AC 自动机
前言
一个神清气爽,两个永不疲劳,三个长生不老!
AC 自动机,倍儿好!
前置知识
-
\(Trie\)
-
\(KMP\)
本文不作过多阐释。
视频讲解
看了 b 站的一个讲解视频,个人觉得把原理讲的很清楚,可以看看。
以及本文的参考链接:
定义
\(AC\) 自动机( \(Automaton\) ):在 \(Trie\) 树上的 \(KMP\)。
建立过程
-
先将给出的所有字符串建成一棵 \(Trie\) 树
-
在 \(Trie\) 树上运用 \(KMP\) 的思想对所有结点构造失配指针 \(fail\)
完成以上两个操作之后,就可以在 自动机 进行 多模式匹配 了。
失配指针(fail)
定义
定义: 用来辅助 \(AC\) 自动机进行多模式匹配的指针数组。(废话文学)
即,假定在 \(Trie\) 树上遍历至 \(x\) 得到的字符串为 \(word_x\),且 \(fail[x]\) 指向的是 \(y\)。
那么,\(word_y\) 就是 \(word_x\) 在这棵 \(Trie\) 树上所能匹配到的最长后缀。
可以跟 \(KMP\) 的 \(next\) 指针进行类比,两者都是失配时用于跳转的指针,
而不同点则是:
-
\(next\) 指针求的是 最长的相同前后缀,
-
\(fail\) 指针指向的是 所有模式串的前缀中匹配当前状态的最长后缀。
因为 KMP 只对一个模式串做匹配,而 AC 自动机要对多个模式串做匹配。有可能 fail 指针指向的结点对应着另一个模式串,两者前缀不同。—— oi-wiki
如果还是不理解的话,可以听一听我挂的 b 站链接,跟着 up 主推一遍,应该就可以轻松理解了。
题外笑话:
up 讲 \(fail\) 时说:
“ 你看这个 \(fail\) 数组告诉我们一个道理,不要当舔狗,舔到最后一无所有,此处不留爷自有留爷处,要到下一个地方去寻找新的可能!”
构建指针
- 先将 \(Trie\) 树中所有字符串的首字母添加进队列中。
queue<int> q;
for(int i = 0; i < 26; i ++) {
if(tr[0][i]) q.push(tr[0][i]);
}
- 遍历 \(Trie\) 树中 所有存在的结点, 每次枚举 当前结点 的 所有子结点。
int now;
while(!q.empty()) {
now = q.front(), q.pop();
for(int i = 0; i < 26; i ++) {
if(tr[now][i]) {
fail[tr[now][i]] = tr[fail[now]][i];
q.push(tr[now][i]);
}
else tr[now][i] = tr[fail[now]][i];
}
}
- 如果枚举的子结点存在,就可以通过 父亲结点 的 失配结点 \(fail\) 更新 该子结点 的 失配结点,同时将 该子结点 丢进队列里。
if(tr[now][i]) {
fail[tr[now][i]] = tr[fail[now]][i];
q.push(tr[now][i]);
}
- 否则,子结点不存在,直接更新节点编号信息即可。
else tr[now][i] = tr[fail[now]][i];
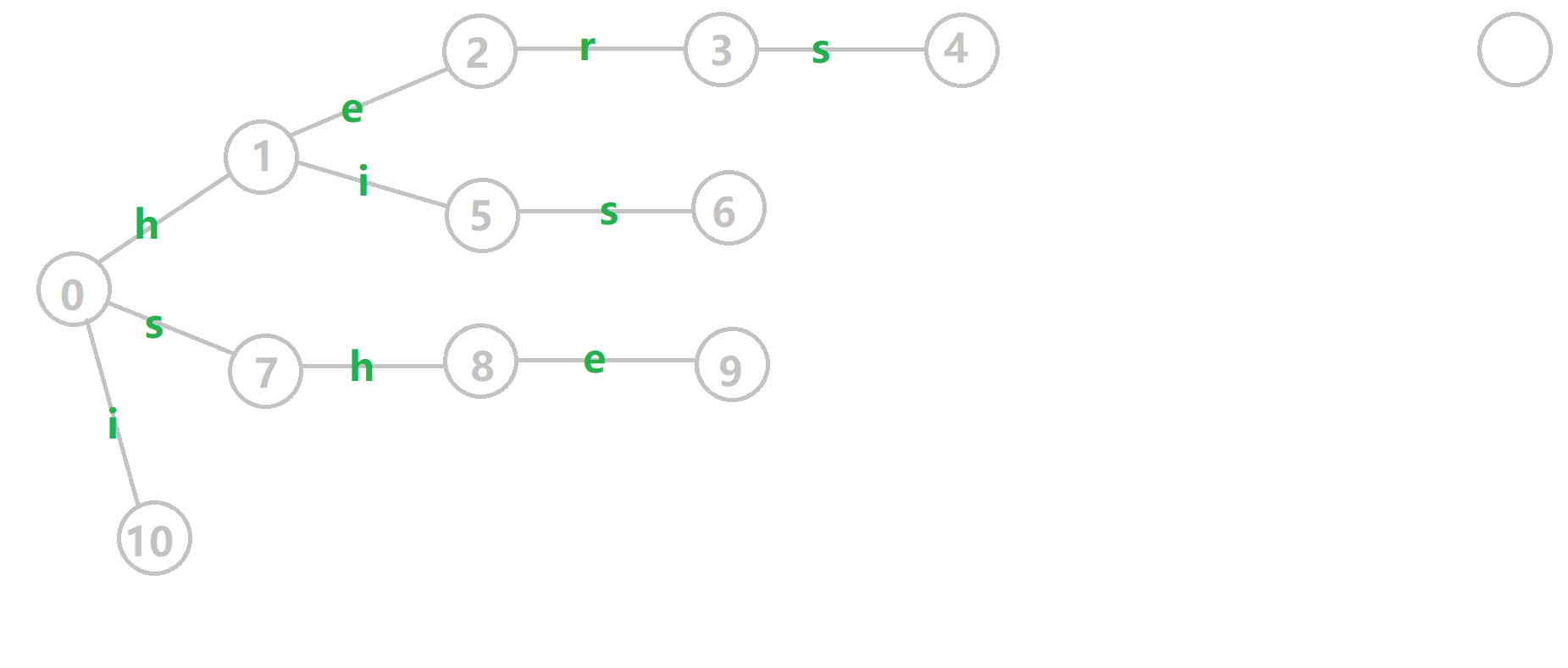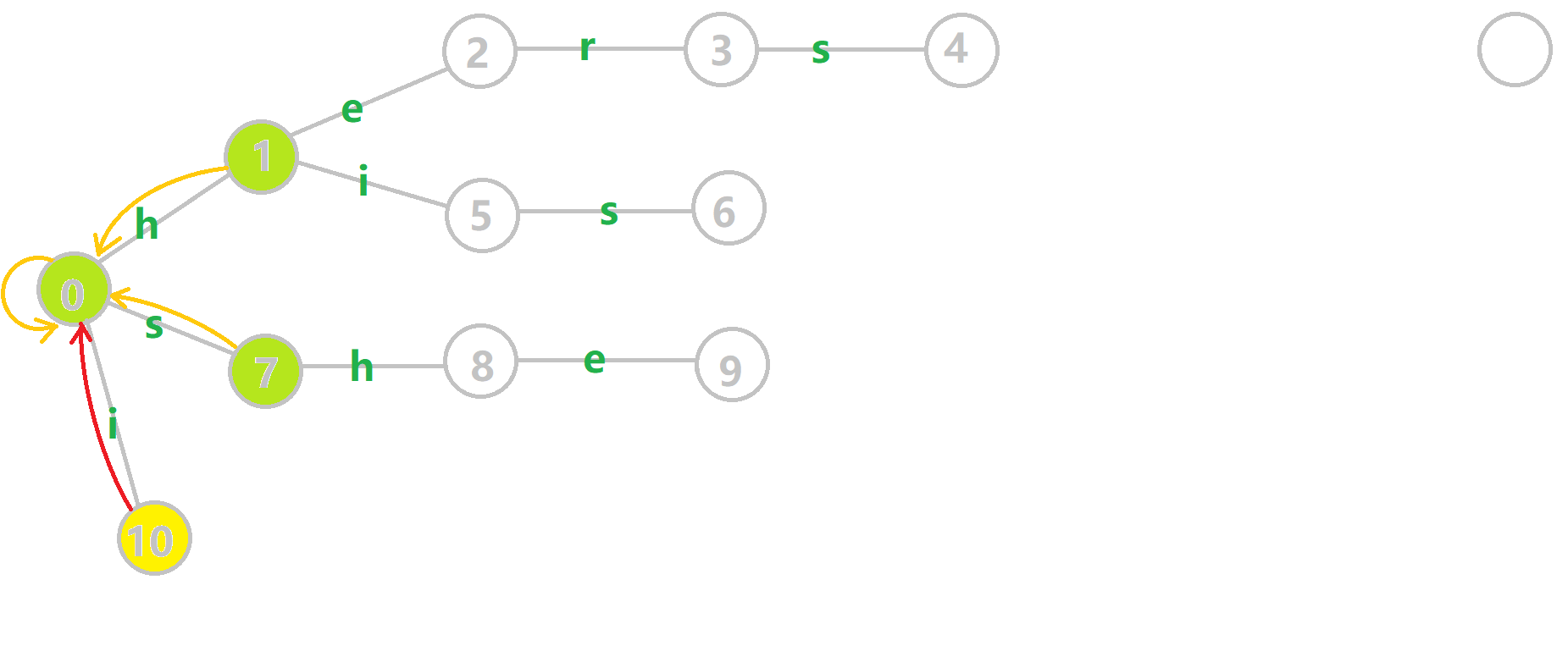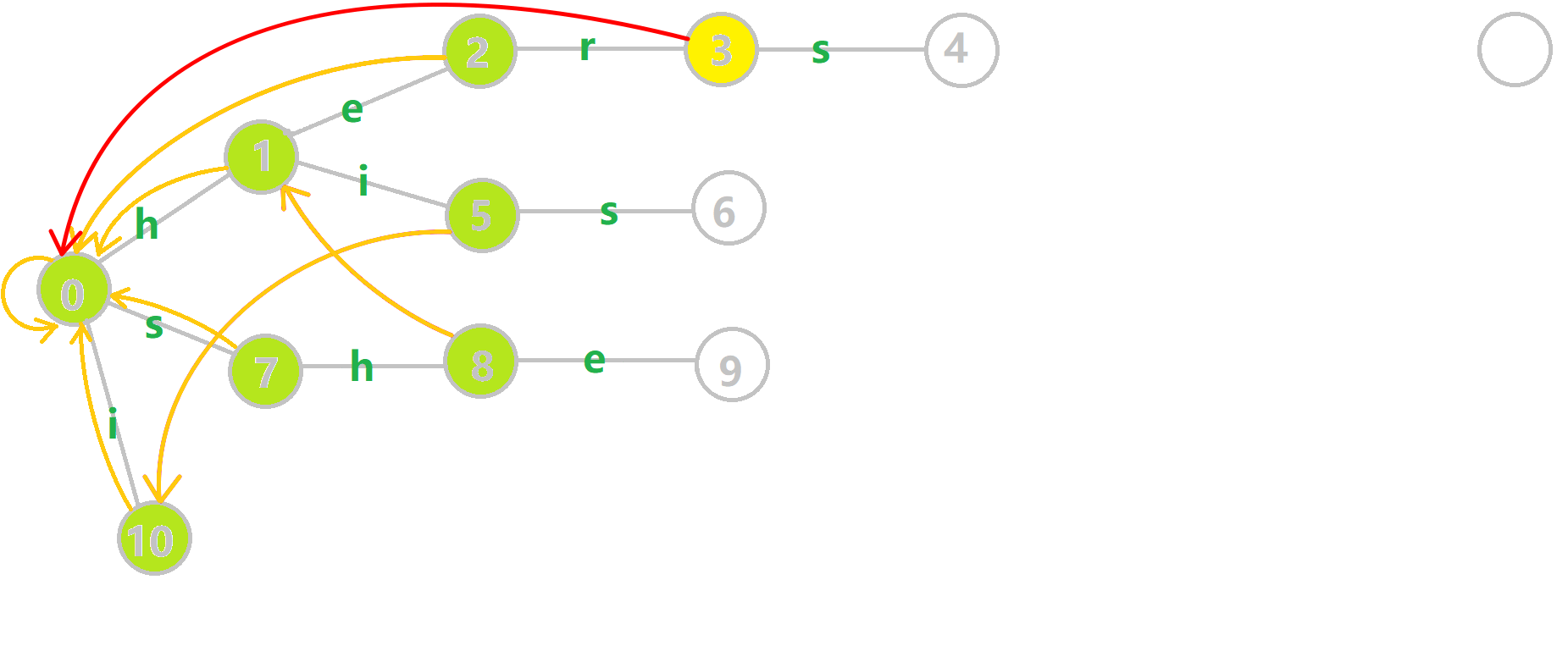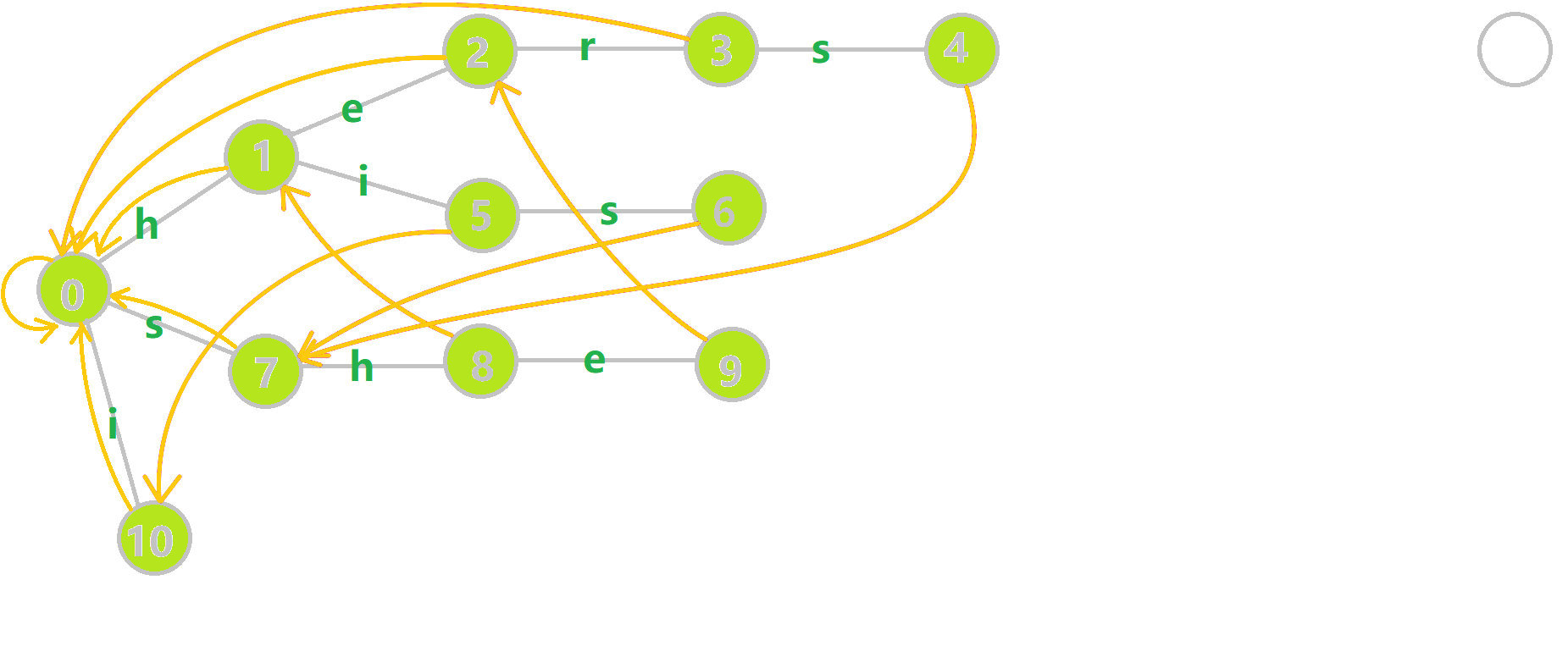
可以通过 \(oi-wiki\) 中的例子理解一下。
