
【论文笔记】FCOS:通过像素级的预测实现目标检测
概述
与CornerNet类似,FCOS也是一个anchor-free的模型,它通过逐像素的方式实现目标检测,类似于语义分割,FCOS主要有以下优点:
- 将目标检测和其它FCN-sovable任务比如语义分割统一起来,因此可以很容易将FOCS移植到其它的任务中
- 实现了anchor-free和proposal-free,因此减少了锚框的超参数设计,避免了大量的IoU计算
- 可以将FOCS作为二阶段检测模型的RPN,并取得了更好的效果
- 相比于CornerNet为了将两个corner匹配在一起需要复杂的后处理,FCOS只需要使用NMS进行后处理
模型
虽然FCOS没有使用锚框,但它还是使用了锚框的思想,它将feature map的每个点看作是一个“锚点”,用这些锚点直接与gt框匹配。大致流程如下:对于feature map \(F_i\)的每个点\((x, y)\),先将其映射回原图片所在位置\((\lfloor \frac{s}{2} \rfloor + xs, \lfloor \frac{s}{2} \rfloor + ys)\),其中\(s\)是当前feature map的缩放倍数,\(xs\)和\(ys\)加上\(\lfloor \frac{s}{2} \rfloor\)的原因是为了将\((x, y)\)映射到原图片的感受野中心。映射成功后,判断该点是否在任何gt框内,若在记为正例,与对应的gt框进行匹配;否则记为负例,与背景进行匹配。对于分类的训练和anchor-based模型一样,对于回归的训练,通过计算该点到gt框的四个边界进行训练。最后的输出是一个80维向量和一个4维向量。
损失函数
训练的损失函数如图1所示:
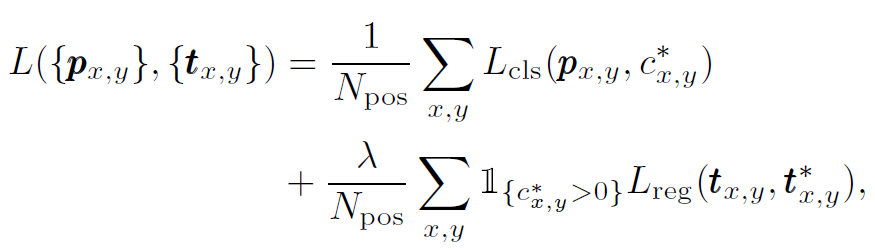
其中分类的损失函数使用focal loss,回归的损失函数使用IoU loss,另外需要注意的是,对于负例是不会计算回归损失的。
存在的问题与解决方案:
上述的模型看起来很不错,但主要存在以下三个问题:
问题1:feature map太大的缩放倍数导致召回率较低,这是由于缩放倍数太大,小物体的特征会丢失
问题2:两个重叠的gt框会导致锚点匹配的二义性,如图2所示:
问题3:通过一个锚点预测会出现大量的远离gt框中心点的低质量预测框

对于前两个问题,可以通过FPN来解决,论文使用了\(\{P_3, P_4, P_5, P_6, P_7\}\)五层feature map进行预测,缩放倍数分别为8,16,32,64,128,如图3所示:

其实只要使用了FPN,问题1就自动解决了,而对于问题2,作者还是借鉴了anchor_based的思想,用不同层级的feature map预测不同大小的gt框。他将每层的回归预测最大值\(max(l^*, t^*, r^*, b^*)\),限制在一定范围内。具体来说,将\(P_3\)的预测限制在\((0, 64)\)内;将\(P_4\)的预测限制在\((64, 128)\)内;将\(P_5\)的预测限制在\((128, 256)\)内;将\(P_6\)的预测限制在\((256, 512)\)内;将\(P_6\)的预测限制在\((512, inf)\)内。如果该层的一个点的回归预测最大值不满足该层的预测大小,则将该点记为负例。通过这种方式,就可以极大地减少二义性出现的次数。如果即使这样还是出现了二义性,作者直接选择了更小的gt框进行匹配。
对于第三个问题,作者添加了一个center-ness branch,如图3所示。center-ness的损失函数定义如图4所示:
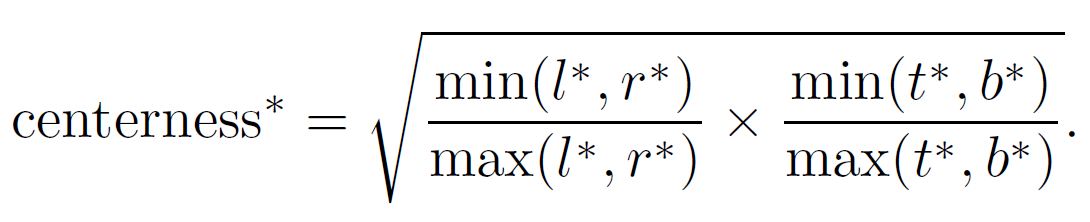
锚点越靠近gt框的中心,该值越接近0,否则越接近1。在训练阶段,直接将该函数加到原损失函数上;在测试阶段,最终的预测分数等于分类的分数乘以center-ness的值,这可以减少远离中心的点的权重,在经过NMS后处理之后就可以消除这些框。
总结
FCOS使用锚点代替了锚框,摆脱了锚框的超参数的设置问题,减少了锚框与gt框匹配时的计算量,并且可以很容易地移植到语义分割等任务中。

