
在大数据的处理过程中会出现很多汇总类指标的计算,比如计算当日的每个类目下的用户的订单信息,就需要按类目分组,对用户做去重。Flink sql 提供了 “去重” 功能,可以在流模式的任务中做去重操作。
官网文档 去重
** 注意 仅 Blink planner 支持去重。
去重是指对在列的集合内重复的行进行删除,只保留第一行或最后一行数据。 在某些情况下,上游的 ETL 作业不能实现精确一次的端到端,这将可能导致在故障恢复 时,sink 中有重复的记录。 由于重复的记录将影响下游分析作业的正确性(例如,SUM、COUNT), 所以在进一步分析之前需要进行数据去重。
与 Top-N 查询相似,Flink 使用 ROW_NUMBER() 去除重复的记录。理论上来说,去重是一个特殊的 Top-N 查询,其中 N 是 1 ,记录则是以处理时间或事件事件进行排序的。
以下代码展示了去重语句的语法:
SELECT [column_list] FROM ( SELECT [column_list], ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]] ORDER BY time_attr [asc|desc]) AS rownum FROM table_name) WHERE rownum = 1
参数说明:
ROW_NUMBER(): 从第一行开始,依次为每一行分配一个唯一且连续的号码。
PARTITION BY col1[, col2...]: 指定分区的列,例如去重的键。
ORDER BY time_attr [asc|desc]: 指定排序的列。所指定的列必须为 时间属性, 目前 Flink 支持 处理时间属性 和 事件时间属性 。升序( ASC )排列指只保留第一行,而降序排列( DESC )则指保留最后一行。
WHERE rownum = 1: Flink 需要 rownum = 1 以确定该查询是否为去重查询。
以下的例子描述了如何指定 SQL 查询以在一个流计算表中进行去重操作。
val env = StreamExecutionEnvironment.getExecutionEnvironment val tableEnv = TableEnvironment.getTableEnvironment(env) // 从外部数据源读取 DataStream val ds: DataStream[(String, String, String, Int)] = env.addSource(...) // 注册名为 “Orders” 的 DataStream tableEnv.createTemporaryView("Orders", ds, $"order_id", $"user", $"product", $"number", $"proctime".proctime) // 由于不应该出现两个订单有同一个order_id,所以根据 order_id 去除重复的行,并保留第一行 val result1 = tableEnv.sqlQuery( """ |SELECT order_id, user, product, number |FROM ( | SELECT *, | ROW_NUMBER() OVER (PARTITION BY order_id ORDER BY proctime DESC) as row_num | FROM Orders) |WHERE row_num = 1 """.stripMargin)
** 注以上内容来自官网
demo
默认模式和 mini-batch 模式下都支持去重,但是默认模型是基于全局的,mini-batch 是基于 mini-batch 配置的
默认模式 下,去重是基于全局的,要么只输出第一条数据( asc 升序,第一条数据 rownum=1),要么全部输出(desc 降序,依次来的每条数据 rownum 都是 1)
mini-batch 模式下,数据是基于批次生效
去重 sql 如下:
--- 去重查询 -- kafka source CREATE TABLE user_log ( user_id VARCHAR ,item_id VARCHAR ,category_id VARCHAR ,behavior INT ,ts TIMESTAMP(3) ,process_time as proctime() , WATERMARK FOR ts AS ts ) WITH ( 'connector' = 'kafka' ,'topic' = 'user_behavior' ,'properties.bootstrap.servers' = 'localhost:9092' ,'properties.group.id' = 'user_log' ,'scan.startup.mode' = 'group-offsets' ,'format' = 'json' ); ---sink table CREATE TABLE user_log_sink ( user_id VARCHAR ,item_id VARCHAR ,category_id VARCHAR ,behavior INT ,ts TIMESTAMP(3) ,num BIGINT ,primary key (user_id) not enforced ) WITH ( 'connector' = 'upsert-kafka' ,'topic' = 'user_behavior_sink' ,'properties.bootstrap.servers' = 'localhost:9092' ,'properties.group.id' = 