

Flink SQL ElasticSearch connector 仅支持流模式,也仅支持做 sink :
Sink: Streaming Append Mode Sink: Streaming Upsert Mode Format: JSON-only
注:Flink 提供的只有这些,自己也可以实现
ElastincSearch connector 可以在upsert 模式下运行,以使用查询定义的 key 与外部系统交换UPSERT / DELETE消息。
对于 append-only 查询,connector 还可以在 append 模式下操作,以仅与外部系统交换INSERT消息。 如果查询未定义键,则Elasticsearch自动生成一个键。
DDL 定义如下:
CREATE TABLE MyUserTable ( ... ) WITH ( 'connector.type' = 'elasticsearch', -- required: specify this table type is elasticsearch 'connector.version' = '6', -- required: valid connector versions are "6" 'connector.hosts' = 'http://host_name:9092;http://host_name:9093', -- required: one or more Elasticsearch hosts to connect to 'connector.index' = 'MyUsers', -- required: Elasticsearch index 'connector.document-type' = 'user', -- required: Elasticsearch document type 'update-mode' = 'append', -- optional: update mode when used as table sink. 'connector.key-delimiter' = '$', -- optional: delimiter for composite keys ("_" by default) -- e.g., "$" would result in IDs "KEY1$KEY2$KEY3" 'connector.key-null-literal' = 'n/a', -- optional: representation for null fields in keys ("null" by default) 'connector.failure-handler' = '...', -- optional: failure handling strategy in case a request to -- Elasticsearch fails ("fail" by default). -- valid strategies are -- "fail" (throws an exception if a request fails and -- thus causes a job failure), -- "ignore" (ignores failures and drops the request), -- "retry-rejected" (re-adds requests that have failed due -- to queue capacity saturation), -- or "custom" for failure handling with a -- ActionRequestFailureHandler subclass -- optional: configure how to buffer elements before sending them in bulk to the cluster for efficiency 'connector.flush-on-checkpoint' = 'true', -- optional: disables flushing on checkpoint (see notes below!) -- ("true" by default) 'connector.bulk-flush.max-actions' = '42', -- optional: maximum number of actions to buffer -- for each bulk request 'connector.bulk-flush.max-size' = '42 mb', -- optional: maximum size of buffered actions in bytes -- per bulk request -- (only MB granularity is supported) 'connector.bulk-flush.interval' = '60000', -- optional: bulk flush interval (in milliseconds) 'connector.bulk-flush.back-off.type' = '...', -- optional: backoff strategy ("disabled" by default) -- valid strategies are "disabled", "constant", -- or "exponential" 'connector.bulk-flush.back-off.max-retries' = '3', -- optional: maximum number of retries 'connector.bulk-flush.back-off.delay' = '30000', -- optional: delay between each backoff attempt -- (in milliseconds) -- optional: connection properties to be used during REST communication to Elasticsearch 'connector.connection-max-retry-timeout' = '3', -- optional: maximum timeout (in milliseconds) -- between retries 'connector.connection-path-prefix' = '/v1' -- optional: prefix string to be added to every -- REST communication 'format.type' = '...', -- required: Elasticsearch connector requires to specify a format, ... -- currently only 'json' format is supported. -- Please refer to Table Formats section for more details. )
