【论文笔记】FSAF:为目标框选择最好的特征层
Background
目标检测的一个关键问题是如何检测大小不同的物体,当前(指论文发表的时期)主流的模型都会使用多层特征图进行预测,其中浅层的特征图预测小物体,深层的特征图预测大物体。另外,还需要对图片每一个像素设置不同大小和宽高比的锚框,并根据IOU将锚框和目标框进行对应。不同大小的物体根据其与每个特征层的锚框的匹配程度,分配到特定的特征层学习。然而这种方式不能确定分配到的特征层是最好的。本论文的动机就是让目标框能够选择一个最好的特征层进行学习,因此没有使用锚框(锚框会限制特征层的选择)。
Feature Selective Anchor-Free Module
那么FSAF是如何选择最好的特征层的?对于每一个特征层,它首先是不用anchor去检测,然后看哪一层的loss最小,loss最小的那一层就是最好的,最后就可以选取该层的anchor-based branch去检测。模型的大致结构如图1所示:
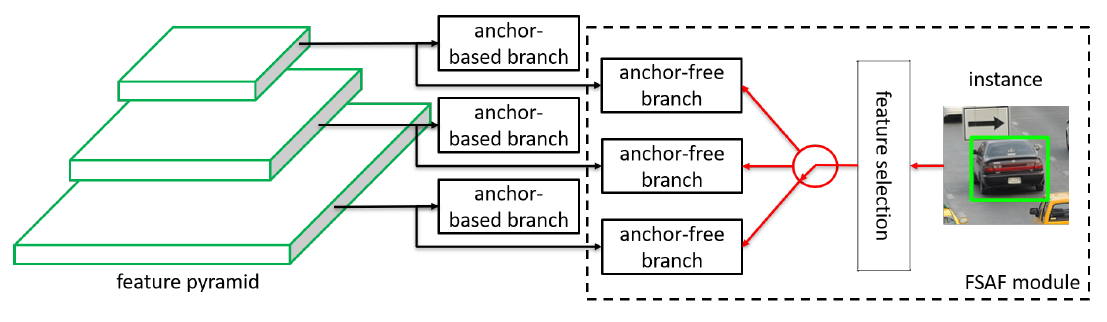
可以看到,FSAF只是在原网络的每层特征图加了一个anchor-free branch,因此非常简单,那么这个anchor-free branch是如何不使用锚框进行预测的?论文以嵌入到RetinaNet的FSAF作出了解释,如图2所示:
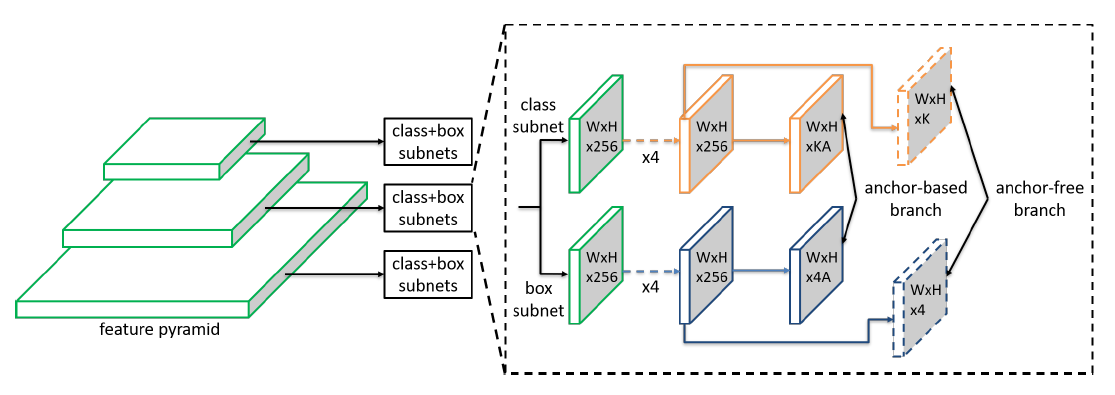
可以看到,FSAF对每个特征层只添加了额外两个卷积层,带来的性能消耗很小。这两个卷积层输出的特征图形状分别是(W, H, K)和(W, H, 4),其中K是物体的类别数。对于(W, H, K),其每个像素代表了当前位置属于对应类别物体的概率;对于(W, H, 4),将用于预测包围框坐标的偏移。
原论文定义了以下变量用于监督训练:
- object instance:\(b = [x, y, w, h]\)
- projected box:\(b_p^l = [x_p^l, y_p^l, w_p^l, h_p^l]\),投影框,代表的是\(b\)投影到第\(l\)层特征图的包围框,其中\(b_p^l=b/2^l\)
- effective box:\(b_e^l = [x_e^l, y_e^l, w_e^l, h_e^l]\),有效框,代表的是投影框的有效区域,其中\(x_e^l = x_p^l\),\(y_e^l = y_p^l\),\(w_e^l = \epsilon_e w_p^l\),\(h_e^l = \epsilon_e h_p^l\),论文中\(\epsilon_e = 0.2\)
- ignoring box:\(b_i^l = [x_i^l, y_i^l, w_i^l, h_i^l]\),忽视框,代表的是投影框的无效区域,其中\(x_i^l = x_p^l\),\(y_i^l = y_p^l\),\(w_i^l = \epsilon_e w_p^l\),\(h_i^l = \epsilon_e h_p^l\),论文中\(\epsilon_i = 0.5\)
对于分类,第K类的instance将会从三个方面影响第K个特征图:
- 有效框区域是positive区域,填充1,表示instance存在
- 忽视框区域减去有效框区域是igoring区域,这部分区域不会参与反向传播
- 剩余的区域是negative区域,填充0,表示instance不存在
分类损失使用Focal loss,一个图片的anchor-free branch的总分类损失等于所有未忽视区域的focal loss的总和,并通过除以所有有效区域的像素个数来标准化。
对于回归,instance只会影响有效区域内的像素,将特征图在点\((i, j)\)的输出记为\(d_{i,j} = [d_{i,j}^t, d_{i,j}^l, d_{i,j}^b, d_{i,j}^r]\),表示点\((i, j)\)到包围框各个边的距离。回归损失使用IoU loss,一个图片的anchor-free branch的总回归损失等于所有有效区域的IoU loss的均值。
监督训练如图3所示:

通过这种方式,在每个特征层都计算一次分类损失和回归损失,总损失最小的特征层即为最好的特征层。
总结
论文提出了一个更好的解决物体尺寸问题的方法,可以很容易地添加到其它的模型中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号