
【论文笔记】LayoutLMv2:将视觉信息加入到预训练阶段的跨模态文档预训练模型
概述
LayoutLMv2是对LayoutLM的改进,主要有以下几点区别:
- 将视觉信息加入到了预训练阶段,而不是LayouLM中的微调阶段
- 删除了MDC,添加了text-image alignment和text-imgae matching两个预训练任务
- 将spatial-aware的自注意力机制整合到了transformer中
模型
模型的整体结构如图1所示:
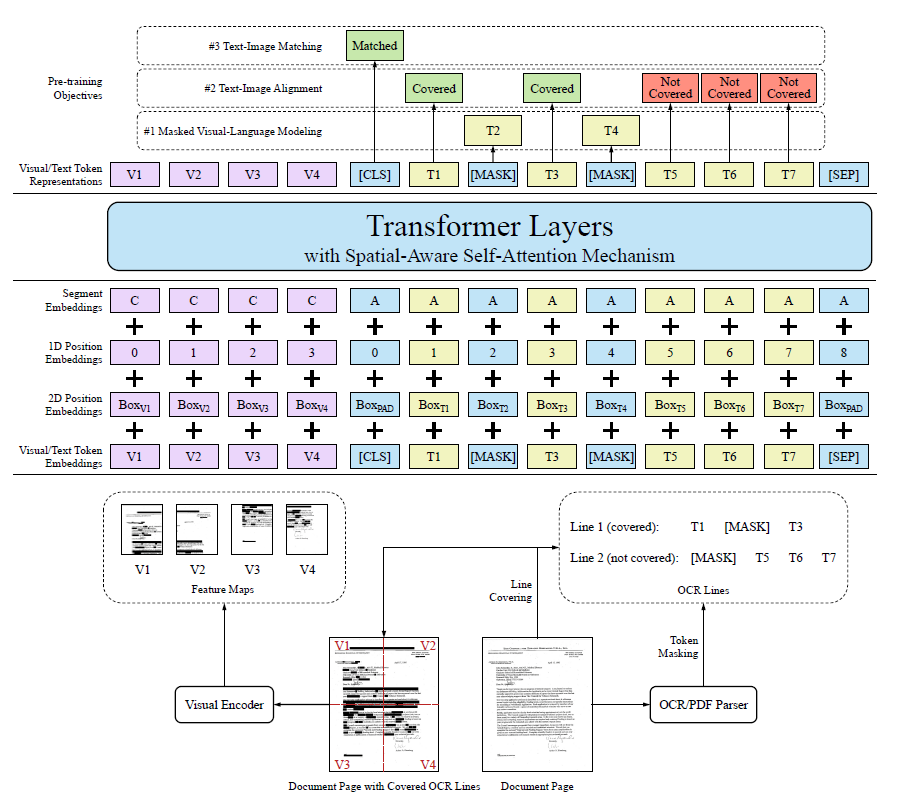
Embedding
由于大部分和LayoutLM一样,就不多介绍了,这里简单说下不一样的地方。首先是加入了visual embedding,对于token的embedding,先将图片缩放到224x224,输入到CNN中,大小变为WxH,然后将其flatten,并通过全连接层将维度变换到和其它embedding层一样;对于1D position embedding,和text embedding layer共享;对于segment embedding使用符号[C](text的segment embedding用的是[A]和[B])。如图2所示:
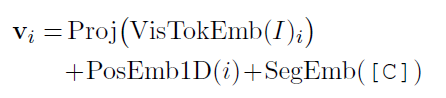
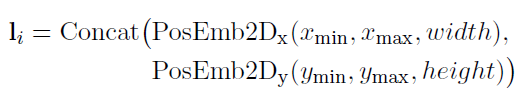
Spatial-Aware Self-Attention
为了获得局部不变性,LayoutLMv2使用了这个机制,即在原始attention权重矩阵下加上1维和2维的偏置,如图4所示:
