1.hive 简介
1.1 hive出现的原因
FaceBook网站每天产生海量的结构化日志数据,为了对这些数据进行管理,并且因为机器学习的需求,产生了hive这门技术,并继续发展成为一个成功的Apache项目(hive是由Facebook开源用于解决海量结构化日志的数据统计)==》广泛应用原因:
- 传统数仓处理海量数据的计算处理性能不足,存储能力有限,无法处理不同类型数据
- mapreduce 编程的不便性
- HDFS的文件适合存储的是非结构化的或半结构化数据,缺少schema(字段名和数据类型等)
什么是hive
- 构建在Hadoop之上的数据仓库工具
- Hive定义了一种类SQL查询语言:HQL(类似SQL但不完全相同)
- 通常用于进行离线数据处理(采用MapReduce)
- 底层支持多种不同的执行引擎(Hive on MapReduce、Hive on Tez、Hive on Spark)
- 支持多种不同的压缩格式、存储格式以及自定义函数(压缩:GZIP、LZO、Snappy、BZIP2.. ; 存储:TextFile、SequenceFile、RCFile、ORC、Parquet ; UDF:自定义函数)
- 本质:Hive的本质是将HQL转换成MapReduce任务,完成整个数据的分析查询,减少编写MapReduce的复杂度。
hive 的作用,为什么要使用Hive 优点
- hive 提供了一个类SQL的方式,可以让我们快速而简单的利用MapReduce计算引擎(模型,框架)
- 降低了用户学习和应用程序迁移到hadoop成本,把精力关注于查询本身。
- 统一的元数据管理(可与Presto/Impala/SparkSQL等共享数据)
- 具有超大数据集的计算/存储扩展能力(依赖MR计算,HDFS存储)
hive的缺点,不能使用场景
-
如果是基于MapReduce 的计算模型,不适合流式数据即实时数据,因为存在延时,mapredue 任务启动到计算相对需要消耗较多的时间
,所以适合联机的分析处理,不适合联机事务处理,且在大规模的数据上占优势 -
基于hadoop以及HDFS设计上约束,不支持记录级别的更新,插入和删除操作,一般是通过查询生成新表,或导入到文件中
-
