
本文基于 flink 1.12.0
top n 官网: https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/sql/queries.html#top-n
## sql
flink top n sql 如下,top n的写法支持如下两种:
1、rownum > 3 and rownum < 10 ( 如果 只写 rownum < 10 默认是 > 1 , 排名默认是从 1开始)
2、where rownum < source_table.column (rownum 的值小于源表,输入的第一条数据的一个列值)

insert into user_log_sink(user_id, item_id, category_id,behavior,sales,ts,sort_col)
SELECT user_id, item_id, category_id,behavior,sales,sort_col,ts
FROM (
SELECT user_id, item_id, category_id,behavior,sales, ts, sort_col,
ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY ts desc) AS rownum
FROM user_log)
WHERE rownum < sort_col
-- WHERE rownum < 5
-- 只支持两种 top n:
-- rownum < 10 or rownum > 3 and rownum < 10
-- rownum < source_table.column
-- rownum > 3 是不支持的: Rank end is not specified. Currently rank only support TopN, which means the rank end must be specified.
-- 不输出 rownum 可以启动无排名优化,仅输出当前数据,对历史数据的排名更新,不再输出
## Top N 基类 AbstractTopNFunction
Top N 根据数据源包含的数据内容(Insert、Update、Delete 消息),支持 UndefinedStrategy、AppendFastStrategy、RetractStrategy、UpdateFastStrategy 四种处理策略(源码参见: RankProcessStrategy) 对应三个处理子类: AppendOnlyTopNFunction、UpdatableTopNFunction、RetractableTopNFunction,这里只讨论 AppendOnlyTopNFunction,类图如下:
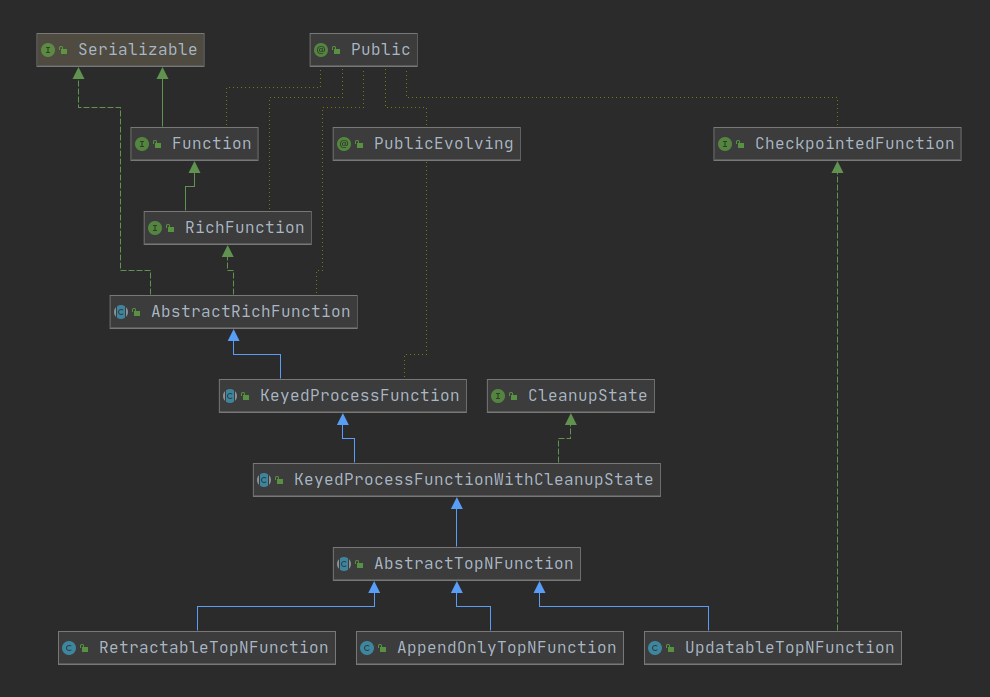
源码解析:
AbstractTopNFunction(
long minRetentionTime,
long maxRetentionTime,
InternalTypeInfo<RowData> inputRowType,
GeneratedRecordComparator generatedSortKeyComparator,
RowDataKeySelector sortKeySelector,
RankType rankType,
RankRange rankRange,
boolean generateUpdateBefore,
boolean outputRankNumber) {
// 调用父类的构造函数,设置状态保留最小、最大的时间
super(minRetentionTime, maxRetentionTime);
// TODO support RANK and DENSE_RANK
// 只支持 ROW_NUMBER, 其他直接抱错
switch (rankType) {
case ROW_NUMBER:
break;
case RANK:
LOG.error(RANK_UNSUPPORTED_MSG);
throw new UnsupportedOperationException(RANK_UNSUPPORTED_MSG);
case DENSE_RANK:
LOG.error(DENSE_RANK_UNSUPPORTED_MSG);
throw new UnsupportedOperationException(DENSE_RANK_UNSUPPORTED_MSG);
default:
LOG.error("Streaming tables do not support {}", rankType.name());
throw new UnsupportedOperationException(
"Streaming tables do not support " + rankType.toString());
}
if (rankRange instanceof ConstantRankRange) {
// rank 的 start 和 end 是常量
ConstantRankRange constantRankRange = (ConstantRankRange) rankRange;
isConstantRankEnd = true;
rankStart = constantRankRange.getRankStart();
rankEnd = constantRankRange.getRankEnd();
rankEndIndex = -1;
} else if (rankRange instanceof VariableRankRange) {
// rank 的 end 是变量,没有 start
VariableRankRange variableRankRange = (VariableRankRange) rankRange;
rankEndIndex = variableRankRange.getRankEndIndex();
isConstantRankEnd = false;
rankStart = -1;
rankEnd = -1;
} else {
// 其他的都不支持
LOG.error(WITHOUT_RANK_END_UNSUPPORTED_MSG);
