
【论文笔记】DETR:用transformer做目标检测
概述
DETR使用了目前很火的transformer实现了目标检测,同时也是一个真正意义上的anchor-free模型(不像FCOS,用锚点代替锚框)。DETR主要有以下两个特点:
- 使用了bipartite matching loss,为每一个预测框唯一地分配一个gt框
- 在transformer中使用了parallel decoding
然而它也有两个明显的缺点:
- 难以检测小物体
- 由于使用了transformer,训练时间很长
模型结构
DETR的模型结构如图1所示:
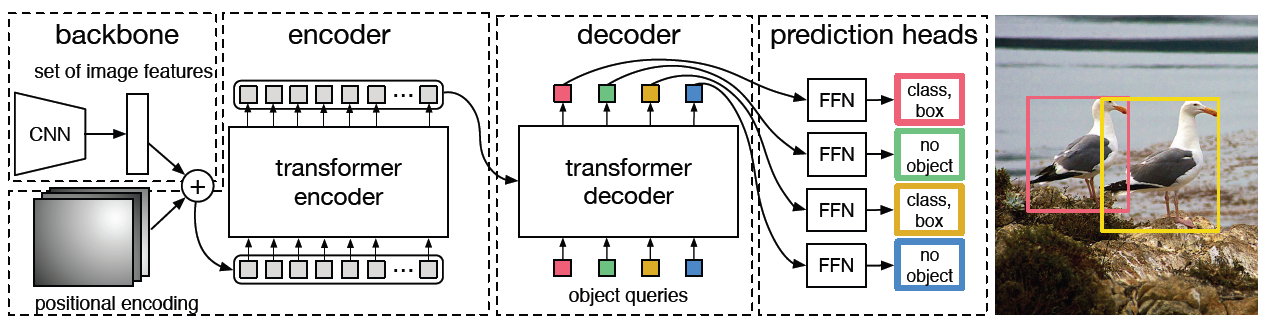
首先将图片\((3, H, W)\)输入到由CNN网络构成的backbone,得到feature map\((C, \frac{H}{32}, \frac{W}{32})\),论文中\(C = 2048\),然后将该feature map输入到一个\(1*1\)卷积,输出\((embed\_dim, \frac{H}{32}, \frac{W}{32})\),论文中\(embed\_dim = 256\)。由于transformer的encoder希望的输入是一个序列,因此将feature map的reshape成\((embed\_dim, \frac{H}{32}\frac{W}{32})\),最后由于transformer无法检测位置信息,还需要将reshape之后的feature map与位置编码加起来,输入到encoder中。decoder的输入称为"object queries",这相当于是一个可以学习的位置编码,作用相当于teacher forcing。decoder的结构和原始的transformer一样,先是对"object queries"进行self attention,然后将输出作为attention的query,encoder的输出作为attention的key和value,得到attention的输出。再将该输出输入到FFN中,得到decoder一个layer的输出。最后再将decoder的输出分别输入到全连接和FFN中,分别预测类别和位置。考虑一个batch的输出,最后输出的shape为:\((num\_decoder\_layers, batch\_size, num\_query, 81)\)和\((num\_decoder\_layers, batch\_size, num\_query, 4)\),其中\(num\_query\)是每张图片的预测框数量,大于图中gt框的数量(该shape参考的是mmdetection的代码,官方代码可能不一样)。
计算loss
DETR的一个loss计算是一个主要的创新点,为了移除anchor,作者将预测框和gt框直接进行匹配。首先,作者设置了一个N,远大于图片的gt框数量,代表预测框的数量(也就是代码中的\(num\_query\)),然后将这N个预测框与gt框一对一进行匹配,由于是一对一匹配,而gt框的数量远小于N,因此需要将gt框集合大小扩充到N,扩充的都是\(\emptyset\),表示背景。然后需要找到一个匹配,使得匹配的cost最小,cost计算方式如图2所示:
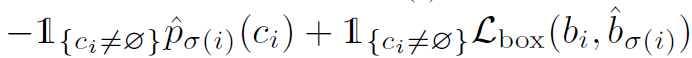
式子左边代表的是预测类别的cost,右边代表的是预测偏移的cost。其中 是指示函数,表示只考虑预测框不是背景的情况。其中
是指示函数,表示只考虑预测框不是背景的情况。其中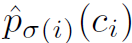 代表的是第i个预测框预测类别为\(c_i\)的概率,\(\sigma\)表示的是一个匹配排列方式,我们的目的就是要找到一个使得cost的最小的匹配排列方式\(\hat{\sigma}\)。需要注意的是,式子左边有一个负号,因为对于一个预测框最优的gt框是预测概率最大的,我们要使cost最小,就需要取相反数。式子右边的\(L_{box}\)的公式如图3所示:
代表的是第i个预测框预测类别为\(c_i\)的概率,\(\sigma\)表示的是一个匹配排列方式,我们的目的就是要找到一个使得cost的最小的匹配排列方式\(\hat{\sigma}\)。需要注意的是,式子左边有一个负号,因为对于一个预测框最优的gt框是预测概率最大的,我们要使cost最小,就需要取相反数。式子右边的\(L_{box}\)的公式如图3所示:
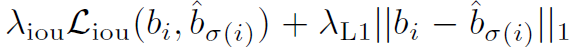
\(L_{box}\)由两部分组成,左半部分是IoU loss,右半部分是\(L_1\) loss。这是因为\(L_1\)loss对框的尺寸敏感,而IoU loss与尺寸无关,作者同时使用两者就是为了平衡大物体与小物体对loss的影响程度。
上面的解释可能不太清楚,下面结合代码的实现流程,再简要说明一下:
在mmdetection中,cost是用一个矩阵表示的,其维度为:\((num_query, num_gt)\),该cost是由三部分相加而成的,分别是:cls_cost,reg_cost和iou_cost,这三部分的维度也都是\((num_query,num_gt)\)。对于cls_cost,其表示分类的cost,其中\((i, j)\)位置的元素表示第\(i\)个预测框的类别是第\(j\)个gt框所属类别的概率的相反数(为什么是相反数在上面解释了);对于reg_cost,其表示\(L_1\) loss,其中\((i, j)\)位置的元素表示第\(i\)个预测框与第\(j\)个gt框的\(L_1\)距离,距离越小cost就越小;对于iou_cost,其表示IoU loss,其中\((i, j)\)位置的元素表示第\(i\)个预测框与第\(j\)个gt框的IoU大小的相反数。将这三个cost相加,就得到了最终的cost,然后使用匈牙利算法,就能找到每个预测框所对应cost最小的gt框,这就是匹配的全部过程。
将预测框与gt框进行匹配之后,就可以计算loss了,loss的公式如图4所示:

其实这个公式和cost很相似,就只是给分类的loss加了一个log。对于预测为背景的预测框,分类损失的值会除以10,并且不参与\(L_{box}\)的计算。
最后再总结一下预测和计算loss的过程,首先输入图片,输出预测。然后利用本次的预测值与gt框进行匹配,再利用匹配的结果计算loss,反向传播更新参数。也就是说,每次迭代预测与gt框的匹配结果基本上都不一样,这一点需要注意。
总结
DETR使用transformer作为目标检测模型的head网络,并在此基础上直接将预测框与gt框进行匹配,是一个真正意义上的anchor-free模型。如果不使用transformer作为head网络,直接像RetinaNet那样用几个简单的卷积层作为head网络,再使用预测框与gt框直接匹配,效果会如何呢?

