
【论文笔记】CornerNet:预测左上角和右下角来实现目标检测
概述
CornerNet是一个anchor-free目标检测模型,至于为什么不使用anchor,作者提出了anchor-based模型的两个缺点:
- 每张图片需要大量的anchor,而只有少量的anchor与ground truth有较大的IoU(positive),这导致了positive和negative严重不平衡,减缓了训练速度
- anchor的使用会引入更多的超参数,需要手工决定anchor的数量,宽高比,大小,给调参侠带来了极大的负担
CornerNet主要有两个创新点:
- 没有使用anchor,通过预测左上角和右下角实现检测
- 提出了corner pooling,一种新的池化操作,能够帮助网络更好地定位corner
模型
CornerNet通过卷积网络预测两组heatmap,分别代表了不同类别的左上角位置和右下角位置。该网络对于每个corner也预测了一个embedding向量,使得属于同一个物体的embedding向量的距离很小。最后,为了使预测的包围框更精确,该网络还预测了一组偏移量。网络的大致结构如图1所示:
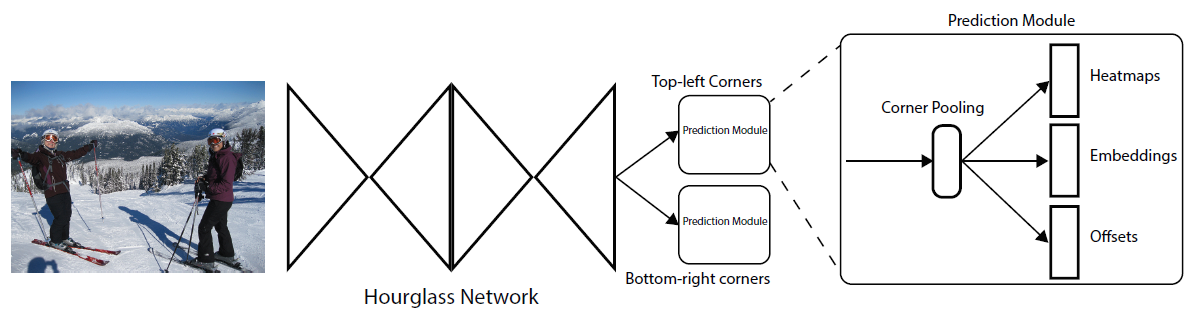
Detecting Corners
heatmap的形状是(N,C,H,W),N是批量大小,C是通道数(类别数,不包括背景),H和W是高与宽,heatmap每一个点的取值范围是[0,1],代表该点是corner的可能性大小,越靠近1,可能性越大。对于ground truth的heatmap,corner那一点的值为1,其余点的值为0,然而这样过于“陡峭”,论文中采取了一种更加平滑的方式,它根据某种方式(详细见论文)选择了一个半径,然后以corner点为圆心,其值为1,向外面逐渐减少值,超过半径的点还是为0。原论文使用了2D Gaussion来减少值:
其中σ取半径的三分之一,这样做的效果可以通过图2来说明:

