
流计算这两年很火了,可能对数据的实时性要求高。现在用的hadoop框架,对流计算的支持,主要还是微批(spark),也不支持“Exactly Once”语义(可以使用外接的数据库解决),公司项目可能会用所以就下载了个Flink试试。
1. 下载解压
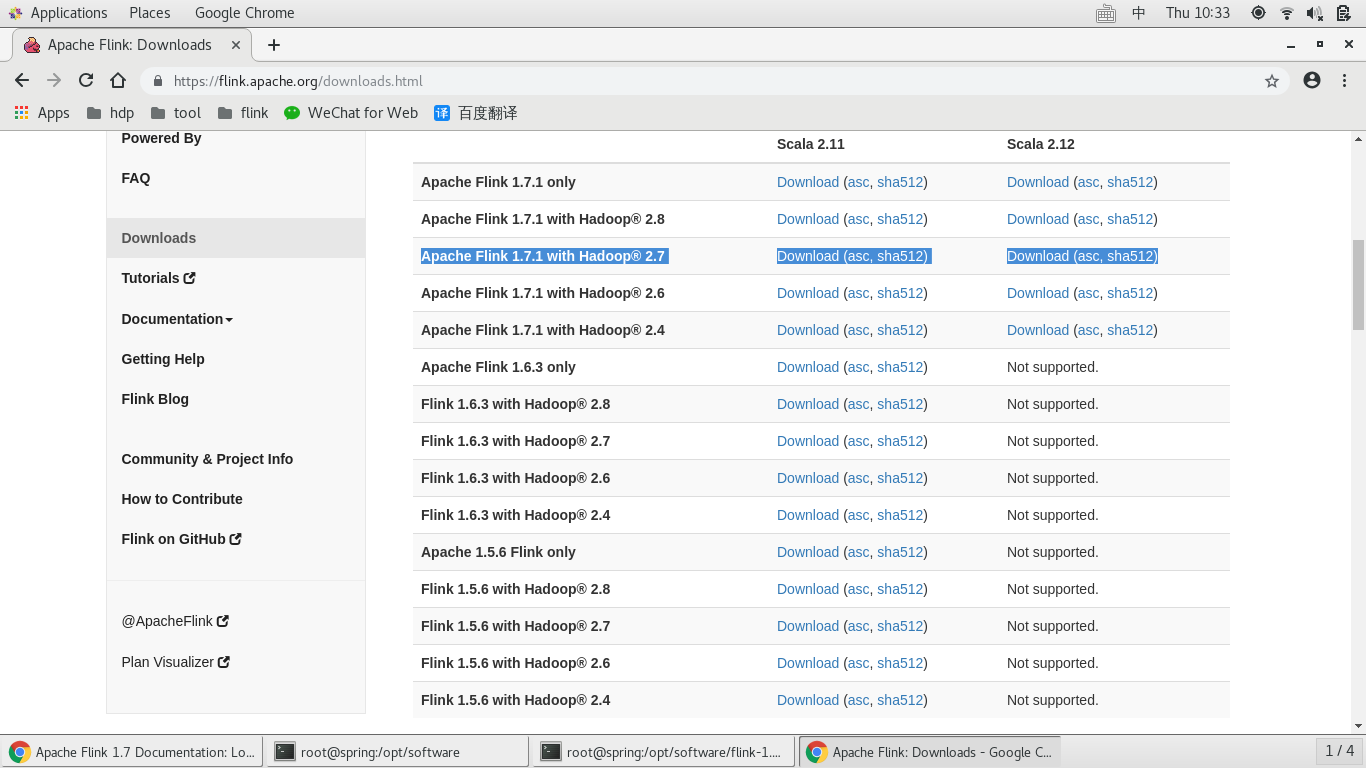
打开官网:https://flink.apache.org/, “DOWNLOAD”,下载对应 hadoop 和scala 版本。Flink以来JDK和HADOOP,提前下载。
[root@spring software]# wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.7.1/flink-1.7.1-bin-hadoop27-scala_2.12.tgz [root@spring software]# tar -zxvf flink-1.7.1-bin-hadoop27-scala_2.12.tgz [root@spring software]# ll total 454720 drwxrwxrwx 9 venn venn 141 Dec 15 09:17 flink-1.7.1 -rw-r--r-- 1 root root 284258911 Dec 16 18:30 flink-1.7.1-bin-hadoop27-scala_2.12.tgz drwxr-xr-x. 8 10 143 255 Apr 1 2016 jdk1.8 -rw-r--r--. 1 root root 181367942 Dec 28 17:54 jdk-8u91-linux-x64.tar.gz
2. 配置
官网教程: https://ci.apache.org/projects/flink/flink-docs-release-1.7/tutorials/local_setup.html
在bin/config.sh 是Flink 的配置文件,但是不需要配置,只需要有配置JAVA_HOME, HADOOP_HOME ( 或者HADOOP_CONF_DIR)
export JAVA_HOME=/opt/software/jdk1.8 export CLASSPATH=.:$JAVA_HOME/lib export PATH=$JAVA_HOME/bin:$PATH export HADOOP_HOME=/etc/hadoop export HADOOP_CONF_DIR=/etc/hadoop/conf [root@spring bin]# source /etc/profile [root@spring bin]# echo $HADOOP_CONF_DIR /etc/hadoop/conf [root@spring bin]# echo $HADOOP_HOME /etc/hadoop [root@spring bin]# echo $JAVA_HOME /opt/software/jdk1.8
config.sh
KEY_ENV_JAVA_HOME="env.java.home" # java使用环境变量 # Check if deprecated HADOOP_HOME is set, and specify config path to HADOOP_CONF_DIR if it's empty. # 读取环境变量 HADOOP_HOME HADOOP_CONF_DIR if [ -z "$HADOOP_CONF_DIR" ]; then if [ -n "$HADOOP_HOME" ]; then # HADOOP_HOME is set. Check if its a Hadoop 1.x or 2.x HADOOP_HOME path if [ -d "$HADOOP_HOME/conf" ]; then # its a Hadoop 1.x HADOOP_CONF_DIR="$HADOOP_HOME/conf" fi if [ -d "$HADOOP_HOME/etc/hadoop" ]; then # Its Hadoop 2.2+ HADOOP_CONF_DIR="$HADOOP_HOME/etc/hadoop" fi fi fi # try and set HADOOP_CONF_DIR to some common default if it's not set if [ -z "$HADOOP_CONF_DIR" ]; then if [ -d "/etc/hadoop/conf" ]; then echo "Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set." HADOOP_CONF_DIR="/etc/hadoop/conf" fi fi
4. 流计算demo wordcount
使用nc 模拟输入流,输入数据
[root@spring log]# nc -l 9000 1 2 3 4 5 ...
启动wordcount demo
[root@spring flink-1.7.1]# ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000 Starting execution of program