throw new UnsupportedOperationException(WITHOUT_RANK_END_UNSUPPORTED_MSG);
}
this.generatedSortKeyComparator = generatedSortKeyComparator;
this.generateUpdateBefore = generateUpdateBefore;
this.inputRowType = inputRowType;
// 是否输出 行号,这个涉及到无行号输出优化
this.outputRankNumber = outputRankNumber;
this.sortKeySelector = sortKeySelector;
}
```java
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
initCleanupTimeState("RankFunctionCleanupTime");
outputRow = new JoinedRowData();
if (!isConstantRankEnd) {
// rank end 值状态,没有 ttl 即 rank end 值,一直不变
ValueStateDescriptor<Long> rankStateDesc = new ValueStateDescriptor<>(
"rankEnd",
Types.LONG);
rankEndState = getRuntimeContext().getState(rankStateDesc);
}
// compile comparator
sortKeyComparator = generatedSortKeyComparator.newInstance(getRuntimeContext().getUserCodeClassLoader());
generatedSortKeyComparator = null;
invalidCounter = getRuntimeContext().getMetricGroup().counter("topn.invalidTopSize");
// initialize rankEndFetcher
if (!isConstantRankEnd) {
// rank end 不是常量的,即是变量值做为 rank end, 获取 rank end 值的函数
LogicalType rankEndIdxType = inputRowType.toRowFieldTypes()[rankEndIndex];
switch (rankEndIdxType.getTypeRoot()) {
case BIGINT:
rankEndFetcher = (RowData row) -> row.getLong(rankEndIndex);
break;
case INTEGER:
rankEndFetcher = (RowData row) -> (long) row.getInt(rankEndIndex);
break;
case SMALLINT:
rankEndFetcher = (RowData row) -> (long) row.getShort(rankEndIndex);
break;
default:
LOG.error(
"variable rank index column must be long, short or int type, while input type is {}",
rankEndIdxType.getClass().getName());
throw new UnsupportedOperationException(
"variable rank index column must be long type, while input type is " +
rankEndIdxType.getClass().getName());
}
}
}
/**
* Initialize rank end.
*
* @param row input record
*
* @return rank end
*
* @throws Exception
*/
protected long initRankEnd(RowData row) throws Exception {
if (isConstantRankEnd) {
// 常量 rank end,直接返回
return rankEnd;
} else {
// 变量 rank end 从输入数据中提取
Long rankEndValue = rankEndState.value();
long curRankEnd = rankEndFetcher.apply(row);
// 状态为空时
if (rankEndValue == null) {
rankEnd = curRankEnd;
// 初始化去重 rownum 的最大
rankEndState.update(rankEnd);
return rankEnd;
} else {
rankEnd = rankEndValue;
if (rankEnd != curRankEnd) {
// increment the invalid counter when the current rank end not equal to previous rank end
// metrics + 1
invalidCounter.inc();
}
return rankEnd;
}
}
}
protected boolean checkSortKeyInBufferRange(RowData sortKey, TopNBuffer buffer) {
// 获取 比较器
Comparator<RowData> comparator = buffer.getSortKeyComparator();
// 获取 buffer 的最后一个值
Map.Entry<RowData, Collection<RowData>> worstEntry = buffer.lastEntry();
if (worstEntry == null) {
// 最后一个值为 null,说明没数据,就在范围以内
// return true if the buffer is empty.
