

HBase非原理性浅析
工作中我因为任务需要而接触到了大数据产品,已经不记得当时查看的表名叫什么名字了,但是该表的大小让我着实吃了一惊,多达数PB。虽然对于大数据的概念早已不陌生,但是对于什么是大数据,大数据到底有多大 还是没有很好的理解和体会。直到设身处地的观察到大数据在公司日常的运用,我才明白什么是大数据以及大数据是怎么被运用到公司业务中的。当时我脑海中有很多疑惑:这么多数据是怎么存储下来的?这些数据都是些什么数据?我们用这些数据干什么呢?这里面很多疑惑我至今还是没有完全解开,我相信随着逐步学习的过程,我会得到我想要的答案,同时这些疑惑的解开也会给我带来更多的疑惑,从而开阔我的视野。
Google的三驾马车
大数据现有生态中很多解决方案或多或少都有Google三驾马车的影子,因此了解Google三驾马车可能能概括部分大数据产品。
中国有句谚语叫“三个臭皮匠,顶过一个诸葛亮。”,这句谚语重点在突出集体的力量,能很好的表达Google三驾马车的朴素思想。
随着信息化进程的加快,人类在近几十年积累的数据呈现爆炸式增长。因此数据的存储需要越来越多的存储空间,计算需要越来越强的计算力。芯片和存储技术早些年还可以通过类似纳米工艺的改进等技术来提升性能,但是边际收益总是递减的,特别是大数据来临的今天,我们已经等不及单块芯片或者磁盘技术的提升。因此Google工程师可能是被逼无奈,用前面提到的集体力量大于个人的朴素思想,将大量的廉价的、小型的电脑通过网络组织起来,将大量的数据和计算任务分配给这些机器来处理,最后利用这些机器完成了大数据的存储和计算,这些内容组成了Google的三驾马车。
三驾马车的内容如下:
- GFS Google File System
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,提供容错功能。 - MapReduce
Mapreduce是针对分布式并行计算的一套编程模型。 - BigTable
就像文件系统需要数据库来存储结构化数据一样,GFS也需要Bigtable来存储结构化数据,因此Bigtable是一个基于GFS的存储大量结构化数据的类数据库。
不难看出,三驾马车要解决的问题大部分属于分布式系统要解决的问题,因此分布式系统的一些理论是是马车跑起来的理论保障。
相对应这三驾马车,开源的Hadoop生态都有对应的产品,HDFS对标GFS,Hadoop对标MaoReduce,HBase对标BigTable。因此Hadoop基本就代表了大数据的开源解决方案。而接下来,将主要对HBase的了解和学习做一个非原理性的总结。
HBase与大数据
前面提到了HBase是对标BigTable的开源产品,主要解决海量结构化数据的存储。简单地,我们可以认为 HBase 是一种类似于数据库的存储层,也就是说 HBase 适用于结构化的存储。类似于数据库一样,HBase存储的数据还是以文件的形式存在于磁盘上,因此就需要一个文件系统来支持,这个文件系统就是对标GFS的HDFS文件系统。
除了HBase,Hadoop生态里还有一个Hive。HBase和Hive的区别和联系,我偷个懒,引用别人的一段对比:
Hive 适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive 不应该用来进行实时的查询(Hive 的设计目的,也不是支持实时的查询)。因为它需要很长时间才可以返回结果;HBase 则非常适合用来进行大数据的实时查询,例如 Facebook 用 HBase 进行消息和实时的分析。对于 Hive 和 HBase 的部署来说,也有一些区别,Hive 一般只要有 Hadoop 便可以工作。而 HBase 则还需要 Zookeeper 的帮助(Zookeeper,是一个用来进行分布式协调的服务,这些服务包括配置服务,维护元信息和命名空间服务)。