

在这里,我很荣幸的宣布,开源项目 flink sqlSubmit 1.0 发布了。👏👏👏
乘着这几天假,在家把很早就该完成的事情做了点,第一个就是把sqlSubmit 稍微修改了下,勉强发布1.0版本。
地址:https://github.com/springMoon/sqlSubmit/releases/tag/sqlSubmit-1.0
功能
sqlSubmit 目前是基于 flink 1.10.1 开发,目前只测试过如下功能(就是简单的跑了下)
- kafka Source/Sink
- Kafak Upsert Sink
项目中resources/sql/connector 中 kafkaToKafka.sql 和 kafkaUpserDemo.sql
由于环境比较恶劣(只有一台老mac电脑),只装了kafka,所以这次就只有 kafka 相关的功能。
HiveCatalog 也因为没有 hive 暂时放弃。
等我在电脑上捣腾上mysql/hbase/elasticsearch 就加上对应的sql demo 文件。
KafkaUpsertSink
kafka source/sink 没什么好说的,就简单介绍下 KafkaUpsertSink,目前的 flink 版本中,kafka Sink 类: KafkaTableSink 继承自 AppendStreamTableSink,所以 kafka 表作为 sink upsert-mode 只支持 append,但是 sql 中使用了 group by 后,输出的流就变成 UpsertStream ,然后不能执行。
对一般kafka sink 表,执行如下 sql
-- kafka sink CREATE TABLE user_log_sink ( user_id VARCHAR ,max_tx BIGINT ) WITH ( 'connector.type' = 'kafka' ,'connector.version' = 'universal' ,'connector.topic' = 'user_behavior_sink' -- required: topic name from which the table is read ,'connector.properties.zookeeper.connect' = 'localhost:2181' -- required: specify the ZooKeeper connection string ,'connector.properties.bootstrap.servers' = 'localhost:9092' -- required: specify the Kafka server connection string ,'connector.properties.group.id' = 'user_log' -- optional: required in Kafka consumer, specify consumer group ,'connector.startup-mode' = 'group-offsets' -- optional: valid modes are "earliest-offset", "latest-offset", "group-offsets", "specific-offsets" ,'connector.sink-partitioner' = 'fixed' --optional fixed 每个 flink 分区数据只发到 一个 kafka 分区 -- round-robin flink 分区轮询分配到 kafka 分区 -- custom 自定义分区策略 --,'connector.sink-partitioner-class' = 'org.mycompany.MyPartitioner' -- 自定义分区类 ,'format.type' = 'json' -- required: 'csv', 'json' and 'avro'. ); -- insert insert into user_log_sink select user_id, count(user_id) from user_log group by user_id;
会报如下错误:
org.apache.flink.table.api.TableException: AppendStreamTableSink requires that Table has only insert changes.