return true;
} else {
// 获取最后一行的 row 的 排序字段值
RowData worstKey = worstEntry.getKey();
// 比较 当前值和缓存值
int compare = comparator.compare(sortKey, worstKey);
// 如果当前值小于 缓存值,输出,不然要判断是否超过了 rank end,没有超过也可以输出
if (compare < 0) {
return true;
} else {
return buffer.getCurrentTopNum() < getDefaultTopNSize();
}
}
}
## AppendOnlyTopNFunction 只插入的 topN 处理方法
AppendOnlyTopNFunction 就是个 Process function, 数据处理的方法是 processElement,数据的处理工作,还包含一些初始化的操作(keyed 的process 方法,状态的初始化是不能在 open 函数中做的)
1、先调用了状态清楚的定时器,如果超过状态保留时间,定时删除对应 key 的状态,使 Top N 重新计数
2、初始化 Top N 在 heap 内存中的缓存对象 buffer
3、初始化 Top N 的 rank end 值(非常量做 rank end 的需要从数据中提取)
4、再是判断数据是否在 Top N 的范围内
5、如果在范围内,将输入数据放入缓存和对应的状态
6、再根据是否输出 rownum,具体数量输入数据的排名和数据输出(其中 rownum > 3, 逻辑的处理,是在 父类的数据输出的部分判断, 如: AbstractTopNFunction.collectInsert)
public void processElement(RowData input, Context context, Collector<RowData> out) throws Exception {
long currentTime = context.timerService().currentProcessingTime();
// register state-cleanup timer
// 注册清理状态的定时器
registerProcessingCleanupTimer(context, currentTime);
// 初始化状态 topn heap 状态 (就是 buffer, 异常恢复的时候会将状态中的数据写到 buffer 中)
initHeapStates();
// 初始化 rank end 值
initRankEnd(input);
// 获取行中排序列的值
RowData sortKey = sortKeySelector.getKey(input);
// check whether the sortKey is in the topN range
// 判断当前数据的 排序字段内容,是否在 top n 范围
if (checkSortKeyInBufferRange(sortKey, buffer)) {
// insert sort key into buffer
// 满足条件的数据,将当前值放入 buffer 缓存中
buffer.put(sortKey, inputRowSer.copy(input));
// 获取当前 key 对应的 集合
Collection<RowData> inputs = buffer.get(sortKey);
// update data state
// copy a new collection to avoid mutating state values, see CopyOnWriteStateMap,
// otherwise, the result might be corrupt.
// don't need to perform a deep copy, because RowData elements will not be updated
// 将 当前 key 的数据放到 状态中
dataState.put(sortKey, new ArrayList<>(inputs));
if (outputRankNumber || hasOffset()) {
// 要输出 rank number 或 指定了 rownum > n
// the without-number-algorithm can't handle topN with offset,
// so use the with-number-algorithm to handle offset
processElementWithRowNumber(sortKey, input, out);
} else {
// 不输出 rank number
processElementWithoutRowNumber(input, out);
}
}
}
// 初始化状态 topn heap 状态 (就是 buffer, 异常恢复的时候会将状态中的数据写到 buffer 中)
private void initHeapStates() throws Exception {
requestCount += 1;
// 获取 key
RowData currentKey = (RowData) keyContext.getCurrentKey();
// 获取 key 对应的 buffer
buffer = kvSortedMap.get(currentKey);
if (buffer == null) {
// 创建 TopNBuffer,指定 排序的 comparator 和 存元素的 ArrayList
buffer = new TopNBuffer(sortKeyComparator, ArrayList::new);
// 将 buffer 放入 LRUMap 中, 默认存放 1000 个 key
kvSortedMap.put(currentKey, buffer);
// restore buffer
// 将 dataState 中的数据到 buffer中(失败恢复的时候, 将状态中的数据,放到 buffer 里, buffer 是 heap 的,失败的时候就丢失了)
Iterator<Map.Entry<RowData, List<RowData>>> iter = dataState.iterator();
if (iter != null) {
while (iter.hasNext()) {
Map.Entry<RowData, List<RowData>> entry = iter.next();
RowData sortKey = entry.getKey();