Flink自动从查询中提取有效 key。 例如,查询SELECT a,b,c FROM t GROUP BY a,b定义了字段a和b的组合键。 Elasticsearch connector 通过使用关键字定界符按查询中定义的顺序串联所有关键字字段,为每一行生成一个文档ID。 可以定义键字段的空文字的自定义表示形式。
官网提供的DDL 定义,至少我已经发现添加如下参数,会报找不到合适的 TableSinkFactory
'connector.bulk-flush.back-off.max-retries' = '3',
'connector.bulk-flush.back-off.delay' = '10000'
报错如下:
Exception in thread "main" org.apache.flink.table.api.NoMatchingTableFactoryException: Could not find a suitable table factory for 'org.apache.flink.table.factories.TableSinkFactory' in the classpath. Reason: No factory supports all properties. The matching candidates: org.apache.flink.streaming.connectors.elasticsearch7.Elasticsearch7UpsertTableSinkFactory Unsupported property keys: connector.bulk-flush.back-off.max-retries connector.bulk-flush.back-off.delay
必须说下这个报错了,使用 SQL 经常 会遇到这个报错,我遇到的大概有两种原因:
1、相应的jar 包没有添加
2、with 中的配置有错
flink sql 会根据dll 的schame 和 classpath 中的内容, 自动推断 需要使用 的 TableSinkFactory
如果ddl 不对,或者 classpath 中没有对应的 TableSinkFactory 都会报 这个错
好了,看下实例:
添加对应依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
SQL 如下:
-- 读 json,写csv ---sourceTable CREATE TABLE user_log( user_id VARCHAR, item_id VARCHAR, category_id VARCHAR, behavior VARCHAR, ts TIMESTAMP(3) ) WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior', 'connector.properties.zookeeper.connect' = 'venn:2181', 'connector.properties.bootstrap.servers' = 'venn:9092', 'connector.startup-mode' = 'earliest-offset', 'format.type' = 'json' ); ---sinkTable CREATE TABLE user_log_sink ( user_id VARCHAR, item_id VARCHAR, category_id VARCHAR, behavior VARCHAR, ts VARCHAR --ts TIMESTAMP(3) ) WITH ( 'connector.type' = 'elasticsearch', 'connector.version' = '7', 'connector.hosts' = 'http://venn:9200', 'connector.index' = 'user_behavior', 'connector.document-type' = 'user', 'connector.bulk-flush.interval' = '6000', 'connector.connection-max-retry-timeout' = '3', 'connector.bulk-flush.back-off.max-retries' = '3', 'connector.bulk-flush.back-off.delay' = '10000', --'connector.connection-path-prefix' = '/v1', 'update-mode' = 'upsert', 'format.type' = 'json' ); -- es sink is upsert, can update, use group key as es id ... 这段SQL 是乱写的。。 ---insert INSERT INTO user_log_sink --SELECT user_id, item_id, category_id, behavior, ts --FROM user_log; SELECT cast(COUNT(*) as VARCHAR ) dt, cast(COUNT(*) as VARCHAR ) AS pv, cast(COUNT(DISTINCT user_id)as VARCHAR ) AS uv, MAX(behavior), DATE_FORMAT(ts, 'yyyy-MM-dd HH:mm:s0') FROM user_log GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:mm:s0');
看下写到ES 中的数据:
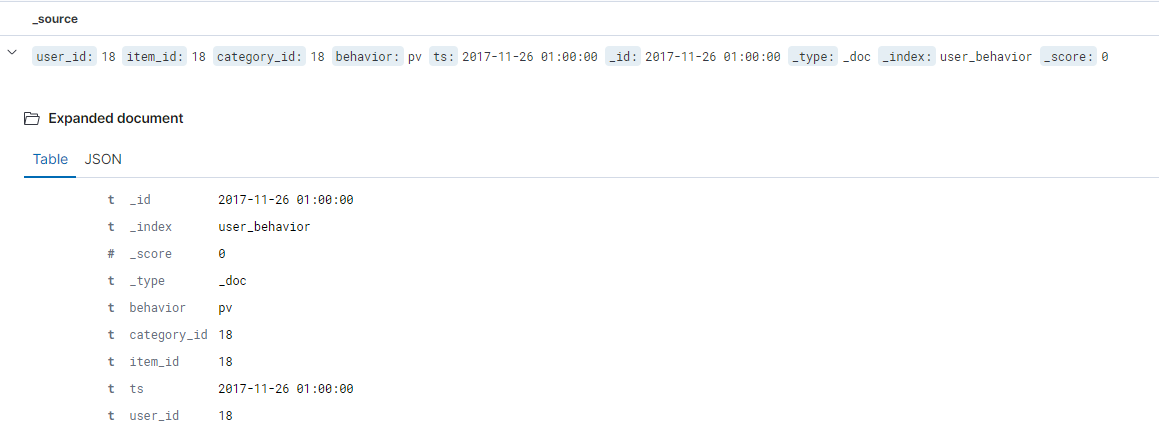
搞定
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号