再而,HBase 本身只提供了 Java 的 API 接口,并不直接支持 SQL 的语句查询,而 Hive 则可以直接使用 HQL(一种类 SQL 语言)。如果想要在 HBase 上使用 SQL,则需要联合使用 Apache Phonenix,或者联合使用 Hive 和 HBase。但是和上面提到的一样,如果集成使用 Hive 查询 HBase 的数据,则无法绕过 MapReduce,那么实时性还是有一定的损失。Phoenix 加 HBase 的组合则不经过 MapReduce 的框架,因此当使用 Phoneix 加 HBase 的组成,实时性上会优于 Hive 加 HBase 的组合,我们后续也会示例性介绍如何使用两者。最后我们再提下 Hive 和 HBase 所使用的存储层,默认情况下 Hive 和 HBase 的存储层都是 HDFS。但是 HBase 在一些特殊的情况下也可以直接使用本机的文件系统。例如 Ambari 中的 AMS 服务直接在本地文件系统上运行 HBase。
HBase作为一个分布式的列存储数据库,准确的来说不算一个数据库。和传统的RDBS来对比,HBase有着许多不同点。
- 存储的数据量,HBase存储的数据通常是PB级的,而传统的RDBS则一般是GB、TB;
- 数据的组织方式,HBase是稀疏的,多维的Map结构,而RDBS是按行列组织的;
- 事务的支持,HBase支持事务的能力很弱,支持行级别的事务,而RDBS是完全支持各种粒度事务;
- 查询语言:HBase支持Java API查询语言(HBase可以结合其他产品实现SQL查询),而RDBS这是SQL;
- 索引:HBase支持row-key,而RDBS支持一级索引,二级索引等;
- 吞吐量:HBase的查询通常是百万QPS,而RDBS则仅有数千QPS;
- 容错性:HBase通过软件架构来实现容错,而RDBS一般需要额外的硬件来辅助;
另外,HBase由于是基于HDFS系统,水平扩展能力几乎是线性的,而RDBS由于要保持数据的完整性,其扩展能力通常是增加单个数据库服务器的性能,而这个扩展能力很容易到达天花板。从5台机器加到10台机器,HBase能让存储和处理能力实现翻倍。
HBase逻辑和物理存储结构
逻辑视角
HBase除了前面的能基于HDFS文件系统,还能支持本地文件系统,也就是单机版HBase,不过这失去了HBase的作为分布式列存储的意义,仅仅用于测试把玩HBase。
HBase对于一张多列的二维表,会把多列分组,每组被称为Column Family简称CF,但是为了具体标识每列,需要另一个叫Qualifier的概念,也就是说:CF:Qualifier标识一个具体的列。同样的对于每一行,会有一个Row-Key标识每一行,那么对于一个四元组<Row-Key, CF, Qualifier,TimeStamp>,就会确定一个Cell,这个Cell里面包含实际的Value,附随一个TimeStamp,TimeStamp的作用是该Value的版本号。
下图为HBase一个表的逻辑结构:
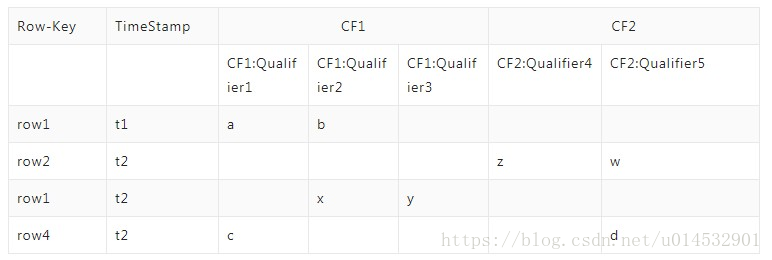
总结一下,有如下几个概念:
- Row-Key
- Column Qualifier
- Column 由 Column:Qualifier组成;
- Cell 由
<Row-key, Column, Qualifier, TimeStamp>组成; - TimeStamp:通常为每个Cell被写入的时间戳,表示对应Cell的Value的版本号;
- Value
所以从上图可以看出,HBase逻辑上可以看做是一个多维的稀疏的Map。以上是逻辑视角,那么物理上,HBase的表是如何存储的呢?
