
【论文笔记】EnsNet:使用Pix2Pix思想的文字擦除网络
概述
EnsNet是一个使用Pix2Pix思想的文字擦除网络,它的主要贡献如下:
- 可以使用整张图片来进行端到端训练
- 使用lateral connection捕捉更多的特征
- 提出refined loss保证生成图片的真实性
- 提出local-aware的判别器,让网络的优化目标集中在文字区域上
模型
模型的总体结构如图1所示:
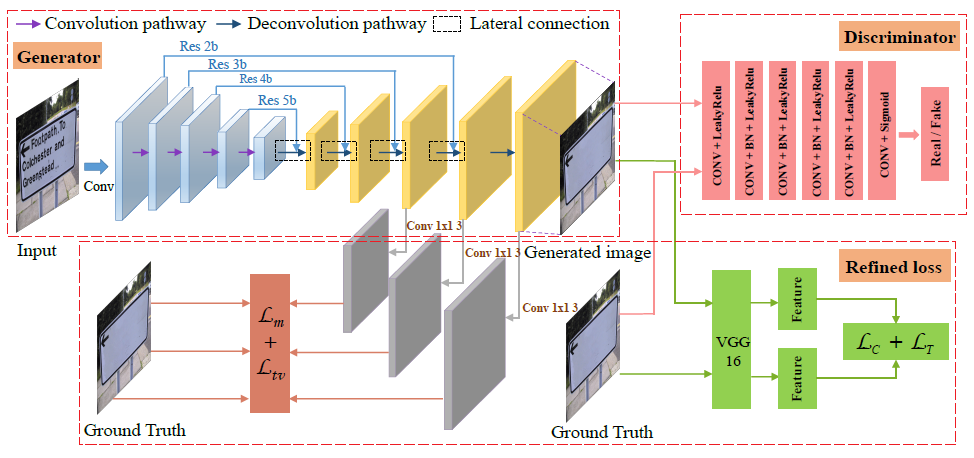
生成器
生成器首先是通过ResNet18进行下采样,然后使用反卷积进行上采样,中间使用lateral connection捕捉更多的特征。其中输入是带有文字的512x512的图片,输出的是生成的消除了文字的图片。
生成器loss的第一部分为CGAN生成器loss,也就是要最大化\(log(D(x, G(x,z)))\),其中\(x\)是输入的图片,\(z是随机噪声\)。第二部分是论文提出的refined loss,后面将会介绍。
判别器
判别器的结构也很简单,只是一些卷积层的叠加。对于正例,判别器的输入是原始图片和消除文字的ground truth图片在通道这个维度上的拼接,因此判别器输入的shape为:6x512x512,该输入经过判别器后,输出的shape为:1x62x62,其中每个点的感受野是70x70,那么对于正例来说,我们希望输出的1x62x62的张量全为1,表示这都是真的。对于负例,判别器的输入是原始图片和生成图片在通道维度上的拼接,我们希望输出的1x62x62的张量文字区域为0,非文字区域为1,注意这里和Pix2Pix中的判别器是不同的,Pix2Pix中判别器倾向于把生成的图片全部预测为0,而在本论文中只会将文字区域预测为0。这就是论文中提到的local-aware判别器,集中优化文字区域。我个人认为local-aware判别器是本论文的核心,下面再展开说一下这是怎么实现的。
论文使用了Mask来实现这个功能,每张图片都对应了一个Mask,大小也是512x512,如果像素对应位置是文字,该像素值为1,也就是白色,否则值为0,如图2(原始图片)和图3(对应的Mask)所示:


判别器需要最大化:
其中\(label_{i}\)表示该点是否为真,其值只能为0或1。对于正例,\(label_i\)全为1,那么就变成了最大化:
对于负例,Pix2Pix中所有的\(label_i\)全为0,那么就变成了最大化:
对于负例,本论文的label是这样设置的:
就是上述我解释的Mask取反,若对应感受野中有文字(\(sum(M)>0\)),取值为0,否则取值为1。通过这样设置label,对于负例,判别器需要最大化:
这样判别器就会倾向于认为生成图片的文字区域是假的,其他区域是真的,达到了擦除文字的效果。
最后将正例和负例的loss加起来除以2就可以得到判别器的loss了。
Refined loss
Refined loss由四部分组成,分别是:multiscale regression loss、content loss、texture loss以及total variation loss。
The multiscale regression loss
该loss的公式如下:
其中 \(I_{out(i)}\) 是生成器某一个反卷积层的输出,论文中使用了最后三层,大小分别为原图的 \(\frac{1}{4}\),\(\frac{1}{2}\)和\(1\)。\(I_{gt(i)}\)是对应大小的消除了文字区域的ground truth。\(M_{i}\)是对应大小的Mask,文字区域值为1,非文字区域值为0。\(\lambda\)和\(\alpha\)为权重。这个loss能够使得生成的图片在整体上更接近ground truth。此外,官方代码中对这个loss做了一些调整,代码中只对最后一反卷积层的输出使用了Mask,并且\(\alpha\)设为了\(1\),论文中\(\alpha\)为6。
The content loss
将生成的图片和ground truth送入到VGG16中,然后从中抽取几个特征层,比较生成图片的特征图和gt的特征图的差异,这就是content loss的内容。该loss的公式如下:
其中,\(I_{comp}\)是将\(I_{out}\)的非文字区域替换为\(I_{gt}\)而成的。\(A_{n}\)可以理解为VGG16前面n个卷积层。这个loss更够让模型集中优化文字区域部分。不过,官方代码中\(I_{comp}\)是将\(I_{out}\)的文字区域替换为了\(I_{gt}\),不知道是不是bug。。。
The texture loss
texture loss通过优化Gram矩阵差值的1范数来使得生成的图片和ground truth的风格更加接近。公式如下:
Gram矩阵等于矩阵的转置乘以自身,可以用来表示一个图片的整体风格,通过计算两个Gram矩阵的差值的1范数,可以估计两个图片之间的风格差异。
The total variation loss
这一个loss的目的是全局降噪,使得生成的图片更加平滑。公式如下:
最终可以得到refined loss,公式如下:
也就是几个loss的加权和。
实验
使用的数据集
合成数据集,ICDAR2013,ICDAR2017 MLT。
评估标准
使用的是图像修复的评估标准,包括:\(l_2\)error、PSNR、SSIM、AGE、pEPs、pCEPS。其中PSNR和SSIM越高越好,其它指标越低越好。由于ICDAR2013没有ground truth,因此通过文字检测算法的结果来评估。
消融实验
消融实验和简单的模型比较的结果如图4所示:

模型比较
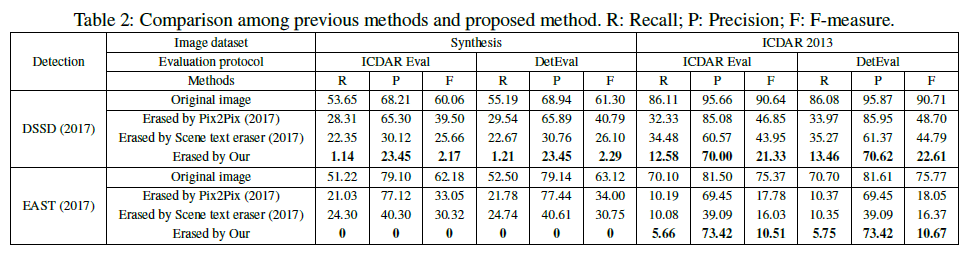
更进一步的比较如图5所示:
总结
本论文主要创新点在于对Pix2Pix方法进行了改进,使用Mask实现了local-aware的判别器,提升了文字擦除效果。