对字符串 \(i\)、 \(he\)、 \(his\)、 \(she\)、 \(hers\) 组成的字典树构建 \(fail\) 指针:
- 黄色结点:当前的结点 。
- 绿色结点:表示已经 \(BFS\) 遍历完毕的结点。
- 橙色的边:\(fail\) 指针。
- 红色的边:当前求出的 \(fail\) 指针。
构造全过程
\(Trie\) 树的构建过程不讲。
下面直接给出构造代码,感觉只要 \(fail\) 指针的构造理解了,其他的都很简单。
void ins() {
int len = strlen(s), v, now = 0;
for(int i = 0; i < len; i ++) {
v = s[i] - 'a';
if(!tr[now][v]) tr[now][v] = ++cnt;
now = tr[now][v];
}
num[now] = len;
}
void getfail() {
queue<int> q;
for(int i = 0; i < 26; i ++) {
if(tr[0][i]) q.push(tr[0][i]);
}
int now;
while(!q.empty()) {
now = q.front(), q.pop();
for(int i = 0; i < 26; i ++) {
if(tr[now][i]) {
fail[tr[now][i]] = tr[fail[now]][i];
q.push(tr[now][i]);
}
else tr[now][i] = tr[fail[now]][i];
}
}
}
多模式匹配
其实就是将 \(KMP\) 的匹配过程应用到 \(Trie\) 树上了。
-
从头开始匹配
-
利用 \(fail\) 指针找出所有匹配的模式串
-
累加答案,并将已经记录过答案的结点贡献清零
int query() {
int now = 0, res = 0, v;
for(int i = 0; i < len; i ++) {
v = s[i] - 'a';
now = tr[now][v];
for(int j = now; j && num[j] != -1; j = fail[j]) {
res += num[j];
num[j] = -1;
}
}
return res;
}
应用
模板题
给定 \(n\) 个模式串 \(s_i\) 和一个文本串 \(t\),求有多少个不同的模式串在文本串里出现过。两个模式串不同当且仅当他们编号不同。
只要理解了 \(AC\) 自动机的构造过程,就可以无脑过这道题了。
点击查看代码
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<queue>
using namespace std;
const int N = 1e6 + 5;
int n, cnt, ans, tr[N][27], tmp[N], fail[N];
char s[N];
void ins() {
int now = 0, v, len = strlen(s + 1);
for(int i = 1; i <= len; i ++) {
v = s[i] - 'a';
if(!tr[now][v]) tr[now][v] = ++cnt;
now = tr[now][v];
}
tmp[now] ++;
}
queue<int> q;
void get_fail() {
for(int i = 0; i < 26; i ++) {
if(tr[0][i]) {
fail[tr[0][i]] = 0;
q.push(tr[0][i]);
}
}
int now = 0;
while(!q.empty()) {
now = q.front(), q.pop();