Hive自动生成的MapReduce作业,通常情况下不够智能化,Hive调优比较困难,粒度较粗
-
迭代式算法无法表达
hive 工作的原理
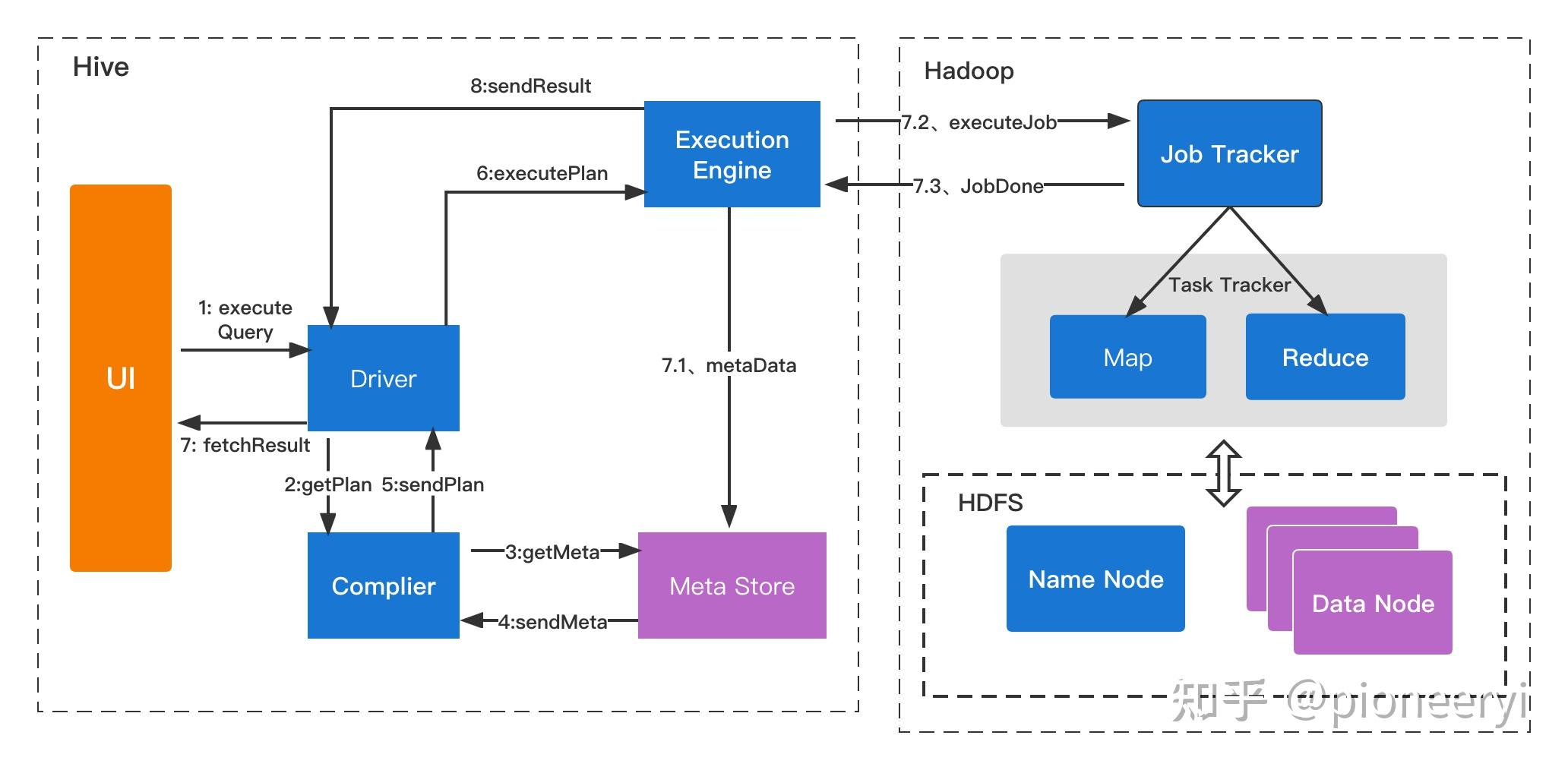
- ExecuteQuery(执行查询操作):命令行或Web UI之类的Hive接口将查询发送给Driver(任何数据驱动程序,如JDBC、ODBC等)执行;
- GetPlan(获取计划任务):Driver借助编译器解析查询,检查语法和查询计划或查询需求;
- GetMetaData(获取元数据信息):编译器将元数据请求发送到Metastore(任何数据库);
- SendMetaData(发送元数据):MetaStore将元数据作为对编译器的响应发送出去;
- SendPlan(发送计划任务):编译器检查需求并将计划重新发送给Driver。到目前为止,查询的解析和编译已经完成;
- ExecutePlan(执行计划任务):Driver将执行计划发送到执行引擎;
- FetchResult(拉取结果集):执行引擎将从datanode上获取结果集;
- SendResults(发送结果集至driver):执行引擎将这些结果值发送给Driver;
- SendResults (driver将result发送至interface):Driver将结果发送到Hive接口(即UI)
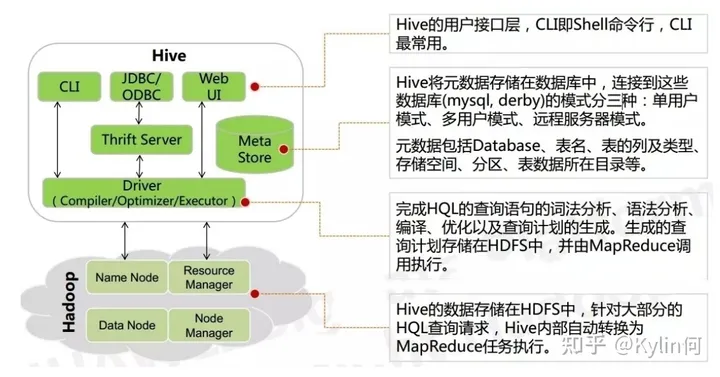
驱动器(Driver)
- 解析器(SQLParser): 将HQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行 语法 分析,比如表是否存在、字段是否存在、SQL语义是否有误。
- 编译器(Compiler): 对hql语句进行词法、语法、语义的编译(需要跟元数据关联),编译完成后会生成一个执行计划。 hive上就是编译成mapreduce的job。
- 优化器(Optimizer): 将执行计划进行优化,减少不必要的列、使用分区、使用索引等。优化job。
- 执行器(Executer): 将优化后的执行计划提交给hadoop的yarn上执行。提交job

 浙公网安备 33010602011771号
浙公网安备 33010602011771号