List<RowData> values = entry.getValue();
// the order is preserved
buffer.putAll(sortKey, values);
}
}
} else {
hitCount += 1;
}
}
// 处理输出到 rownum 的
private void processElementWithRowNumber(RowData sortKey, RowData input, Collector<RowData> out) throws Exception {
// 当前 buff 的迭代器
Iterator<Map.Entry<RowData, Collection<RowData>>> iterator = buffer.entrySet().iterator();
long currentRank = 0L;
boolean findsSortKey = false;
RowData currentRow = null;
// 由于 buffer 的数据本来是排序的,所以从 0 开始读 rank end 个数据,就是排序的 top n
// 当前输入数据是 currentRow
// 将 buffer 的第一个数据设为 prevRow ,输出更新 prevRow, 输出 currentRow
// 将 buffer 的第二个数据设为 currentRow, 第一个设为 prevRow ,输出更新 prevRow, 输出 currentRow
// 依次处理下去
while (iterator.hasNext() && isInRankEnd(currentRank)) {
Map.Entry<RowData, Collection<RowData>> entry = iterator.next();
Collection<RowData> records = entry.getValue();
// meet its own sort key
if (!findsSortKey && entry.getKey().equals(sortKey)) {
currentRank += records.size();
currentRow = input;
findsSortKey = true;
} else if (findsSortKey) {
Iterator<RowData> recordsIter = records.iterator();
while (recordsIter.hasNext() && isInRankEnd(currentRank)) {
RowData prevRow = recordsIter.next();
// 输出更新之前的 currentRand 的数据
collectUpdateBefore(out, prevRow, currentRank);
// 输出当前数据 rownum = currentRand
collectUpdateAfter(out, currentRow, currentRank);
currentRow = prevRow;
currentRank += 1;
}
} else {
currentRank += records.size();
}
}
// 如果 buffer 数据是空的,输出当前数据做为 currentRank(即 0)
if (isInRankEnd(currentRank)) {
// there is no enough elements in Top-N, emit INSERT message for the new record.
collectInsert(out, currentRow, currentRank);
}
// remove the records associated to the sort key which is out of topN
// 继续遍历,将 buffer 中超过 rank end 的数据删掉 , 将 dataState 中多的数据删掉
List<RowData> toDeleteSortKeys = new ArrayList<>();
while (iterator.hasNext()) {
Map.Entry<RowData, Collection<RowData>> entry = iterator.next();
RowData key = entry.getKey();
dataState.remove(key);
toDeleteSortKeys.add(key);
}
for (RowData toDeleteKey : toDeleteSortKeys) {
buffer.removeAll(toDeleteKey);
}
}
// 处理 不带 row number 的
// 如果 buffer 中数据条数 > rank end,将最后一个元素从缓存和状态删掉(最后一个 top n 中 rownum 最大的一个)
// 如果 buffer 中最后一个 entry 集合不为空,且不等于当前输入数据,就对最后一个元素输出一条删除信息
// 输出当前数据
private void processElementWithoutRowNumber(RowData input, Collector<RowData> out) throws Exception {
// remove retired element
if (buffer.getCurrentTopNum() > rankEnd) {
Map.Entry<RowData, Collection<RowData>> lastEntry = buffer.lastEntry();
RowData lastKey = lastEntry.getKey();
Collection<RowData> lastList = lastEntry.getValue();
RowData lastElement = buffer.lastElement();
int size = lastList.size();
// remove last one
if (size <= 1) {
buffer.removeAll(lastKey);
dataState.remove(lastKey);
} else {
buffer.removeLast();
// last element has been removed from lastList, we have to copy a new collection
// for lastList to avoid mutating state values, see CopyOnWriteStateMap,
// otherwise, the result might be corrupt.