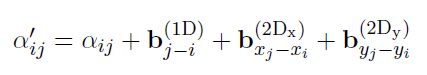
预训练
预训练有三个任务:Masked Visual-Language Modeling、Text-Image Alignment、Text-Image Matching。
Masked Visual-Language Modeling
和v1一样,预测遮蔽(mask)的text token。对于被遮蔽的text token,对应的图片区域也要遮蔽掉,防止信息泄露。
Text-Image Alignment
这是一个细粒度的跨模态对齐任务。图片上的一些token lines会被覆盖(cover)掉,然后使用对应的text token预测图片中的token line是否被覆盖。这样就能够将视觉和文本信息在预训练阶段结合起来。在计算TIA Loss的时候,被遮蔽(mask)的text token不会参与计算。
Text-Image Matching
这是一个粗粒度的跨模态对齐任务,用于预测该文本在该文档里(还是在其它文档里)。预训练时会构造负样本(替换文档或丢弃文档),正负样本使用同样的覆盖和遮蔽操作。最后通过[CLS]预测是否匹配,不匹配的话text token全部为“已覆盖(Covered)”
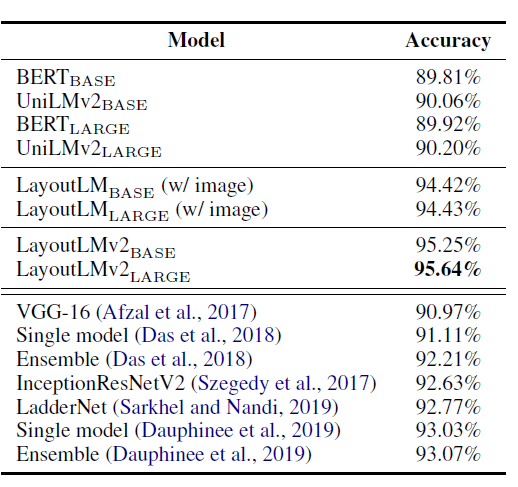
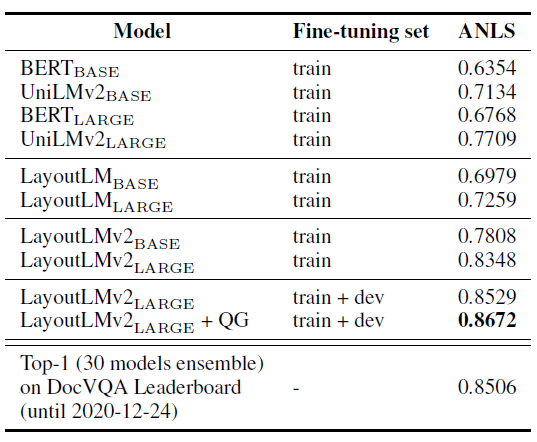
实验
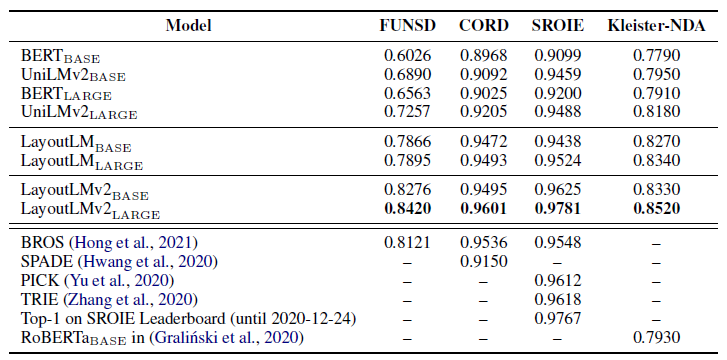
实体提取的F1分数如图5所示:

总结
LayoutLMv2最大的贡献在于将视觉信息也加入到了预训练阶段中,并通过TIA和TIM实现文本和视觉两个模态的信息联合。