nc输入继续输入数据。。。
"ctrl + C" 关闭nc,wordcount demo 随之关闭。
trewt re w ^C # kill nc [root@spring log]# # wordcount 完成 [root@spring flink-1.7.1]# ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000 Starting execution of program Program execution finished Job with JobID b1e67fe09658ebe57fac2c2f7ef11916 has finished. Job Runtime: 36016 ms
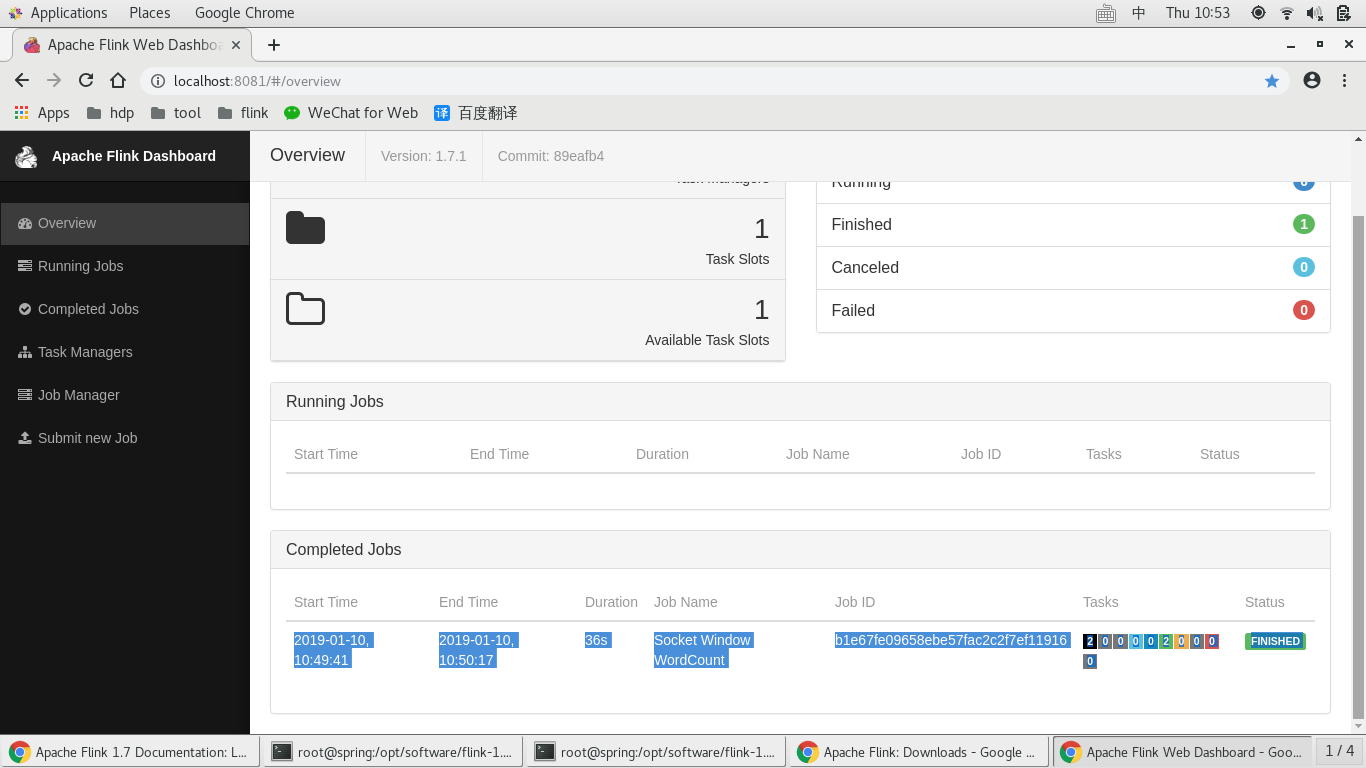
查看统计结果:
[root@spring flink-1.7.1]# more -f log/flink-root-taskexecutor-2-spring.hadoop.out # 第一次执行是 0 1 : 1 qq : 1 : 1 tyr : 1 tre : 1 o : 2 i : 2 u : 2 y : 2 t : 2 r : 3 e : 1 w : 1 q : 4 0 : 1 9 : 1 8 : 1 7 : 1 6 : 1 5 : 1 4 : 1 3 : 1 2 : 1 rew : 1 432 : 1 4321 : 1 423 : 1 trew : 1 fds : 1 4 : 5 其 : 1 rfd : 1 其q : 1 fdsgfd : 1 trewtg : 1 raq : 1 dfs : 1 eh : 1 r : 1 wyht : 1 re : 1 rds : 2 g : 4 fgrd : 1 ygtre : 1 fretg : 1 trewt : 1 erw : 1 wtg : 1 gre : 1 ds : 1 fv : 1 : 1 gfr : 1 t : 1 ghrw : 1 s : 1 gvdf : 1 d : 1 wg : 1 er : 1 wt : 1 re : 3 rewt : 1 redwg : 1
查看管理控制台

本文所有内容来自官网教程,本地执行,https://ci.apache.org/projects/flink/flink-docs-release-1.7/tutorials/local_setup.html
搞定

 浙公网安备 33010602011771号
浙公网安备 33010602011771号