在图2中,红色框为ground truth,绿色虚线框是预测框,橙色圆即为以corner为圆心画出的园。可以看到,这两个绿色的框虽然没有与红色框完全重合,但也是一个非常好的包围框,使用2D Gaussion来“放宽”对预测框的限制就可以保留这样的预测框,若不用2D Gaussion,那么只有完全重合的预测框才算好框,这样可能会不好训练(这是我的观点)。
为了让预测的heatmap收敛到ground truth的heatmap,论文使用了改进的focal loss,公式如下:
其中pcij指第c类,位置(i,j)的预测值,ycij指第c类,位置(i,j)的真值,通过(1−ycij)β实现了corner附近的点减少惩罚。
另外由于在网络中有下采样的操作,原图片坐标为(x,y)的点映射到了heatmap坐标为(⌊xn⌋,⌊yn⌋)的点,其中n是下采样的系数。当从heatmap映射回原图片时,会有精度损失,这对小物体来说影响很大。因此,CornerNet预测了offset用于在remapping之前微调corner的位置。ground truth的offset的如下所示:
论文使用了smooth L1 Loss更新预测的offset:
最后需要提一下的就是offset的形状:(N,2,H,W),两个通道分别预测x和y方向上的偏移。
Grouping Corners
由于CornerNet的左上角的点和右下角的点是在两个heatmap中分开预测的,我需要知道哪两个点是一组。因此,CornerNet预测了两组embedding,embedding之间距离小的两个点归为一个物体,embedding的形状是(N,1,H,W)。论文使用了两个loss来对corner进行分组,分别是"pull" loss和"push" loss,"pull" loss用于缩小属于同一物体两个corner的距离,"push" loss用于扩大属于不同物体的corner的距离,公式如下:
其中etk表示第k个物体左上角的embedding,ebk表示第k个物体右下角的embedding,而ek是前两者的平均值。
Corner Pooling
介绍完了CornerNet最末端的三个分支,现在开始说明这三个分支的上一层分支,也就是corner pooling。至于为什么提出corner pooling而不直接用max pooling等其它常用的pooling,主要原因是预测corner主要关注单一方向上的特征,而max pooling关注四周的小范围的特征,这对于预测corner来说可能不合适。对于左上角的corner,首先需要从左往右看,获取最大值,然后需要从上往下看,获取最大值;对于右上角的corner,首先需要从右往左看,获取最大值,然后从下往上看,获取最大值,最后再将两者加起来得到corner pooling的输出。可以使用图3来简要解释corner pooling为什么有用:

以左上角为例,从左往右看可以获得人头顶的特征,从上往下看可以获得人手的特征,右下角同理。
corner pooling的具体计算过程可以通过图4来说明:
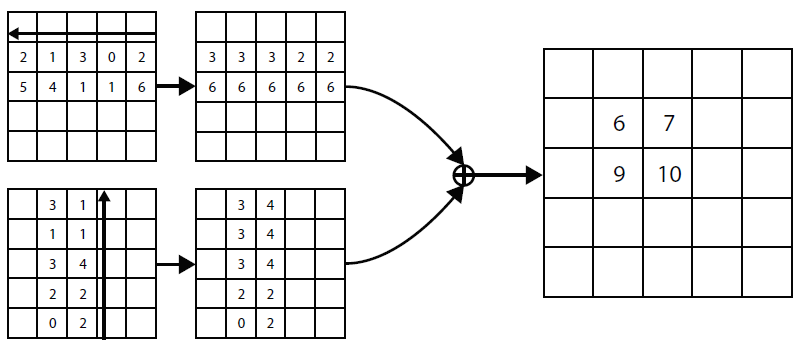
为了便于代码中实现,corner pooling的方向其实和上述描述的方向是反的。对于图4中第一行第一列的图片,我们执行left pooling,我们从右往左更新每个点的值,每次将该点的值更新为当前遇到的最大值,执行完后就得到了第一行第二列的图片;对于图4中第二行第二列的图片,我们执行top pooling,我们从下往上更新每个点的值,每次将该点的值更新为当前遇到的最大值,执行完后就得到了第二行第二列的图片。最后再将left pooling的结果和top pooling的结果加起来,得到top left pooling的结果。
总结
CornerNet是一个anchor-free的目标检测模型,通过预测两组corner实现检测,通过embedding对corner分组,通过offset进行微调,取得了很好的效果。


【推荐】中国电信天翼云云端翼购节,2核2G云服务器一口价38元/年
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 几种数据库优化技巧
· 聊一聊坑人的 C# MySql.Data SDK
· 使用 .NET Core 实现一个自定义日志记录器
· [杂谈]如何选择:Session 还是 JWT?
· 硬盘空间消失之谜:Linux 服务器存储排查与优化全过程
· 一个.NET开源、易于使用的屏幕录制工具
· 【经验】几种数据库优化技巧
· C#中 Task 结合 CancellationTokenSource的妙用
· Superpower:一个基于 C# 的文本解析工具开源项目
· 反微服务架构(A Macro Services Framework)