'user_log' ,'key.format' = 'json' ,'key.json.ignore-parse-errors' = 'true' ,'value.format' = 'json' ,'value.json.fail-on-missing-field' = 'false' ,'value.fields-include' = 'ALL' ); -- insert insert into user_log_sink(user_id, item_id, category_id,behavior,ts,num) SELECT user_id, item_id, category_id,behavior,ts,rownum FROM ( SELECT user_id, item_id, category_id,behavior,ts, ROW_NUMBER() OVER (PARTITION BY category_id ORDER BY process_time desc) AS rownum -- desc use the latest one, FROM user_log) WHERE rownum=1-- 只能使用 rownum=1,如果写 rownum=2(或<10),每个分区只会输出一条数据(小于是多条)rownum=2的,看起来基于全局去重了
mini-batch 配置参数
configuration.setString("table.exec.mini-batch.enabled", "true");
configuration.setString("table.exec.mini-batch.allow-latency", "5 s");
configuration.setString("table.exec.mini-batch.size", "5000");
去重是基于参数 "table.exec.mini-batch.allow-latency" 和 "table.exec.mini-batch.size" 生效,满足一个就算一个“批次”,每个批次每个 category_id 只输出一次 (可以控制数据源的数据,只输出一个用户一个 category_id,测试这两个参数)
rownum=1 的问题
看了下源码,去重部分结构是这样的
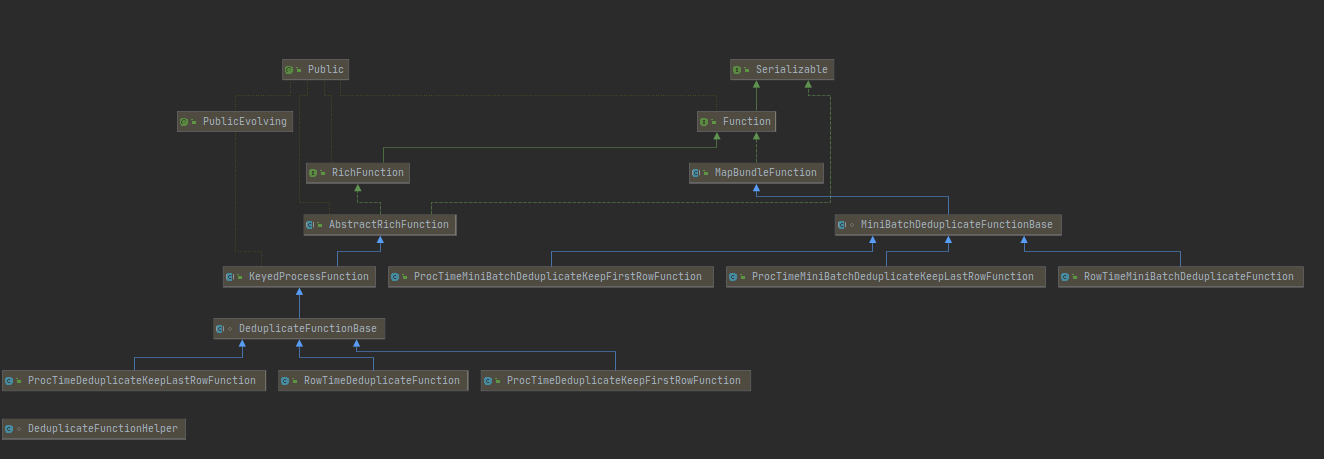
大致分成两部分,分别以类: DeduplicateFunctionBase 和 MiniBatchDeduplicateFunctionBase 为基类,分别实现了 ProcTimeDeduplicateKeepFirstRowFunction 、ProcTimeDeduplicateKeepLastRowFunction 、RowTimeDeduplicateFunction 和 ProcTimeMiniBatchDeduplicateKeepFirstRowFunction、ProcTimeMiniBatchDeduplicateKeepLastRowFunction、RowTimeMiniBatchDeduplicateFunction 两个分支的数据
简单的区别就是: DeduplicateFunctionBase 接收的数据是单条的,mini-batch 的接收的数据都是集合
RowTimeDeduplicateFunction
@Override public void processElement(RowData input, Context ctx, Collector<RowData> out) throws Exception { deduplicateOnRowTime( state, input, out, generateUpdateBefore, generateInsert, rowtimeIndex, keepLastRow); }
RowTimeMiniBatchDeduplicateFunction
@Override public void finishBundle(Map<RowData, List<RowData>> buffer, Collector<RowData> out) throws Exception { for (Map.Entry<RowData, List<RowData>> entry : buffer.entrySet()) { RowData currentKey = entry.getKey(); List<RowData> bufferedRows = entry.getValue(); ctx.setCurrentKey(currentKey); miniBatchDeduplicateOnRowTime( state, bufferedRows, out, generateUpdateBefore, generateInsert, rowtimeIndex, keepLastRow); } }
所以就不需要问为什么 rownum 只能等于 1 了。
新的问题又来了: 为什么没看 mini-batch 的时候没有输出没有去重呢?
答: PARTITION BY category_id ORDER BY process_time desc 在 desc 的情况下,每次进来的数据 process_time 都是大于之前的数据,新数据的 rownum=1,所以 每条数据都输出了
完整代码参见:https://github.com/springMoon/sqlSubmit
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号