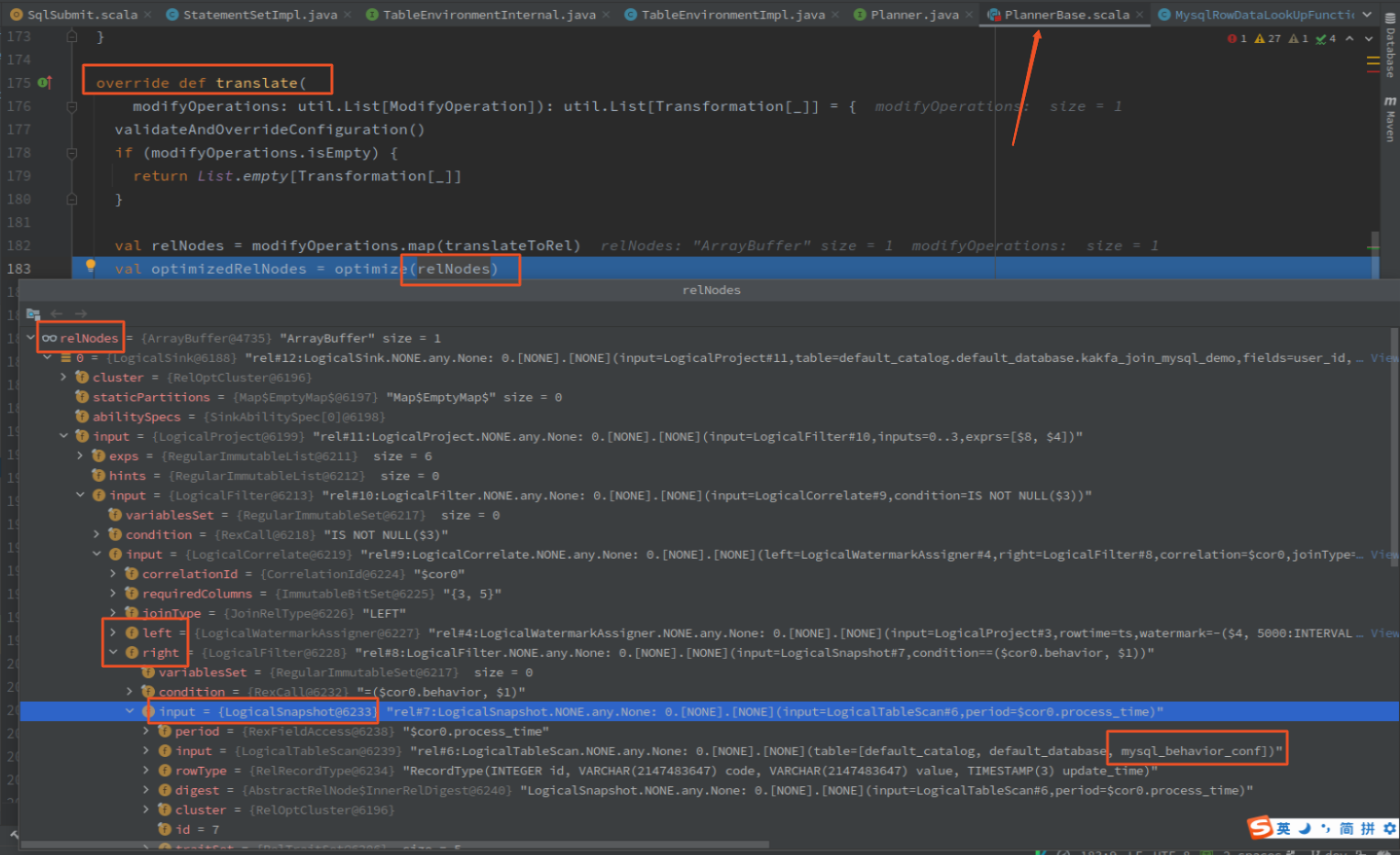
执行 optimize 之前:
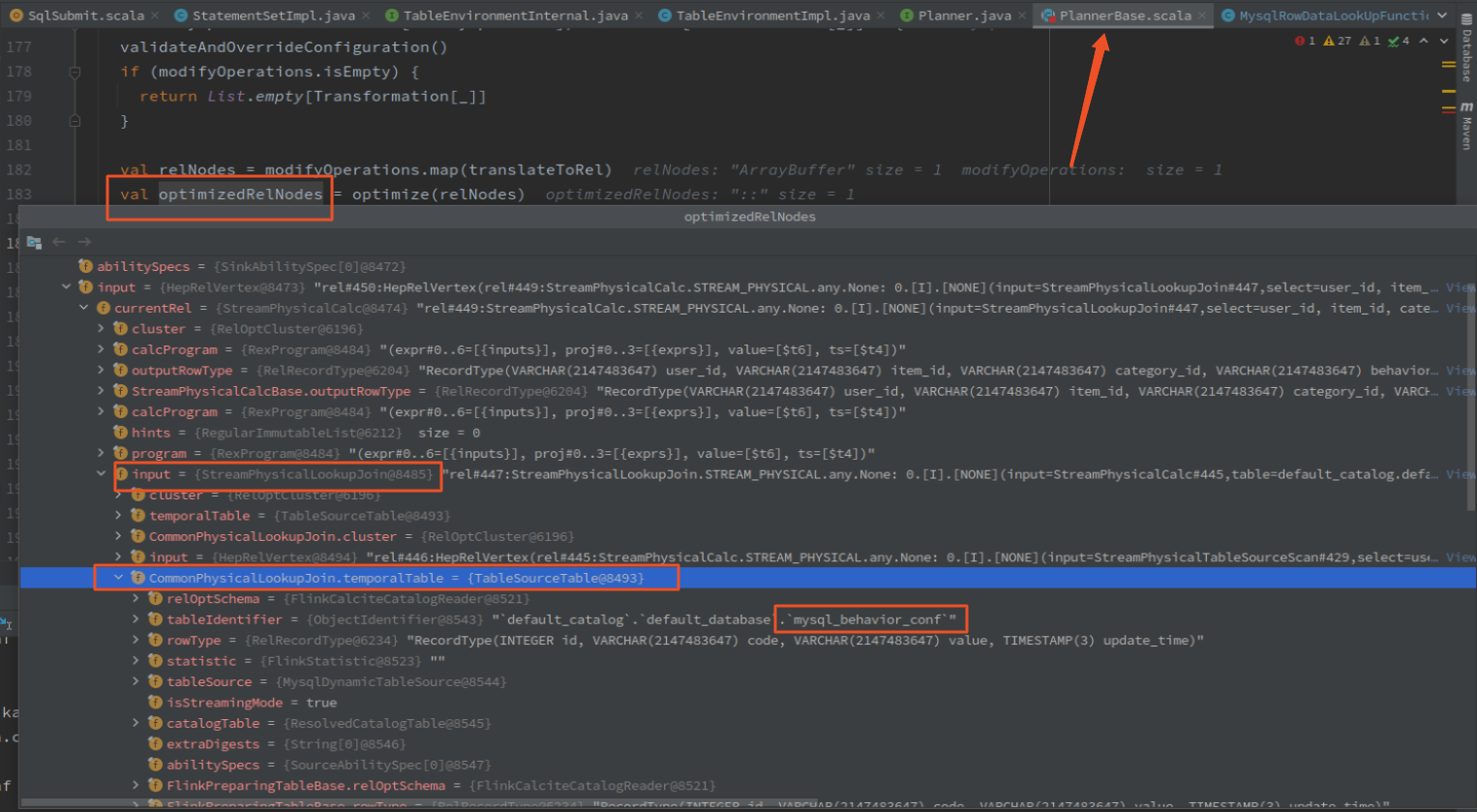
执行 optimize 之后:
实现
MysqlDynamicTableSource 实现 LookupTableSource 接口,实现对应的 getLookupRuntimeProvider 方法
@Override
public LookupRuntimeProvider getLookupRuntimeProvider(LookupContext context) {
if (lookupOption == null) {
lookupOption = new MysqlLookupOption.Builder()
.setCacheMaxSize(options.get(MysqlOption.CACHE_MAX_SIZE))
.setCacheExpireMs(options.get(MysqlOption.CACHE_EXPIRE_MS))
.setMaxRetryTimes(options.get(MysqlOption.MAX_RETRY_TIMES))
.build();
}
// 凑 MysqlRowDataLookUpFunction 需要的参数
final RowTypeInfo rowTypeInfo = (RowTypeInfo) fromDataTypeToLegacyInfo(producedDataType);
String[] fieldNames = rowTypeInfo.getFieldNames();
TypeInformation[] fieldTypes = rowTypeInfo.getFieldTypes();
int[] lookupKeysIndex = context.getKeys()[0];
int keyCount = lookupKeysIndex.length;
String[] keyNames = new String[keyCount];
for (int i = 0; i < keyCount; i++) {
keyNames[i] = fieldNames[lookupKeysIndex[i]];
}
final RowType rowType = (RowType) physicalSchema.toRowDataType().getLogicalType();
// new MysqlRowDataLookUpFunction
MysqlRowDataLookUpFunction lookUpFunction