这种时候,很容易就想到自定义一个KafkaUsertSink,实现 UpsertStreamTableSink。(站在巨人的肩膀上)只需要参照Flink 中的KafkaTableSink 一套即可。
KafkaTableSink
KafkaTableSinkBase
KafkaTableSourceSinkFactory
KafkaTableSourceSinkFactoryBase
KafkaValidator
将 KafkaTableSinkBase 实现的接口改为 UpsertStreamTableSink ,然后实现对应的方法即可。
我把KafkaTableSinkBase 和 KafkaTableSink 合并了一下,代码目录 com.rookie.submit.connector.kafka
KafkaUpsertTableSink
KafkaUpsertTableSinkFactory
KafkaUpsertTableSinkFactoryBase
UpsertKafkaValidator
KafkaUpserTableSink 实现 UpsertStreamTableSink
UpsertKafkaValidator 则是修改对应的 table properties,将 'connector.type' = 'kafka' , 改为 'connector.type' = 'upsertKafka'
最重要的一段逻辑是将 DataStream<Tuple2<Boolean, Row>> 转为 DataStream<Row> ,将 UpsertStream 的 标示列去掉(根据自己实际的业务需要修改)
@Override public DataStreamSink<?> consumeDataStream(DataStream<Tuple2<Boolean, Row>> dataStream) { final SinkFunction<Row> kafkaProducer = createKafkaProducer( topic, properties, serializationSchema, partitioner); // todo cast DataStream<Tuple2<Boolean, Row>> to DataStream<Row> return dataStream .flatMap(new FlatMapFunction<Tuple2<Boolean, Row>, Row>() { @Override public void flatMap(Tuple2<Boolean, Row> element, Collector<Row> out) throws Exception { // upsertStream include insert/update/delete change, true is upsert, false is delete if (element.f0) { out.collect(element.f1); } else { System.out.println("KafkaUpsertTableSinkBase : retract stream f0 will be false"); } } }) .addSink(kafkaProducer) .setParallelism(dataStream.getParallelism()) .name(TableConnectorUtils.generateRuntimeName(this.getClass(), getFieldNames())); }
测试时,执行 com.rookie.submit.main.SqlSubmit ,需要传入参数: --sql sql/connector/kafkaUpsertDemo.sql (--sql 参数指定要执行的sql 脚本路径)
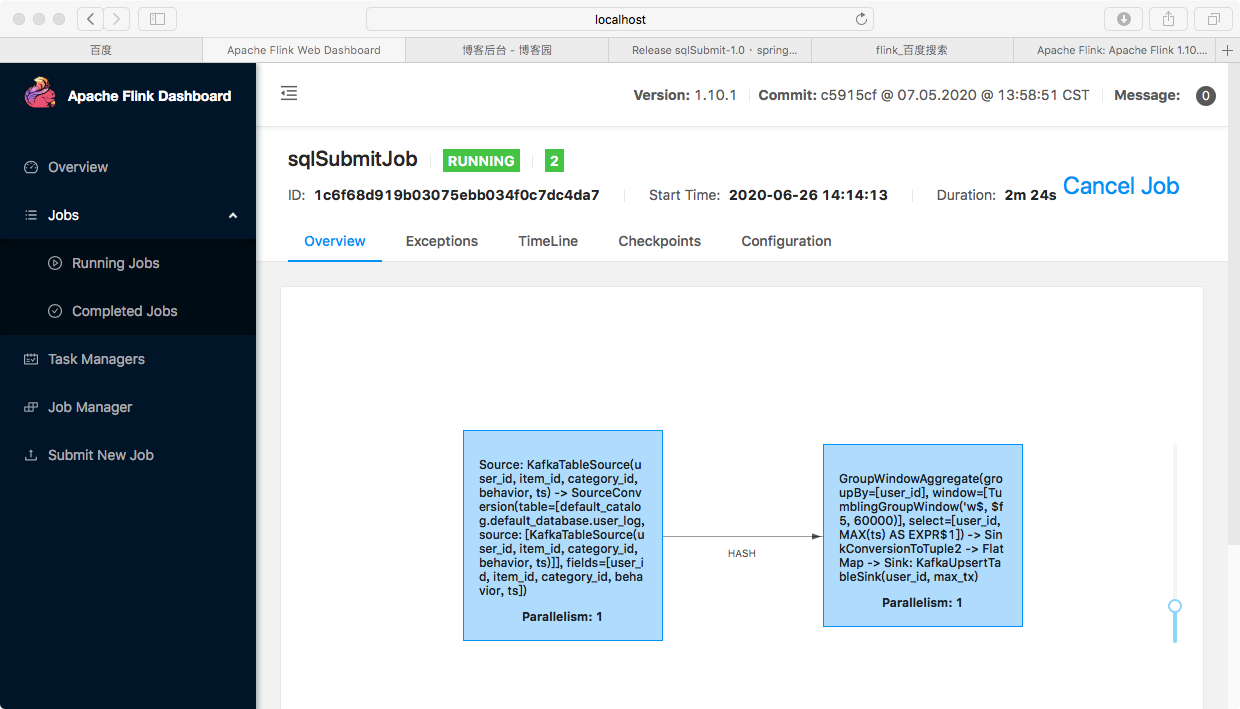
执行结果如下:
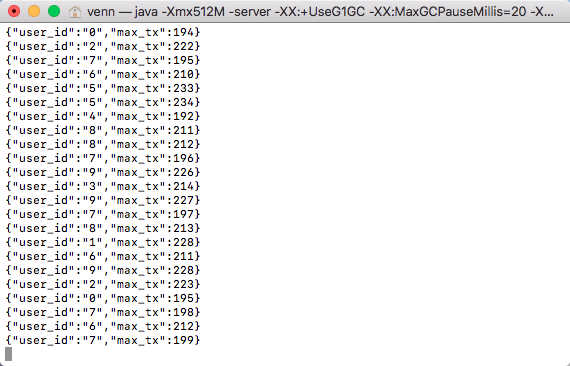
具体请移步 github 查看项目代码。
注:本人水平有限,开发的代码也比较鸡肋,建议使用 flink on zeppelin,flink 社区大力支持中。
flink 1.10.1 web UI 也优化了很多,比之前好看多了

欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号