for(int i = 0; i < 26; i ++) {
if(tr[now][i]) {
fail[tr[now][i]] = tr[fail[now]][i];
q.push(tr[now][i]);
}
else tr[now][i] = tr[fail[now]][i];
}
}
}
char t[N];
void query() {
int now = 0, len = strlen(t + 1), v;
for(int i = 1; i <= len; i ++) {
v = t[i] - 'a';
now = tr[now][v];
for(int j = now; j && tmp[j] != -1; j = fail[j]) {
ans += tmp[j];
tmp[j] = -1;
}
}
}
int main() {
scanf("%d", &n);
for(int i = 1; i <= n; i ++) {
scanf("%s", s + 1);
ins();
}
get_fail();
scanf("%s", t + 1);
query();
printf("%d", ans);
return 0;
}
模板拓展
给你一个文本串 \(S\) 和 \(n\) 个模式串 \(T1∼nT\),请你分别求出每个模式串 \(T_i\) 在 \(S\) 中出现的次数。对于 \(\%100\) 的数据,\(1 \le n \le 2 \times {10}^5\),\(T_{1 \sim n}\) 的长度总和不超过 \(2 \times {10}^5\),\(S\) 的长度不超过 \(2 \times {10}^6\)。
简单来说,就是利用数组 \(vis\) 来统计每个模式串在文本串中出现的次数,同时通过拓扑排序打标记,使 \(vis\) 从下往上更新,来降低时间复杂度。
void dfs() {
int now,f;
for(int i = 1; i <= cnt; i ++) {
if(!in[i]) q.push(i);
}
while(!q.empty()) {
now = q.front(), q.pop();
ans[tr[now].num] = tr[now].vis;
f = tr[now].fail, in[f] --;
tr[f].vis += tr[now].vis;
if(!in[f]) q.push(f);
}
}
点击查看代码
#include<cstdio>
#include<queue>
#include<algorithm>
#include<cstring>
using namespace std;
const int N = 2e6 + 5;
int n,cnt = 1,flag[N],ans[N],in[N];
char s[N],t[N];
struct node {
int son[26],num,fail,vis;
void clear(){memset(son,0,sizeof(son)),fail=num=vis=0;}
}tr[N];
void ins(int id) {
int len = strlen(s), now = 1,v;
for(int i = 0; i < len; i ++) {
v = s[i] - 'a';
if(!tr[now].son[v]) tr[now].son[v] = ++cnt;
now = tr[now].son[v];
}
if(!tr[now].num) tr[now].num = id;
flag[id] = tr[now].num;
}
queue<int> q;
void getfail() {
int now,ver,f;