= new MysqlRowDataLookUpFunction(url, username, password, table, fieldNames, keyNames, fieldTypes, lookupOption, rowType);
return TableFunctionProvider.of(lookUpFunction);
}
MysqlRowDataLookUpFunction 实现 TableFunction,核心代码如下
@Override
public void open(FunctionContext context) {
try {
establishConnectionAndStatement();
// cache, if not set "mysql.lookup.cache.max.size" and "mysql.lookup.cache.expire.ms", do not use cache
this.cache =
cacheMaxSize == -1 || cacheExpireMs == -1
? null
: CacheBuilder.newBuilder()
.expireAfterWrite(cacheExpireMs, TimeUnit.MILLISECONDS)
.maximumSize(cacheMaxSize)
.build();
} catch (SQLException sqe) {
throw new IllegalArgumentException("open() failed.", sqe);
}
}
/**
* method eval lookup key,
* search cache first
* if cache not exit, query third system
*
* @param keys query parameter
*/
public void eval(Object... keys) {
RowData keyRow = GenericRowData.of(keys);
// get row from cache
if (cache != null) {
List<RowData> cachedRows = cache.getIfPresent(keyRow);
if (cachedRows != null) {
for (RowData cachedRow : cachedRows) {
collect(cachedRow);
}
return;
}
}
// query mysql, retry maxRetryTimes count
for (int retry = 0; retry <= maxRetryTimes; retry++) {
try {