// don't need to perform a deep copy, because RowData elements will not be updated
dataState.put(lastKey, new ArrayList<>(lastList));
}
if (size == 0 || input.equals(lastElement)) {
return;
} else {
// lastElement shouldn't be null
collectDelete(out, lastElement);
}
}
// it first appears in the TopN, send INSERT message
// 只输出当前数据
collectInsert(out, input);
}
## CleanupState 清除 top n 的状态
top n 的缓存数据是存放在 MapState 中的,如果一个 key 超过 maxRetentionTime 没有数据,会清理当前状态,top n 就重新计算
minRetentionTime 就是配置的参数 “table.exec.state.ttl” 的值, maxRetentionTime 是 minRetentionTime * 3 / 2 , 默认值 minRetentionTime=10h
default void registerProcessingCleanupTimer(
ValueState<Long> cleanupTimeState,
long currentTime,
long minRetentionTime,
long maxRetentionTime,
TimerService timerService) throws Exception {
// last registered timer
Long curCleanupTime = cleanupTimeState.value();
// check if a cleanup timer is registered and
// that the current cleanup timer won't delete state we need to keep
// 当前清理时间状态为空 或者 当前时间 + 状态最小保留时间 > 当前清理时间是,注册新的清理时间状态
if (curCleanupTime == null || (currentTime + minRetentionTime) > curCleanupTime) {
// we need to register a new (later) timer
long cleanupTime = currentTime + maxRetentionTime;
// register timer and remember clean-up time
timerService.registerProcessingTimeTimer(cleanupTime);
// delete expired timer,删除过期的 timer,持续有数的 key ,状态永远不会清理,必须要超过 maxRetentionTime 无数据,才会清理过期状态
// 类似于: 清理最近 maxRetentionTime 时间没有使用的状态
if (curCleanupTime != null) {
timerService.deleteProcessingTimeTimer(curCleanupTime);
}
cleanupTimeState.update(cleanupTime);
}
}
## kafka sink
在 sink 到 upsert kafka 时,会基于输出数据的 RowKind (INSERT, UPSATE_BEFORE,UPDATE_AFTER, DELETE) 判断, DELETE 和 UPDATE_BEFORE 消息会直接置空
null
{"user_id":"user_id_8160","item_id":"item_id_1","category_id":"category_id_1","behavior":1,"sales":15.0,"sort_col":45,"ts":"2021-03-19 17:15:25"}
null
{"user_id":"user_id_8161","item_id":"item_id_1","category_id":"category_id_1","behavior":1,"sales":45.0,"sort_col":15,"ts":"2021-03-19 17:15:26"}
null
{"user_id":"user_id_8162","item_id":"item_id_1","category_id":"category_id_1","behavior":1,"sales":5.0,"sort_col":25,"ts":"2021-03-19 17:15:27"}
null
{"user_id":"user_id_8163","item_id":"item_id_1","category_id":"category_id_1","behavior":1,"sales":25.0,"sort_col":35,"ts":"2021-03-19 17:15:28"}
注: 之前以为是个bug,没想到是这样设计的(为什么不直接屏蔽呢)
DynamicKafkaSerializationSchema.java
@Override
public ProducerRecord<byte[], byte[]> serialize(RowData consumedRow, @Nullable Long timestamp) {
// shortcut in case no input projection is required
if (keySerialization == null && !hasMetadata) {
final byte[] valueSerialized = valueSerialization.serialize(consumedRow);
return new ProducerRecord<>(
topic,
extractPartition(consumedRow, null, valueSerialized),
null,
valueSerialized);
}
final byte[] keySerialized;
if (keySerialization == null) {
keySerialized = null;
} else {
final RowData keyRow = createProjectedRow(consumedRow, RowKind.INSERT, keyFieldGetters);
keySerialized = keySerialization.serialize(keyRow);
}
final byte[] valueSerialized;
final RowKind kind = consumedRow.getRowKind();
final RowData valueRow = createProjectedRow(consumedRow, kind, valueFieldGetters);
// upsert kafka 不能修改已发送的数据,所以 DELETE 和 UPDATE_BEFORE 消息会置 null,其他消息都改成 INSERT 的
if (upsertMode) {
if (kind == RowKind.DELETE || kind == RowKind.UPDATE_BEFORE) {
// transform the message as the tombstone message
valueSerialized = null;
} else {
// make the message to be INSERT to be compliant with the INSERT-ONLY format
valueRow.setRowKind(RowKind.INSERT);
valueSerialized = valueSerialization.serialize(valueRow);
}
} else {
valueSerialized = valueSerialization.serialize(valueRow);
}
return new ProducerRecord<>(
topic,
extractPartition(consumedRow, keySerialized, valueSerialized),
readMetadata(consumedRow, KafkaDynamicSink.WritableMetadata.TIMESTAMP),
keySerialized,
valueSerialized,
readMetadata(consumedRow, KafkaDynamicSink.WritableMetadata.HEADERS));
}
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号