for(int i = 0; i < 26; i ++) tr[0].son[i] = 1;
q.push(1);
while(!q.empty()) {
now = q.front(), q.pop();
f = tr[now].fail;
for(int i = 0; i < 26; i ++) {
ver = tr[now].son[i];
if(!ver) tr[now].son[i] = tr[f].son[i];
else tr[ver].fail = tr[f].son[i], in[tr[ver].fail] ++, q.push(ver);
}
}
}
void dfs() {
int now,f;
for(int i = 1; i <= cnt; i ++) {
if(!in[i]) q.push(i);
}
while(!q.empty()) {
now = q.front(), q.pop();
ans[tr[now].num] = tr[now].vis;
f = tr[now].fail, in[f] --;
tr[f].vis += tr[now].vis;
if(!in[f]) q.push(f);
}
}
void query() {
int now = 1,len = strlen(t);
for(int i = 0; i < len; i ++) {
now = tr[now].son[t[i] - 'a'];
tr[now].vis ++;
}
}
int main() {
//freopen("1.in", "r", stdin);
//freopen("1.out", "w", stdout);
scanf("%d",&n);
for(int i = 1; i <= n; i ++) scanf("%s",s), ins(i);
getfail();
scanf("%s",t);
query();
dfs();
for(int i = 1; i <= n; i ++) printf("%d\n",ans[flag[i]]);
return 0;
}
[TJOI2013]单词
小张最近在忙毕设,所以一直在读论文。一篇论文是由许多单词组成但小张发现一个单词会在论文中出现很多次,他想知道每个单词分别在论文中出现了多少次。
没什么特别大的思维难度,只要想到用 \(AC\) 自动机,在用个 \(siz\) 数组叠加贡献,最后直接输出即可。
点击查看代码
#include<cstdio>
#include<algorithm>
#include<cstring>
using namespace std;
const int N = 1e6 + 5;
int n, tr[N][26], cnt, siz[N], tmp[N], fail[N], q[N];
char s[N];
void ins(int id) {
int v, now = 0, len = strlen(s);
for(int i = 0; i < len; i ++) {
v = s[i] - 'a';
if(!tr[now][v]) tr[now][v] = ++cnt;
now = tr[now][v];
siz[now] ++;
}
tmp[id] = now;
}
int l, r;
void getfail() {
for(int i = 0; i < 26; i ++) {
if(tr[0][i]) q[++r] = tr[0][i];
}
int now;
while(l < r) {
now = q[++l];
for(int i = 0; i < 26; i ++) {
if(tr[now][i]) {
fail[tr[now][i]] = tr[fail[now]][i];
