
Hbase 作为 Hadoop 全家桶中,非常重要的存储组件,适用于海量数据的随机查询,使用是非常广泛的。
实时数仓项目使用 Kafka 作为数仓的基础表,我们也会把 Kafka 的数据往 Hbase 写一份,方便其他场景使用,比如:做维表
Flink Hbase 表默认使用 TableScan 一次性加载全量维表数据来关联,维表数据不能更新,适用场景比较少(由于 TableScan 完成后,算子状态为 Finish,导致任务不能完成 Checkpoint)
Flink Hbase 时态表 Lookup 功能(仅限于关联 Hbase 表主键,不支持非主键),支持缓存和透查外部系统,完美解决默认表维表数据不能更新和不能 完成 Checkpoint 的问题
关联 sql 如下
CREATE TEMPORARY TABLE hbase_behavior_conf ( rowkey STRING ,cf ROW(item_id STRING ,category_id STRING ,behavior STRING ,ts TIMESTAMP(3)) ) WITH ( 'connector' = 'hbase-2.2' ,'zookeeper.quorum' = 'thinkpad:12181' ,'table-name' = 'user_log' ,'lookup.cache.max-rows' = '10000' ,'lookup.cache.ttl' = '1 minute' -- ttl time 超过这么长时间无数据才行 ,'lookup.async' = 'true' ); INSERT INTO kakfa_join_mysql_demo(user_id, item_id, category_id, behavior, behavior_map, ts) SELECT a.user_id, a.item_id, a.category_id, a.behavior, c.cf.item_id, a.ts FROM user_log a left join hbase_behavior_conf FOR SYSTEM_TIME AS OF a.process_time AS c ON a.user_id = rowkey -- 主键 -- left join hbase_behavior_conf FOR SYSTEM_TIME AS OF a.process_time AS c ON a.user_id = cf.item_id --非主键 where a.behavior is not null;
关联非主键报错如下:
Caused by: java.lang.IllegalArgumentException: Currently, HBase table can only be lookup by single rowkey. at org.apache.flink.util.Preconditions.checkArgument(Preconditions.java:138) at org.apache.flink.connector.hbase2.source.HBaseDynamicTableSource.getLookupRuntimeProvider(HBaseDynamicTableSource.java:52) at org.apache.flink.table.planner.plan.utils.LookupJoinUtil.getLookupFunction(LookupJoinUtil.java:172) at org.apache.flink.table.planner.plan.nodes.physical.common.CommonPhysicalLookupJoin.explainTerms(CommonPhysicalLookupJoin.scala:168) at org.apache.calcite.rel.AbstractRelNode.getDigestItems(AbstractRelNode.java:409) at org.apache.calcite.rel.AbstractRelNode.deepHashCode(AbstractRelNode.java:391) at org.apache.calcite.rel.AbstractRelNode$InnerRelDigest.hashCode(AbstractRelNode.java:443) at java.util.HashMap.hash(HashMap.java:339) at java.util.HashMap.get(HashMap.java:557) at org.apache.calcite.plan.volcano.VolcanoPlanner.registerImpl(VolcanoPlanner.java:1150) at org.apache.calcite.plan.volcano.VolcanoPlanner.register(VolcanoPlanner.java:589) at org.apache.calcite.plan.volcano.VolcanoPlanner.ensureRegistered(VolcanoPlanner.java:604) at org.apache.calcite.plan.volcano.VolcanoRuleCall.transformTo(VolcanoRuleCall.java:148) ... 45 more
