

【论文笔记】LayoutLM:首次结合文本和版式信息的文档预训练模型
概述
LayoutLM是一个基于Bert,结合了文本和版式信息的文档预训练模型,在多个下游任务中都达到了当时SOTA的结果。
模型
模型的总体结构如图1所示:
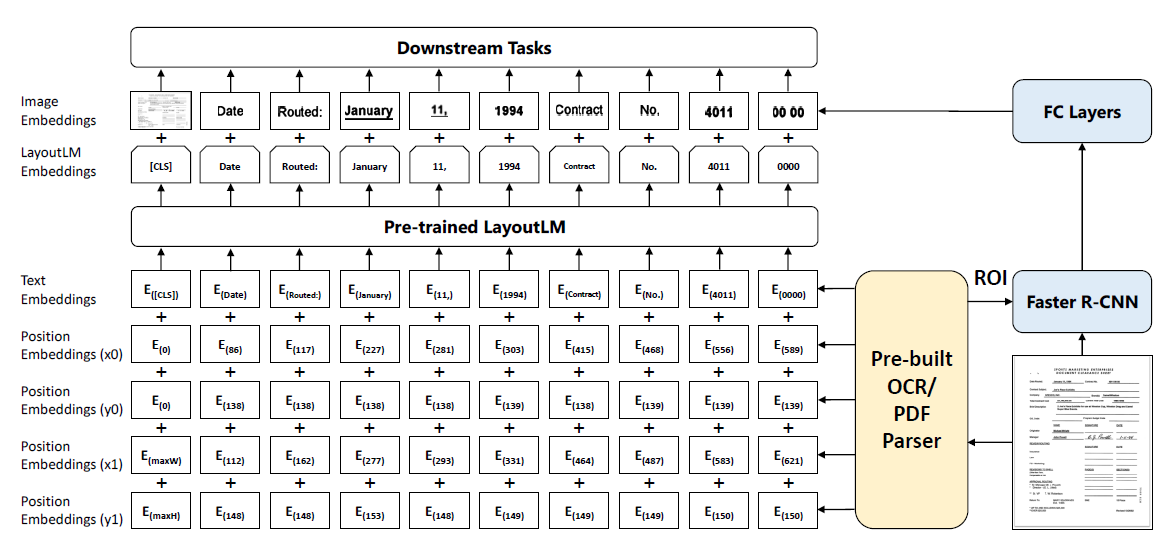
需要注意的是,Image Embedding是在微调阶段加入的,而不是预训练阶段,这也是LayoutLM与LayoutLMv2有明显区别的地方。
预训练阶段
预训练阶段有两个目标:Masked Visual-Language Model和Multi-label Document Classification。
Masked Visual-Language Model
和Bert的MLM类似,不过是2D版本的,随机遮蔽一些token但保留2D Position Embedding,然后预测遮蔽的token,通过这个方式能够将视觉和语言两个模态结合起来。
Multi-label Document Classification
为了更好地适应文档理解任务,需要高层次的文档表示,因此在预训练时添加了这个多分类任务。论文中还提到这个是可选的,并且在以后不会使用这个任务预训练更大的模型(实际上从LayoutLMv2开始就没有使用这个目标函数了)。