q[++r] = tr[now][i];
}
else tr[now][i] = tr[fail[now]][i];
}
}
for(int i = cnt; i >= 0; i --) {
siz[fail[q[i]]] += siz[q[i]];
}
}
int main() {
scanf("%d", &n);
for(int i = 1; i <= n; i ++) {
scanf("%s", s);
ins(i);
}
getfail();
for(int i = 1; i <= n; i ++) printf("%d\n", siz[tmp[i]]);
return 0;
}
USACO15FEB]Censoring G
FJ 把杂志上所有的文章摘抄了下来并把它变成了一个长度不超过 \(10^5\) 的字符串 \(s\)。他有一个包含 \(n\) 个单词的列表,列表里的 \(n\) 个单词记为 \(t_1 \cdots t_n\)。他希望从 \(s\) 中删除这些单词。
FJ 每次在 \(s\) 中找到最早出现的列表中的单词(最早出现指该单词的开始位置最小),然后从 \(s\) 中删除这个单词。他重复这个操作直到 \(s\) 中没有列表里的单词为止。注意删除一个单词后可能会导致 \(s\) 中出现另一个列表中的单词。
FJ 注意到列表中的单词不会出现一个单词是另一个单词子串的情况,这意味着每个列表中的单词在 \(s\) 中出现的开始位置是互不相同的。
请帮助 FJ 完成这些操作并输出最后的 \(s\)。
\(AC\) 自动机 + 栈
首先看到题目,多模式匹配,\(AC\) 自动机没跑了。
我们需要考虑的是,如何存储删除匹配单词后的序列,需要满足“尾部进尾部出”的性质——于是我们想到了栈
所以,
我们可以先用 所有单词 建立自动机,然后对 给定字符串 从头开始匹配,
用 栈 来记录匹配序列,同时记录栈中每个点所对应到 匹配串 上的位置
for(int i = 0; i < len; i ++) {
v = t[i] - 'a';
now = tr[now][v];
sta[++top] = now, seq[top] = i;
…………
}
如果 到当前点 已经匹配到一个完整单词了,就将 栈 中 所对应的一段序列 删除,
并通过 栈 更新 删除当前一段连续区间后 目前在 \(Trie\) 树上的位置信息。
if(num[now]) {
top -= num[now];
if(!top) now = 0;
else now = sta[top];
}
最后栈中存储的就是 删去所有匹配到的单词后 的串的位置信息,利用 \(seq\) 输出即可。
for(int i = 1; i <= top; i ++) printf("%c", t[seq[i]]);
点击查看代码
#include<cstdio>
#include<queue>
#include<cstring>
#include<algorithm>
using namespace std;
const int N = 1e6 + 5;
int n, tr[N][26], num[N], cnt, fail[N], sta[N], top, seq[N];
char s[N], t[N];
void ins() {
int len = strlen(s), v, now = 0;
for(int i = 0; i < len; i ++) {
v = s[i] - 'a';
if(!tr[now][v]) tr[now][v] = ++cnt;
now = tr[now][v];
}
num[now] = len;
}
void getfail() {