statement.clearParameters();
statement = lookupKeyRowConverter.toExternal(keyRow, statement);
try (ResultSet resultSet = statement.executeQuery()) {
if (cache == null) {
// if cache is null, loop to collect result
while (resultSet.next()) {
collect(jdbcRowConverter.toInternal(resultSet));
}
} else {
// cache is not null, loop to collect result, and save result to cache
ArrayList<RowData> rows = new ArrayList<>();
while (resultSet.next()) {
RowData row = jdbcRowConverter.toInternal(resultSet);
rows.add(row);
collect(row);
}
rows.trimToSize();
cache.put(keyRow, rows);
}
}
}
}
}
- 构造方法获取传入的参数
- open 方法初始化 mysql 连接,创建缓存对象
- eval 方法是执行查询的地方,先查缓存,再查 mysql
从整体来看,自定义Source,需要三个类: MysqlDynamicTableFactory -> MysqlDynamicTableSource -> MysqlRowDataLookUpFunction,Flink 通过 SPI 从 META-INF.services/org.apache.flink.table.factories.Factory 中注册 TableFactory
代码比较类似就不贴全部代码了,完整代码参考: GitHub
测试
建表语句
create temporary table mysql_behavior_conf(
id int
,code STRING
,`value` STRING
,update_time TIMESTAMP(3)
)WITH(
'connector' = 'cust-mysql'
,'mysql.url' = 'jdbc:mysql://localhost:3306/venn?useUnicode=true&characterEncoding=utf8&useSSL=false&allowPublicKeyRetrieval=true'
,'mysql.username' = 'root'