Flink 关联 Hbase 场景也有关联非主键的场景,刚开始用的时候,为了方便就直接实现一个 UDF,启动的时候加载全量的 Hbase 表数据到内存中(维表数据并不多),根据策略定期去Hbase 重新加载最新的数据。
受 Lookup Source 的启发,想实现一个关联 Hbase 非主键的 UDF,支持缓存和缓存失效透查 Hbase
需求如下:
1、UDF 关联 Hbase 表非主键
2、支持缓存时间和缓存数量的控制
3、关联键缓存有值就从缓存出
4、关联键缓存没有值就从 Hbase 查,结果放到缓存中
基于这些需求,实现了这样的一个 UDTF(由于 Hbase 表非主键可能有重复值,所以使用 Table Function,如果有多条数据,返回多条数据到 SQL 端处理)
## UDF 代码
@FunctionHint(output = new DataTypeHint("ROW<arr ARRAY<STRING>>")) def eval(key: String): Unit = { // if key is empty if (key == null || key.length == 0) { return } // insert val rowKind = RowKind.fromByteValue(0.toByte) val row = new Row(rowKind, 1) // get result from cache var list: ListBuffer[Array[String]] = cache.getIfPresent(key) if (list != null) { list.foreach(arr => { row.setField(0, arr) collect(row) }) return } // cache get nothing, query hbase list = queryHbase(key) if (list.length == 0) { // if get nothing return } // get result, add to cache cache.put(key, list) list.foreach(arr => { row.setField(0, arr) collect(row) }) // LOG.info("finish join key : " + key) } /** * query hbase * * @param key join key * @return query result row */ private def queryHbase(key: String): ListBuffer[Array[String]] = { val scan: Scan = new Scan(); qualifier.foreach(item => scan.addColumn(family, item)) val filter = new SingleColumnValueFilter(family, qualifier.head, CompareOperator.EQUAL, key.getBytes("UTF8")) scan.setFilter(filter) val resultScanner = table.getScanner(scan) val it = resultScanner.iterator() val list = new ListBuffer[Array[String]] // loop result while (it.hasNext) { val result = it.next() val arr = new Array[String](qualifier.length + 1) // add rowkey to result array var index = 0 val rowkey = new String(result.getRow) arr(index) = rowkey // add special qualify to result array qualifier.foreach(item => { val value = result.getValue(family, item) if (value != null) { index += 1 arr(index) = new String(value, "UTF8") } }) // add array to result list.+=(arr) } list }