queue<int> q;
for(int i = 0; i < 26; i ++) {
if(tr[0][i]) q.push(tr[0][i]);
}
int now;
while(!q.empty()) {
now = q.front(), q.pop();
for(int i = 0; i < 26; i ++) {
if(tr[now][i]) {
fail[tr[now][i]] = tr[fail[now]][i];
q.push(tr[now][i]);
}
else tr[now][i] = tr[fail[now]][i];
}
}
}
void solve() {
int now = 0, len = strlen(t), v;
for(int i = 0; i < len; i ++) {
v = t[i] - 'a';
now = tr[now][v];
sta[++top] = now, seq[top] = i;
if(num[now]) {
top -= num[now];
if(!top) now = 0;
else now = sta[top];
}
}
}
int main() {
scanf("%s", t);
scanf("%d", &n);
for(int i = 1; i <= n; i ++) {
scanf("%s", s);
ins();
}
getfail();
solve();
for(int i = 1; i <= top; i ++) printf("%c", t[seq[i]]);
return 0;
}
[USACO12JAN]Video Game G
Bessie 在玩一款游戏,该游戏只有三个技能键
A,B,C可用,但这些键可用形成 \(n\) 种特定的组合技。第 \(i\) 个组合技用一个字符串 \(s_i\) 表示。Bessie 会输入一个长度为 \(k\) 的字符串 \(t\),而一个组合技每在 \(t\) 中出现一次,Bessie 就会获得一分。\(s_i\) 在 \(t\) 中出现一次指的是 \(s_i\) 是 \(t\) 从某个位置起的连续子串。如果 \(s_i\) 从 \(t\) 的多个位置起都是连续子串,那么算作 \(s_i\) 出现了多次。
若 Bessie 输入了恰好 \(k\) 个字符,则她最多能获得多少分?
\(AC\) 自动机 + DP
设 \(dp_{i,j}\) 为长度为 \(i\) 时,末尾字符在 \(tire\) 树中编号为 \(j\) 的最大得分。
\(num_i\) 则是匹配到 \(i\) 位置的字符串的所有子串产生的贡献和。
每次枚举匹配长度 \(i\), 再枚举上一个字符的位置信息 \(j\) 以及当前末位的字符 \(k\)(\(A/B/C\)),取最大值,易得转移式:
则,
for(int i = 1; i <= m; i ++) {
for(int j = 0; j <= cnt; j ++) {
for(int k = 0; k < 3; k ++) {
dp[i][tr[j][k]] = max(dp[i][tr[j][k]], dp[i - 1][j] + num[tr[j][k]]);
}
}
}
点击查看代码
#include<cstdio>
#include<cstring>
#include<vector>
#include<queue>
#include<algorithm>
using namespace std;
const int N = 1e3 + 5, M = 305;
char s[N];
int cnt, ans, tr[M * 25][3], fail[M * 25], num[M * 3], dp[N << 1][M << 1];