,'mysql.password' = '123456'
,'mysql.database' = 'venn'
,'mysql.table' = 'lookup_join_config'
,'mysql.lookup.cache.max.size' = '1'
,'mysql.lookup.cache.expire.ms' = '600000'
,'mysql.lookup.max.retry.times' = '3'
,'mysql.timeout' = '10'
)
;
insert
INSERT INTO kakfa_join_mysql_demo(user_id, item_id, category_id, behavior, behavior_map, ts)
SELECT a.user_id, a.item_id, a.category_id, a.behavior, c.`value`, a.ts
FROM user_log a
left join mysql_behavior_conf FOR SYSTEM_TIME AS OF a.process_time AS c
ON a.behavior = c.code
where a.behavior is not null;
任务执行图

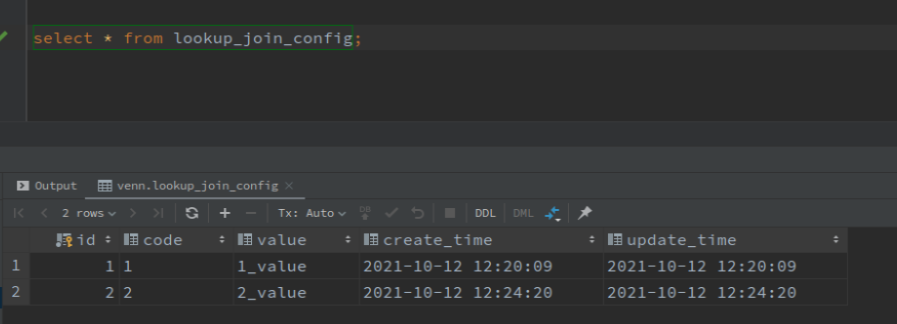
mysql 表数据:
输出结果:
+I[user_id_1, abc, category_id_1, 1, 1_value, 2021-10-18T14:59:04.111]
+I[user_id_2, abc, category_id_2, 2, 2_value, 2021-10-18T14:59:04.112]
+I[user_id_3, abc, category_id_3, 3, null, 2021-10-18T14:59:05.113]
+I[user_id_4, abc, category_id_4, 4, null, 2021-10-18T14:59:05.113]
+I[user_id_5, abc, category_id_5, 5, null, 2021-10-18T14:59:06.115]
+I[user_id_6, abc, category_id_6, 6, null, 2021-10-18T14:59:06.116]
+I[user_id_7, abc, category_id_7, 7, null, 2021-10-18T14:59:07.118]
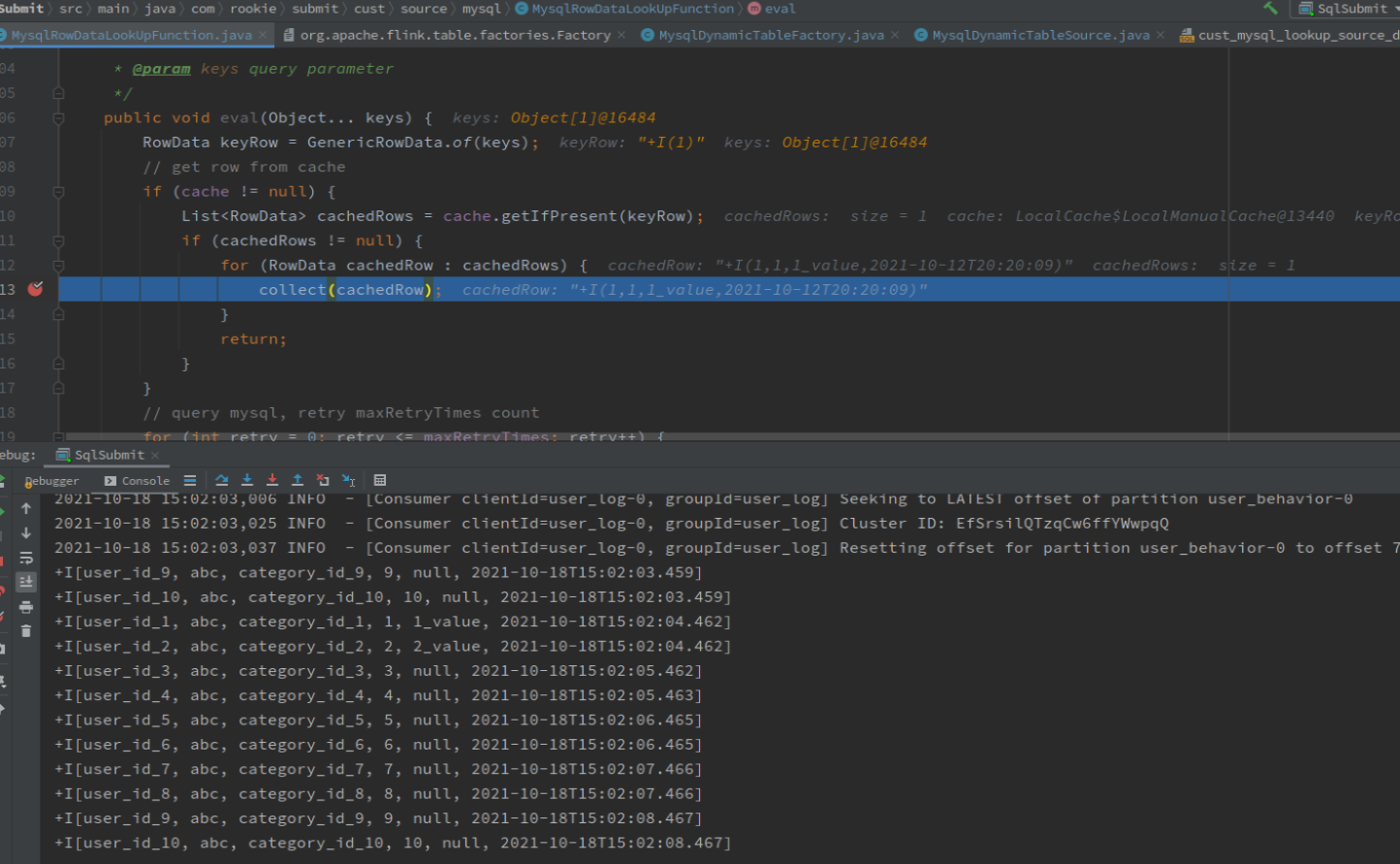
从缓存获取数据:
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号