## 测试 SQL
-- kafka source CREATE TABLE user_log ( user_id STRING ,item_id STRING ,category_id STRING ,behavior STRING ,ts TIMESTAMP(3) ,process_time as proctime() -- , WATERMARK FOR ts AS ts - INTERVAL '5' SECOND ) WITH ( 'connector' = 'kafka' ,'topic' = 'user_behavior' ,'properties.bootstrap.servers' = 'localhost:9092' ,'properties.group.id' = 'user_log' ,'scan.startup.mode' = 'group-offsets' ,'format' = 'json' ); ---sinkTable CREATE TABLE join_hbbase_sink ( user_id STRING ,item_id STRING ,category_id STRING ,behavior STRING ,ts TIMESTAMP(3) ,rowkey STRING ,c1 STRING ,c2 STRING ,c3 STRING ,c4 STRING ,primary key (user_id) not enforced ) WITH ( 'connector' = 'upsert-kafka' ,'topic' = 'user_behavior_1' ,'properties.bootstrap.servers' = 'localhost:9092' ,'properties.group.id' = 'user_log' ,'key.format' = 'csv' ,'value.format' = 'csv' ); INSERT INTO join_hbbase_sink SELECT a.user_id, a.item_id, a.category_id, a.behavior, a.ts, t2.col[1], t2.col[2], t2.col[3], t2.col[4], t2.col[5] FROM user_log a -- left join lateral table(udf_join_hbase_non_rowkey_no_cache(item_id)) as t2(col) on true left join lateral table(udf_join_hbase_non_rowkey_cache(item_id)) as t2(col) on true where a.item_id is not null -- and t2.col[1] = a.item_id -- 返回多条数据可以在 where 条件后面过滤 ;
## 测试Hbase 表
hbase(main):014:0> count 'user_info' Current count: 1000, row: 0999 Current count: 2000, row: 2 Current count: 3000, row: 3 Current count: 4000, row: 4 Current count: 5000, row: 5 Current count: 6000, row: 6 Current count: 7000, row: 7 Current count: 8000, row: 8 Current count: 9000, row: 9 9999 row(s) Took 0.5151 seconds => 9999 hbase(main):015:0> get 'user_info','0001' COLUMN CELL cf:c1 timestamp=1632311933302, value=0001 # 关联键 cf:c10 timestamp=1632311933302, value=\xED\x9E\x99\xDE\x88\xE6\xB4\x92\xE6\x90\x9D\xEC\x84\x88\xEC\xA0\x89\xE3\x97\xA6\xEB\xB3\xAF\xE6\x9B\x91\xE6\xBC\x9B\xE8\xB0\x 81\xE7\x89\xB2\xE6\xBE\x94\xEC\x8C\xB8\xEB\x86\xA6 