void ins() {
int now = 0, v, len = strlen(s);
for(int i = 0; i < len; i ++) {
v = s[i] - 'A';
if(!tr[now][v]) tr[now][v] = ++cnt;
now = tr[now][v];
}
num[now] ++;
}
void getfail() {
queue<int> q;
for(int i = 0; i < 3; i ++) {
if(tr[0][i]) q.push(tr[0][i]);
}
int now;
while(!q.empty()) {
now = q.front(), q.pop();
for(int i = 0; i < 3; i ++) {
if(tr[now][i]) {
fail[tr[now][i]] = tr[fail[now]][i];
q.push(tr[now][i]);
}
else tr[now][i] = tr[fail[now]][i];
}
num[now] += num[fail[now]];
}
}
int n, m;
int main() {
scanf("%d %d", &n, &m);
for(int i = 1; i <= n; i ++) {
scanf("%s", s);
ins();
}
getfail();
memset(dp, -0x3f, sizeof(dp));
for(int i = 0; i <= m; i ++) dp[i][0] = 0;
for(int i = 1; i <= m; i ++) {
for(int j = 0; j <= cnt; j ++) {
for(int k = 0; k < 3; k ++) {
dp[i][tr[j][k]] = max(dp[i][tr[j][k]], dp[i - 1][j] + num[tr[j][k]]);
}
}
}
for(int i = 0; i <= cnt; i ++) ans = max(ans, dp[m][i]);
printf("%d", ans);
return 0;
}
[SDOI2014] 数数
我们称一个正整数 \(x\) 是幸运数,当且仅当它的十进制表示中不包含数字串集合 \(s\) 中任意一个元素作为其子串。例如当 \(s = \{22, 333, 0233\}\) 时,\(233\) 是幸运数,\(2333\)、\(20233\)、\(3223\) 不是幸运数。给定 \(n\) 和 \(s\),计算不大于 \(n\) 的幸运数个数。
AC 自动机 和 数位 DP 的结合
这题有点好玩的就是说。
点击查看代码
/*
数位dp的定义有点子东西
*/
#include<cstdio>
#include<queue>
#include<algorithm>
#include<cstring>
using namespace std;
const int N = 1505, mod = 1e9 + 7;
int n, m, cnt = 1, a[N], num[N], tr[N][10], fail[N];
char s[N], t[N];
void ins() {
int now = 1, len = strlen(t), v;
for(int i = 0; i < len; i ++) {
v = t[i] - '0';
if(!tr[now][v]) tr[now][v] = ++cnt;
now = tr[now][v];
}
num[now] = 1;
}
void getfail() {
queue<int> q; int now;
