

本文基于 flink 1.12.0
之前尝试了一下 flink sql 的 去重和Top n 功能,只是简单的看了下官网,然后用 sql 实现了功能,但是还有些疑问没有解决。比如:不使用 mini-batch 模式,去重的结果很单一,降序就只输出第一条数据(升序就一直输出最后一条)
为了解决这些疑问,特意研究了下去重部分的源码类结构图如下:
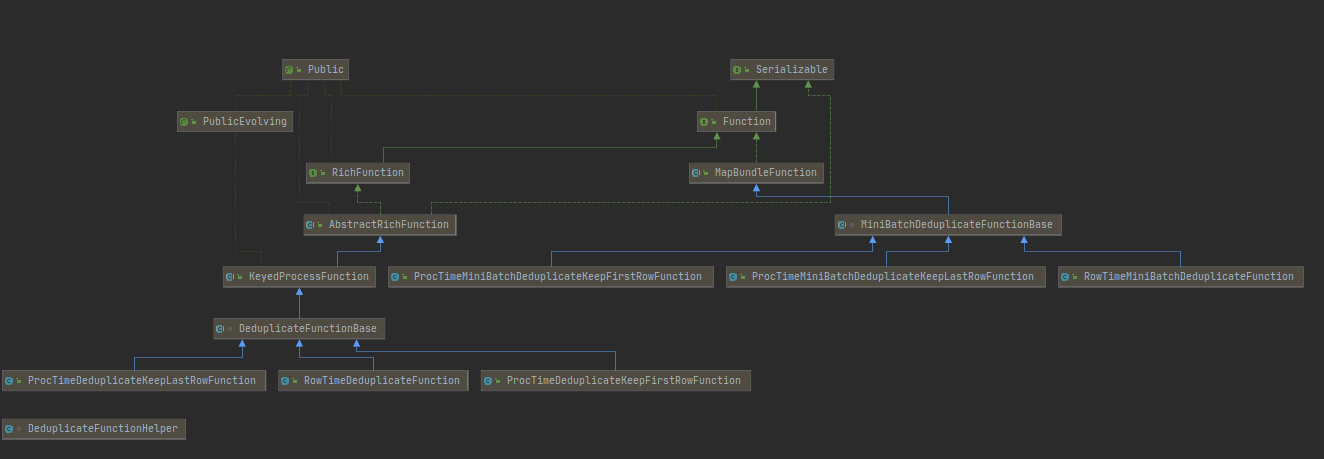
去重基类
DeduplicateFunctionBase 定义了去重的状态,由于是去重,所以只需要一个 ValueState 存储一个 Row 的数据就可以了(不管是处理时间还是事件时间,数据上都有)
// state stores previous message under the key. 基于key 的去重状态 protected ValueState<T> state; public DeduplicateFunctionBase( TypeInformation<T> typeInfo, TypeSerializer<OUT> serializer, long stateRetentionTime) { this.typeInfo = typeInfo; // 状态保留时间,决定去重的数据的作用范围 this.stateRetentionTime = stateRetentionTime; this.serializer = serializer; } @Override public void open(Configuration configure) throws Exception { super.open(configure); ValueStateDescriptor<T> stateDesc = new ValueStateDescriptor<>("deduplicate-state", typeInfo); // 设置去重状态的 ttl(这个很重要) StateTtlConfig ttlConfig = createTtlConfig(stateRetentionTime); // 如果 ttl 是开启的 if (ttlConfig.isEnabled()) { stateDesc.enableTimeToLive(ttlConfig); } // 创建去重状态 state = getRuntimeContext().getState(stateDesc); }
处理时间的 First Row
ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY process_time asc) AS rownum
即取基于处理时间的第一条数据
处理类为:ProcTimeDeduplicateKeepFirstRowFunction
处理时间的逻辑判断基于处理时间特性,后一条一定比前一条大这个逻辑,直接判断去重 state.value 是否为空,为空则表示是第一条数据,输出;不为空则前面有数据,不是第一条,不输出
public class ProcTimeDeduplicateKeepFirstRowFunction extends DeduplicateFunctionBase<Boolean, RowData, RowData, RowData> { private static final long serialVersionUID = 5865777137707602549L; // state stores a boolean flag to indicate whether key appears before. public ProcTimeDeduplicateKeepFirstRowFunction(long stateRetentionTime) { super(Types.BOOLEAN, null, stateRetentionTime); } @Override public void processElement(RowData input, Context ctx, Collector<RowData> out) throws Exception { // 调用处理时间的判断方法: DeduplicateFunctionHelper.processFirstRowOnProcTime processFirstRowOnProcTime(input, state, out); } }
DeduplicateFunctionHelper.processFirstRowOnProcTime
static void processFirstRowOnProcTime( RowData currentRow, ValueState<Boolean> state, Collector<RowData> out) throws Exception { // 检查当前行是 insert only 的,不然抱错 checkInsertOnly(currentRow); // ignore record if it is not first row // 状态不为为空,说明不是处理时间的第一条,不输出,返回 if (state.value() != null) { return; } // 第一条添加状态 state.update(true); // emit the first row which is INSERT message // 输出第一条数据 out.collect(currentRow); }
处理时间的 Last Row
ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY process_time desc) AS rownum
即取基于处理时间的最后一条数据
处理时间的逻辑基于处理时间特性,后一条一定比前一条大这个逻辑,直接判断去重 state.value 是否为空,为空则表示是第一条数据,直接输出,不为空则前面有数据,判断是否更新上一条数据,并输出当前数据;
处理类为:ProcTimeDeduplicateKeepFirstRowFunction, Last row 有点不同的是,如果接收的 cdc 源,是可以支持删除前一条数据的(这里不讨论)