微调阶段
论文对三类下游任务做了微调,分布是:表单理解、票据理解和文档图像分类。对于前两个任务,LayoutLM对每个token预测{B,I,E,S,O}以及实体的类别。对于最后一个任务,LayoutLM使用“[CLS]”预测文档的类别。
实验
表单理解的实验结果如图2所示(数据集是FUNSD):
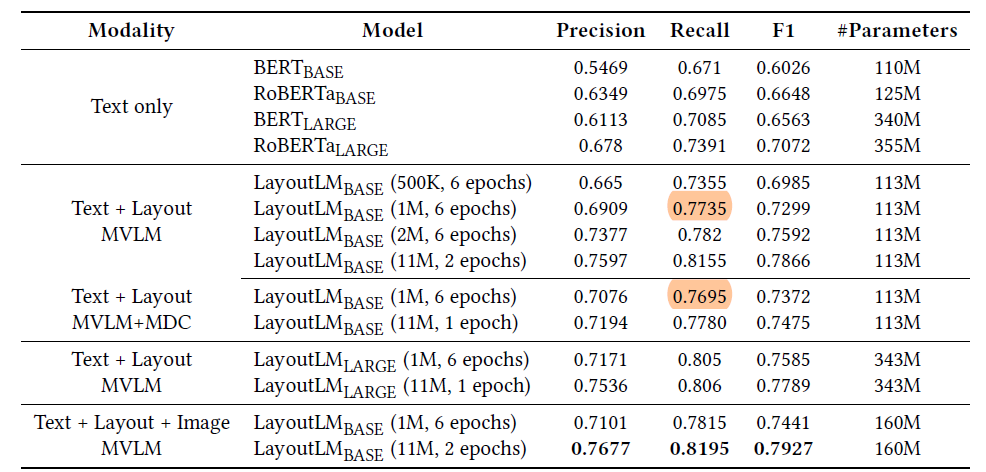
票据理解的实验结果如图3所示(数据集是SROIE):
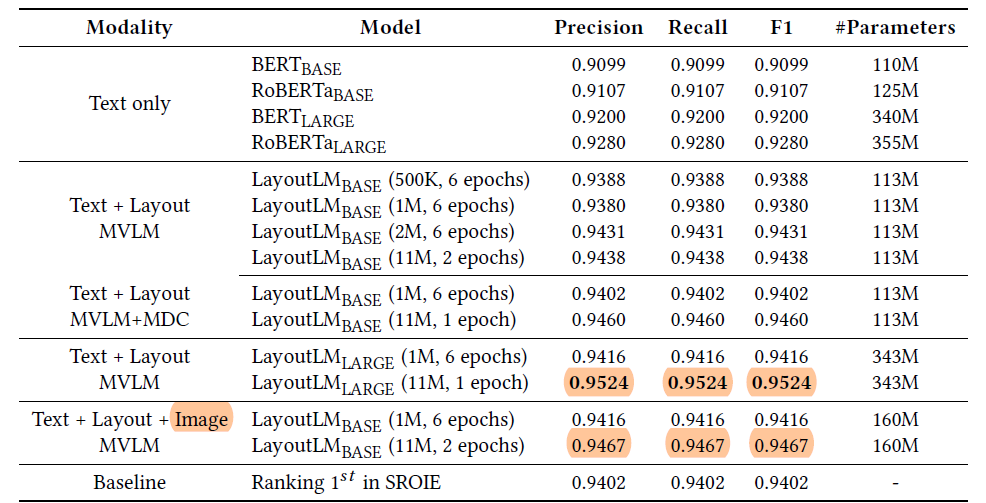
文档分类的实验结果如图4所示(数据集是RVL-CDIP)
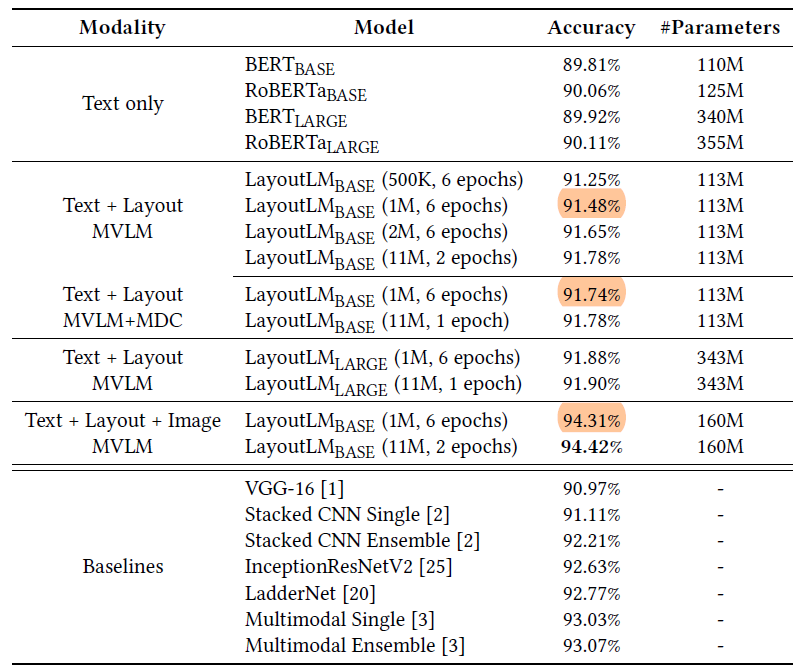
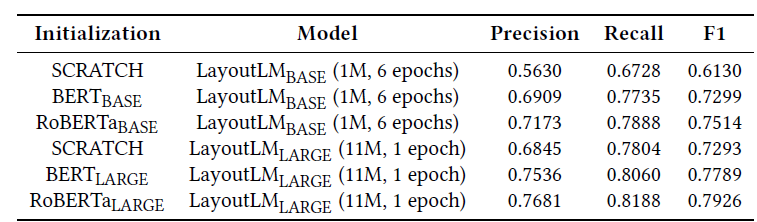
最后是不同初始化方法对模型性能的影响,如图5所示:
总结
LayoutLM是首次结合文本和版式信息的预训练模型,在当时达到了SOTA的性能。不过没有把图像信息加到预训练阶段中,这也是模型需要改进的地方。另外MDC对于某些下游任务并不好用,需要替换或者改进。
分类:
论文笔记


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!