for(int i = 0; i < 10; i ++) tr[0][i] = 1;
q.push(1);
while(!q.empty()) {
now = q.front(), q.pop();
num[now] |= num[fail[now]];
for(int i = 0; i < 10; i ++) {
if(tr[now][i]) {
fail[tr[now][i]] = tr[fail[now]][i];
q.push(tr[now][i]);
}
else tr[now][i] = tr[fail[now]][i];
}
}
}
int dp[2][N][2];
int dfs() {
for(int i = 1; i <= s[1] - '0'; i ++) {
if(!num[tr[1][i]]) dp[1][tr[1][i]][i == s[1] - '0'] ++;
}
for(int i = 2; i <= n; i ++) {
memset(dp[i & 1], 0, sizeof(dp[i & 1]));
for(int j = 1; j <= 9; j ++) {
if(!num[tr[1][j]]) dp[i & 1][tr[1][j]][0] ++;
}
for(int j = 1; j <= cnt; j ++) {
if(num[j]) continue;
if(dp[(i - 1) & 1][j][0]) {
for(int k = 0; k <= 9; k ++) {
if(num[tr[j][k]]) continue;
dp[i & 1][tr[j][k]][0] = (dp[i & 1][tr[j][k]][0] + dp[(i - 1) & 1][j][0]) % mod;
}
}
if(dp[(i - 1) & 1][j][1]) {
for(int k = 0; k <= s[i] - '0'; k ++) {
if(num[tr[j][k]]) continue;
dp[i & 1][tr[j][k]][k == s[i] - '0'] = (dp[i & 1][tr[j][k]][k == s[i] - '0'] + dp[(i - 1) & 1][j][1]) % mod;
}
}
}
}
int ans = 0;
for(int i = 1; i <= cnt; i ++) {
if(num[i]) continue;
ans = (ans + dp[n & 1][i][0] + dp[n & 1][i][1]) % mod;
}
return ans;
}
int main() {
scanf("%s", s + 1), n = strlen(s + 1);
scanf("%d", &m);
for(int i = 1; i <= m; i ++) {
scanf("%s", t);
ins();
}
getfail();
printf("%d", dfs());
return 0;
}
推荐题目
-
[HNOI2004] L 语言
-
[JSOI2007]文本生成器
……
拓展
\(oi-wiki\) 上有对 有限状态自动机 以及 \(KMP\) 的延申拓展,有兴趣的大佬可以去研究研究(本人已躺平.jpg)。
总结
\(AC\) 自动机的精华之处就在于将 \(KMP\) 的单串匹配拓展为 多模式匹配。
且一般的题目信息都会给得很明显,构建过程等变化和代码实现的难度都不算太大。
只要理解到 \(fail\) 数组的构造原理,厘清题面中的各种信息,应该就会比较有想法。
至少可以轻松理解题解(针对我这种菜狗而言)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号