public class ProcTimeDeduplicateKeepLastRowFunction extends DeduplicateFunctionBase<RowData, RowData, RowData, RowData> { private static final long serialVersionUID = -291348892087180350L; private final boolean generateUpdateBefore; private final boolean generateInsert; private final boolean inputIsInsertOnly; public ProcTimeDeduplicateKeepLastRowFunction( InternalTypeInfo<RowData> typeInfo, long stateRetentionTime, boolean generateUpdateBefore, boolean generateInsert, boolean inputInsertOnly) { super(typeInfo, null, stateRetentionTime); this.generateUpdateBefore = generateUpdateBefore; this.generateInsert = generateInsert; // StreamExecChangelogNormalize 处理的时候会设置为 false,StreamExecDeduplicate 设置为 true this.inputIsInsertOnly = inputInsertOnly; } @Override public void processElement(RowData input, Context ctx, Collector<RowData> out) throws Exception { // 判断是否是 insert only 的 if (inputIsInsertOnly) { // 只 insert 的 DeduplicateFunctionHelper processLastRowOnProcTime(input, generateUpdateBefore, generateInsert, state, out); } else { // changlog 会发出删除命令,删除前一条数据 DeduplicateFunctionHelper processLastRowOnChangelog(input, generateUpdateBefore, state, out); } } }
DeduplicateFunctionHelper.processLastRowOnProcTime
/** * Processes element to deduplicate on keys with process time semantic, sends current element as last row, * retracts previous element if needed. * * @param currentRow latest row received by deduplicate function * @param generateUpdateBefore whether need to send UPDATE_BEFORE message for updates * @param state state of function, null if generateUpdateBefore is false * @param out underlying collector */ static void processLastRowOnProcTime( RowData currentRow, boolean generateUpdateBefore, boolean generateInsert, ValueState<RowData> state, Collector<RowData> out) throws Exception { // 检测为只写的 checkInsertOnly(currentRow); // 是否更新上一条数据,是否写数据 if (generateUpdateBefore || generateInsert) { // use state to keep the previous row content if we need to generate UPDATE_BEFORE // or use to distinguish the first row, if we need to generate INSERT // 取去重状态数据 RowData preRow = state.value(); state.update(currentRow); // 没有上一条,直接输出当前这条 if (preRow == null) { // the first row, send INSERT message 输出第一条数据是 INSERT currentRow.setRowKind(RowKind.INSERT); out.collect(currentRow); } else { // 如果存在上一条数据,配置为更新上一条,会输出上一条数据(方便下游可以更新就的数据) if (generateUpdateBefore) { preRow.setRowKind(RowKind.UPDATE_BEFORE); out.collect(preRow); } // 再输出当前数据 currentRow.setRowKind(RowKind.UPDATE_AFTER); out.collect(currentRow); } } else { // 如果不更新上一条,不是 insert,就输出一个 更新 // always send UPDATE_AFTER if INSERT is not needed currentRow.setRowKind(RowKind.UPDATE_AFTER); out.collect(currentRow); } }
事件时间的去重
事件时间的代码和处理时间的代码不同,将取第一条和最后一条合并在了一起,用了个 boolean 值的变量 “keepLastRow” 标识
事件时间去重类
public class RowTimeDeduplicateFunction extends DeduplicateFunctionBase<RowData, RowData, RowData, RowData> { private static final long serialVersionUID = 1L; private final boolean generateUpdateBefore; private final boolean generateInsert; private final int rowtimeIndex; private final boolean keepLastRow; public RowTimeDeduplicateFunction( InternalTypeInfo<RowData> typeInfo, long minRetentionTime, int rowtimeIndex, boolean generateUpdateBefore, boolean generateInsert, boolean keepLastRow) { super(typeInfo, null, minRetentionTime); // 是否更新前一条 this.generateUpdateBefore = generateUpdateBefore; // 是否是 INSERT this.generateInsert = generateInsert; // 事件时间列的 index this.rowtimeIndex = rowtimeIndex; // 保留第一条还是最后一条 this.keepLastRow = keepLastRow; } @Override public void processElement(RowData input, Context ctx, Collector<RowData> out) throws Exception { deduplicateOnRowTime( state, input, out, generateUpdateBefore, generateInsert, rowtimeIndex, keepLastRow); } /** * Processes element to deduplicate on keys with row time semantic, sends current element if it is last * or first row, retracts previous element if needed. * * @param state state of function * @param currentRow latest row received by deduplicate function * @param out underlying collector * @param generateUpdateBefore flag to generate UPDATE_BEFORE message or not * @param generateInsert flag to gennerate INSERT message or not * @param rowtimeIndex the index of rowtime field * @param keepLastRow flag to keep last row or keep first row */ public static void deduplicateOnRowTime( ValueState<RowData> state, RowData currentRow, Collector<RowData> out, boolean generateUpdateBefore, boolean generateInsert, int rowtimeIndex, boolean keepLastRow) throws Exception { checkInsertOnly(currentRow); RowData preRow = state.value(); if (isDuplicate(preRow, currentRow, rowtimeIndex, keepLastRow)) { // 不是重复的,判断更新重复数据 updateDeduplicateResult( generateUpdateBefore, generateInsert, preRow, currentRow, out); // 将当前数据写到状态中 state.update(currentRow); } } }
事件时间判断重复方法
static boolean isDuplicate(RowData preRow, RowData currentRow, int rowtimeIndex, boolean keepLastRow) { if (keepLastRow) { // 保留最后一条: 去重状态为 null, 上一条数据时间 <= 当前数据的 时间 return preRow == null || getRowtime(preRow, rowtimeIndex) <= getRowtime(currentRow, rowtimeIndex); } else { // 保留第一条: 去重状态为 null, 当前数据时间 < 上一条数据的 时间 return preRow == null || getRowtime(currentRow, rowtimeIndex) < getRowtime(preRow, rowtimeIndex); } } // 只反序列化 事件时间列 private static long getRowtime(RowData input, int rowtimeIndex) { return input.getLong(rowtimeIndex); }
DeduplicateFunctionHelper.updateDeduplicateResult
static void updateDeduplicateResult( boolean generateUpdateBefore, boolean generateInsert, RowData preRow, RowData currentRow, Collector<RowData> out) { // 更新前面的一条 或 是 INSERT if (generateUpdateBefore || generateInsert) { // 前一条数据为 null if (preRow == null) { // the first row, send INSERT message 直接输出 INSERT currentRow.setRowKind(RowKind.INSERT); out.collect(currentRow); } else { // 如果要更新上一条数据 if (generateUpdateBefore) { final RowKind preRowKind = preRow.getRowKind(); // 上一条数据的状态设为 UPDATE_BEFORE preRow.setRowKind(RowKind.UPDATE_BEFORE); out.collect(preRow); preRow.setRowKind(preRowKind); } // 输出当前数据 状态: UPDATE_AFTER currentRow.setRowKind(RowKind.UPDATE_AFTER); out.collect(currentRow); } } else { // 输出当前数据 状态: UPDATE_AFTER currentRow.setRowKind(RowKind.UPDATE_AFTER); out.collect(currentRow); } }
从代码可以清楚的看到 去重的逻辑,需要注意的是去重状态是有有 ttl 的,ttl 的默认时间是 36000 s,所以默认情况下,取第一条的情况下,在状态还没过期的情况下,只会在启动的时候输出一条数据(这时候会给人一种是基于全局去重的错觉)。
调整状态的时间可以设置参数: table.exec.state.ttl=60s 参见代码: DeduplicateFunctionBase 成员变量 stateRetentionTime
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号