cf:c2 timestamp=1632311933302, value=\xE7\x8F\xAD\xE7\x99\x83\xED\x80\x98\xE0\xAB\x86\xEB\xB0\x9A\xE7\xB8\x8B\xE7\xA2\xA8\xE8\x9F\xBF\xE8\xBF\x82\xEB\x9F\x86\xEB\x 8B\xB8\xE4\x96\x82\xE7\xBC\xA0\xED\x99\xB8\xE9\xAE\x89 cf:c3 timestamp=1632311933302, value=\xE3\x8A\xA6\xE8\xAB\xA5\xE7\x80\xA2\xE3\x83\xAF\xE3\x9D\xA5\xEC\xBA\x86\xE4\xA0\xB7\xEA\xB4\x83\xE5\xAC\x8D\xE3\x9F\xB0\xE6\x B1\xAB\xD6\x8B\xD7\xB8\xE2\xBB\xB4\xE1\xB5\xA6 cf:c4 timestamp=1632311933302, value=\xE3\xA5\x95\xE9\x80\xA1\xE8\x9B\xB5\xE4\xBB\xB1\xD8\x90\xE2\x82\xA7\xEC\x98\xA6\xE6\xA5\xA0\xEB\xB1\xBE\xEB\xAD\x8A\xE7\xAB\x B3\xE6\xB7\xB6\xEA\x89\xA3\xED\x92\xBE\xE4\xBC\x9B cf:c5 timestamp=1632311933302, value=\xE9\xA0\x91\xE2\x93\x86\xE6\x86\xA0\xE1\x85\xA7\xE5\xB9\x84\xE7\x9F\xB7\xE3\x99\x88\xE2\xAF\x8F\xE3\x80\x84\xEC\xB9\xAD\xE6\x 92\xB7\xE3\x91\xB7\xE9\x94\xB8\xEA\x85\x9C\xE2\x90\xAB cf:c6 timestamp=1632311933302, value=\xE9\xBF\xBA\xE2\x9A\x80\xEA\x81\x99\xEC\x99\xA1\xE3\xB1\x83\xE0\xBF\xA4\xE7\x8C\x8E\xE2\x9B\xB5\xE6\xAB\xBD\xE9\xBB\x9E\xE8\x 96\xA2\xEA\x8E\xAF\xE5\x98\xBA\xE3\x83\x8C\xE1\x91\x8F cf:c7 timestamp=1632311933302, value=\xEA\x8D\x89\xE9\x87\xAC\xEA\xB9\xBB\xE3\x93\xBC\xE4\xAB\xAA\xEB\xA2\x9B\xE3\x85\x90\xEC\x93\xB9\xE8\x9A\x84\xE2\xBF\x82\xE7\x A4\xA7\xEA\xB5\xB6\xE2\x8F\xBC\xE0\xAC\x80\xE6\xB1\xA9 cf:c8 timestamp=1632311933302, value=\xE1\x82\x8F\xE3\xAB\xBE\xE7\x92\x93\xE5\x97\xA0\xE1\xA0\x93\xC6\xBE\xE0\xB6\xA5\xE3\xB4\x93\xEC\x9D\xB3\xC5\x89\xE3\x98\xB2\x E8\x91\x8E\xC2\xA3\xE4\xB3\x90\xE5\x87\xA8 cf:c9 timestamp=1632311933302, value=\xEA\x80\xB8\xEC\xAD\x8F\xEB\x95\x91\xD8\xB6\xE8\x90\xAE\x5C\xE5\x85\x95\xEC\x89\x83\xCC\xAF\xE5\xA4\x8B\xE4\x88\x99\xEB\xBA\x 88\xE1\xA4\xB8\xEA\x9E\x99\xE6\x9B\x8F 1 row(s) Took 0.0446 seconds
Flink 任务:
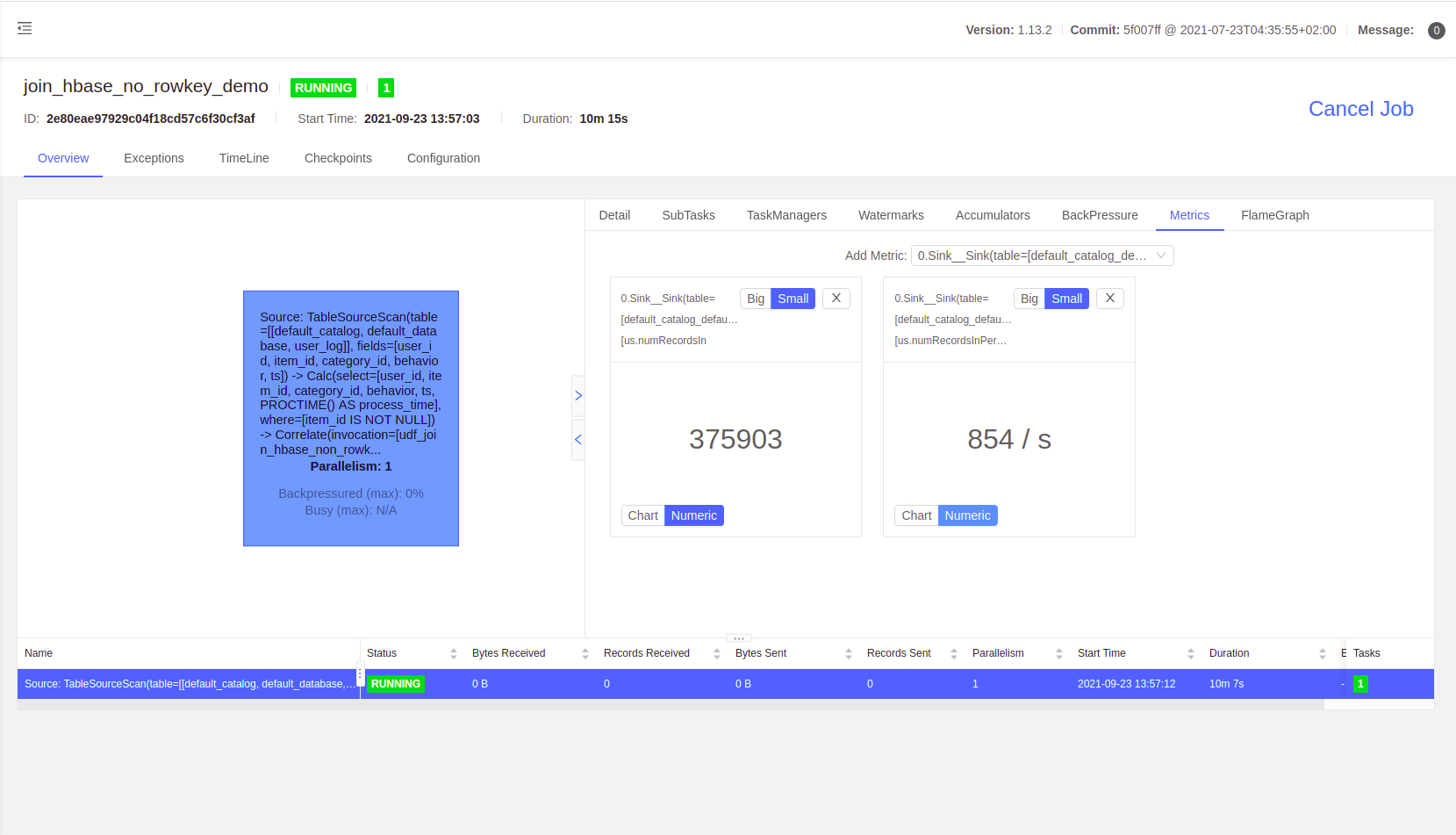
hbase 表: 10000 条数据,非主键关联测试,关联键值10000条不重复,缓存时间 10 min
笔记本 on yarn 测试 TPS: 850+ (基本可用,服务器环境应该会好很多,不够还可以加并行度)
改进点:
1、将 UDF 改为基于配置的
2、将关联字段改成支持多个字段
3、修改 Hbase connector 源码,支持关联非主键的 Lookup join
完整案例参考 GitHub: https://github.com/springMoon/sqlSubmit
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号