一文搞懂KNN算法原理
什么是KNN算法 ?
KNN的全称是K Nearest Neighbors,通常翻译为K最邻近算法。是最基础的一个分类算法。本文以 iris 鸢(yuan)尾花数据集为例详细说明到底什么是KNN算法。
表征空间(特征空间)
在讲解KNN算法之前,首先要给大家科普几个基础概念。有了这几个概念我们再学习KNN算法就容易多了。
1、特征参数
2、表征空间(特征空间)
3、特征描述
特征参数比较容易理解,就是描述一个事物的有关参数。在iris鸢尾花数据集中就是iris.feature_names:sepal length (cm):花瓣长度;sepal width (cm):花瓣宽度;petal length (cm):萼片长度; petal width (cm):萼片宽度。
为了防止有人不明白这几个名词什么意思,我一个理工直男搞来了下面这张图。大家再复习一下中学的生物知识。
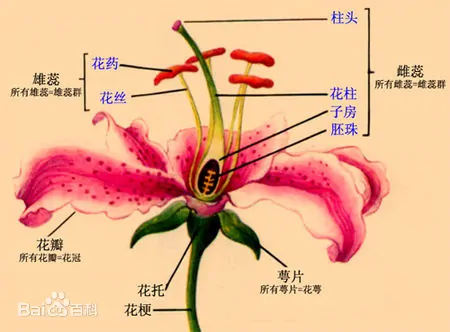
把这四个参数合起来,就成为一个描述鸢尾花的表征空间(特征空间)。其数学描述为:【花瓣长度,花瓣宽度,萼片长度,萼片宽度】。我们可以根据该特征空间对鸢尾花进行描述,并进行后续的统计分类。
iris 数据集中包含了三种鸢尾花类型,分别是:0 Setosa 山鸢尾、 1 Versicolor 变色鸢尾、 2 Virginica 维吉尼亚鸢尾。

在这里我们应该可以看出来了,其实描述鸢尾花的这四个参数,是前面两个一组描述花瓣,后面两个一组描述萼片。而参数1:花瓣长度和参数4:萼片宽度没有太大关系,参数2:花瓣宽度和参数3:萼片长度也没有太大关系。但是,我们根据这四个参数就可以对鸢尾花进行一个比较完整的描述。
# 导入 iris 数据集 from sklearn.datasets import load_iris # 加载 iris 数据集 iris = load_iris() X,Y = iris.data, iris.target A = X[:,0] B = X[:,1] C = X[:,2] D = X[:,3] plt1.scatter(A[0:50], B[0:50], c = 'r') plt1.scatter(A[50:100], B[50:100], c = 'g') plt1.scatter(A[100:150], B[100:150], c = 'b') plt2.scatter(C[0:50], D[0:50], c = 'r') plt2.scatter(C[50:100], D[50:100], c = 'g') plt2.scatter(C[100:150], D[100:150], c = 'b')
花瓣特征: 萼片特征:
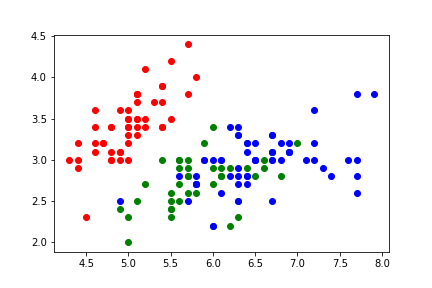
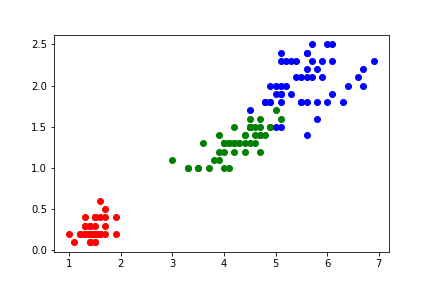
其中红色为类别0:山鸢尾,绿色为类别1:变色鸢尾;蓝色为类别2:维吉尼亚鸢尾。
我们可以看到不同类别的鸢尾花,其数据特征是不一样的。也就是它们的表征空间描述是不同的。
在这里,我们应该大致明白特征参数和表征空间大概是怎么一个回事了。
KNN算法原理
在这里,我们再讲解KNN算法就比较容易了。KNN算法就是在其表征空间中,求K个最邻近的点。根据已知的这几个点对其进行分类。
如果其特征参数只有一个,那么就是一维空间。
如果其特征参数只有两个,那么就是二维空间。
如果其特征参数只有三个,那么就是三维空间。
如果其特征参数大于三个,那么就是N维抽象空间。
在表征空间中,不同点的距离采用如下所示的欧几里得方法进行计算。

K值根据经验选择最合适的参数,太小不够稳健,太大的话容易受样本不足制约。也可以根据交叉验证的方法,确定最优的K值。一般取5~10之间的一个数。

参考:https://cloud.tencent.com/developer/article/1574868
我这里不再赘述了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号