
Kudu 是现在比较火的一款存储引擎,集HDFS的顺序读和HBase的随机读于一身,非常适合物流网场景,刚刚到达的数据就马上要被终端用户使用访问到,未来还要做大规模的数据分析。
kudu 适合的场景(以下内容来自网络):
1. 适用于那些既有随机访问,也有批量数据扫描的复合场景 2. CPU密集型的场景 3. 使用了高性能的存储设备,包括使用更多的内存 4. 要求支持数据更新,避免数据反复迁移的场景 5. 支持跨地域的实时数据备份和查询
最近感觉在批量读 hbase 上遇到了瓶颈,急需寻找新的解决方案,这是时候看到了 kudu,看了介绍,感觉非常适合我们的场景:物流网场景,设备上传的数据,需要实时查询,又需要对设备时间范围内的数据做批量分析。
在把数据写到 kudu,目前 flink 还没有官方的 connector,只能使用第三方 bahir 提供的包,比较遗憾的是 bahir-flink 中 kudu 的 connector 还没有发布,目前只能自己在 github 下载 bahir-flink 的源代码自己编译(好消息是编译很简单)。
bahir-flink : https://github.com/apache/bahir-flink/tree/master/flink-connector-kudu
sqlSubmit 添加 flink-connector-kudu 依赖:
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-kudu_2.11</artifactId>
<version>1.1-SNAPSHOT</version>
</dependency>
sql 如下:
-- kafka source drop table if exists user_log; CREATE TABLE user_log ( user_id VARCHAR ,item_id VARCHAR ,category_id VARCHAR ,behavior INT ,ts TIMESTAMP(3) ,process_time as proctime() , WATERMARK FOR ts AS ts ) WITH ( 'connector' = 'kafka' ,'topic' = 'user_behavior' ,'properties.bootstrap.servers' = 'venn:9092' ,'properties.group.id' = 'user_log_x' ,'scan.startup.mode' = 'group-offsets' ,'format' = 'json' ); -- kafka sink drop table if exists user_log_sink; CREATE TABLE user_log_sink ( user_id STRING ,item_id STRING ,category_id STRING ,ts TIMESTAMP(3) ) WITH ( 'connector.type' = 'kudu' ,'kudu.masters' = 'venn:7051,venn:7151,venn:7251' ,'kudu.table' = 'user_log' ,'kudu.hash-columns' = 'user_id' ,'kudu.primary-key-columns' = 'user_id' ,'kudu.max-buffer-size' = '5000' ,'kudu.flush-interval' = '1000' ); -- insert insert into user_log_sink select user_id, item_id, category_id,ts from user_log;
查看数据:
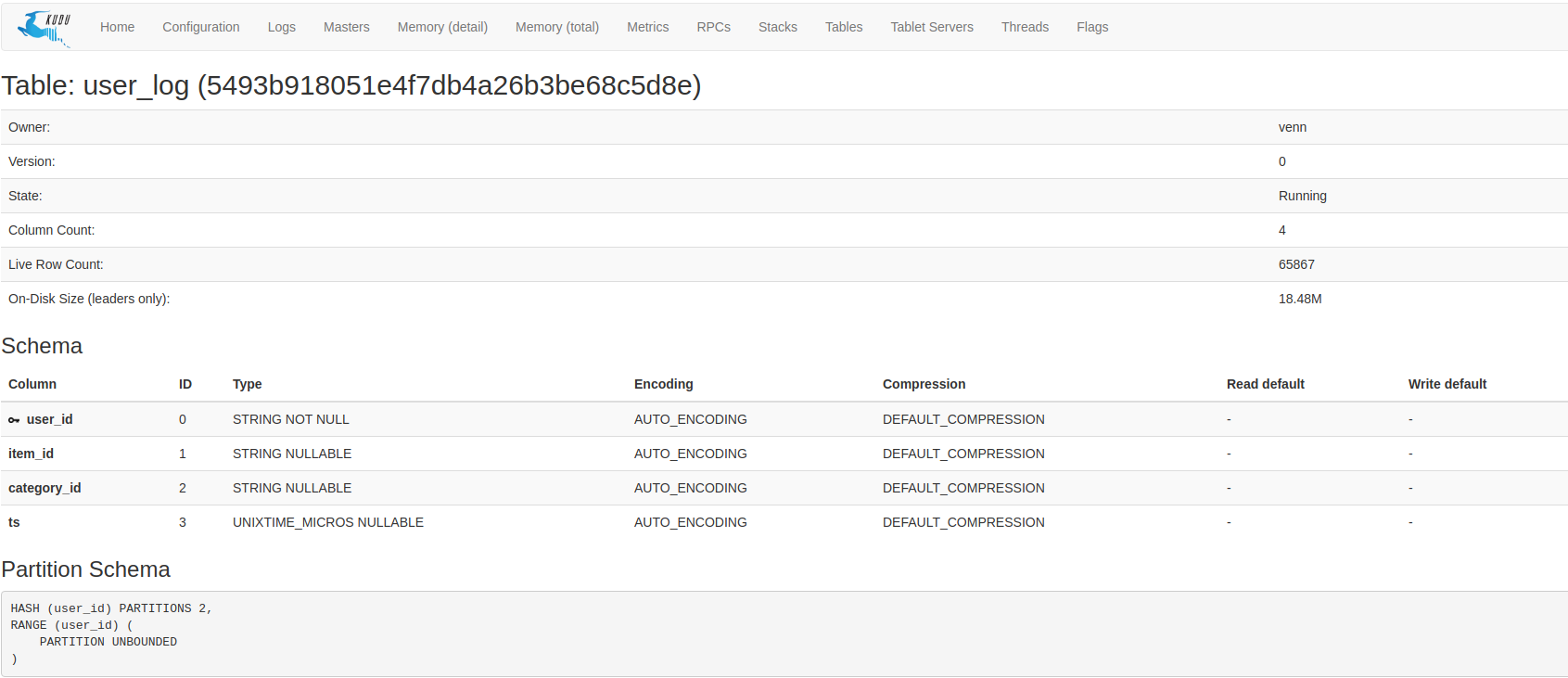
java api 读取数据
private void queryData() throws KuduException { KuduClient client = new KuduClient.KuduClientBuilder(KUDU_MASTER).build(); KuduTable table = client.openTable(TABLE_NAME); Schema schema = table.getSchema(); KuduScanner scanner = null; try { List<String> projectColumn = new ArrayList<>(); projectColumn.add("user_id"); projectColumn.add("item_id"); projectColumn.add("category_id"); projectColumn.add("ts"); KuduPredicate lowPredicate = KuduPredicate.newComparisonPredicate(schema.getColumn("user_id"), KuduPredicate.ComparisonOp.GREATER_EQUAL, " "); KuduPredicate upPredicate = KuduPredicate.newComparisonPredicate(schema.getColumn("user_id"), KuduPredicate.ComparisonOp.LESS_EQUAL, "~"); scanner = client.newScannerBuilder(table) .setProjectedColumnNames(projectColumn) .addPredicate(lowPredicate) .addPredicate(upPredicate) .build(); long start = System.currentTimeMillis(); int count = 0; while (scanner.hasMoreRows()) { RowResultIterator results = scanner.nextRows(); while (results.hasNext()) { RowResult result = results.next(); StringBuilder builder = new StringBuilder(); List<ColumnSchema> list = result.getSchema().getColumns(); for (ColumnSchema schema1 : list) { String columnName = schema1.getName(); Type columnType = schema1.getType(); switch (columnType) { case STRING: { String tmp = result.getString(columnName); if (!result.isNull(columnName)) { builder.append(columnName + " : " + tmp).append(", "); } break; } case UNIXTIME_MICROS: { if (!result.isNull(columnName)) { Timestamp ts = result.getTimestamp(columnName); builder.append(columnName + " : " + DateTimeUtil.formatMillis(ts.getTime(), DateTimeUtil.YYYY_MM_DD_HH_MM_SS)); } break; } case INT8: { if (!result.isNull(columnName)) { byte tmp = result.getByte(columnName); builder.append(columnName + " : " + tmp); } break; } default: { builder.append(columnName + " : "); } } } System.out.println(builder.toString()); ++count; } } System.out.println("result count : " + count); long end = System.currentTimeMillis(); System.out.println("cost : " + (end - start)); } finally { if (scanner != null) { scanner.close(); } client.shutdown(); } }
输出如下:
user_id : user_id_9982, item_id : item_id_1, category_id : category_id_1, ts : 2021-04-16 16:14:45 user_id : user_id_9986, item_id : item_id_9, category_id : category_id_9, ts : 2021-04-16 16:14:45 user_id : user_id_9989, item_id : item_id_2, category_id : category_id_2, ts : 2021-04-16 16:14:45 user_id : user_id_9991, item_id : item_id_8, category_id : category_id_8, ts : 2021-04-16 16:14:45 user_id : user_id_9992, item_id : item_id_2, category_id : category_id_2, ts : 2021-04-16 16:14:45 user_id : user_id_9994, item_id : item_id_3, category_id : category_id_3, ts : 2021-04-16 16:14:45 user_id : user_id_9995, item_id : item_id_7, category_id : category_id_7, ts : 2021-04-16 16:14:45 user_id : user_id_9999, item_id : item_id_7, category_id : category_id_7, ts : 2021-04-16 16:14:45 result count : 65867 cost : 863
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号