物理视角
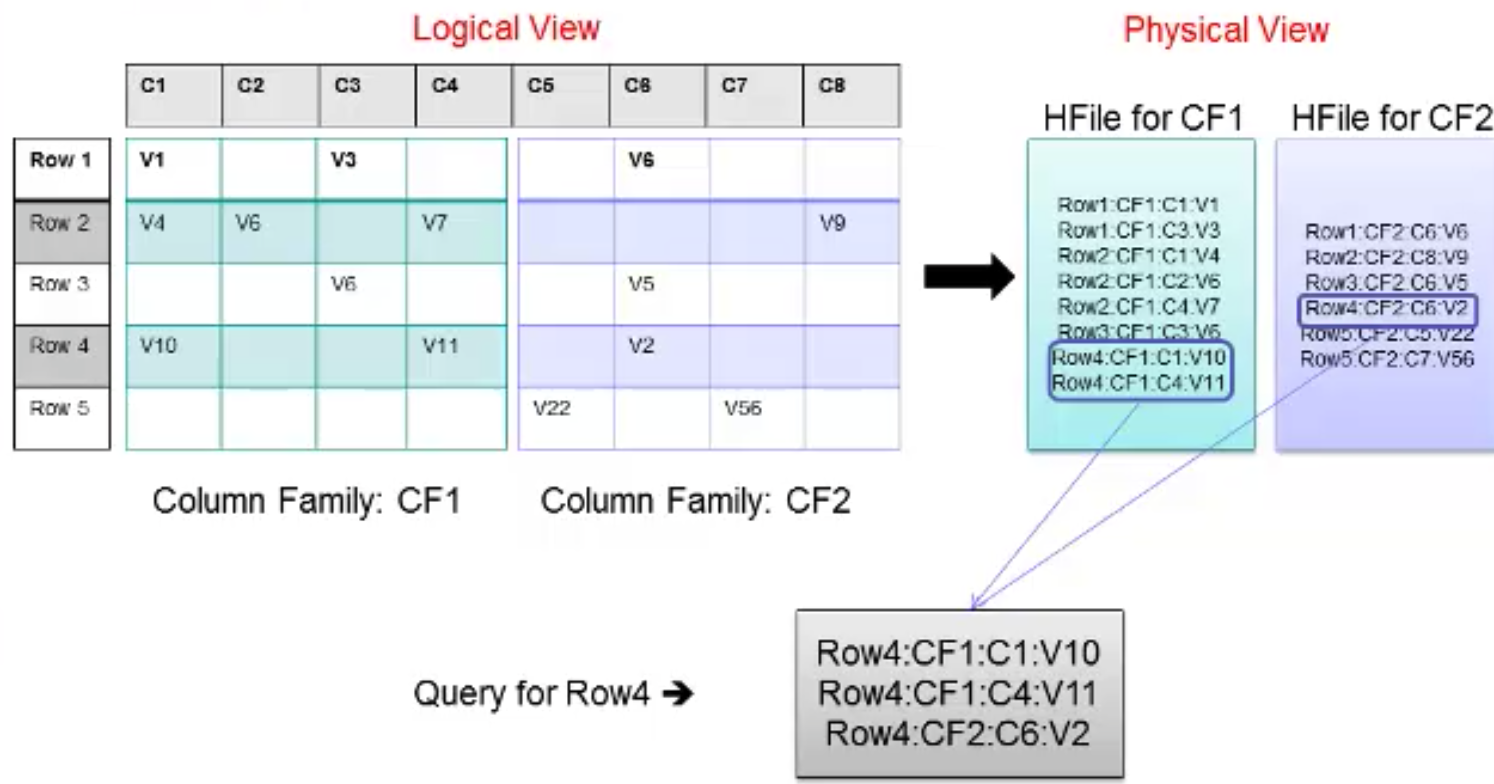
最开始提到HBase是一个海量数据的列存储数据库,实际上HBase也是按照CF将数据存储到物理磁盘。
HBase的物理视角下,主要有以下几个概念,其他门的层级关系如下所示:
Table (HBase table)
Region (Regions for the table)
Store (Store per ColumnFamily for each Region for the table)
MemStore (MemStore for each Store for each Region for the table)
StoreFile (StoreFiles for each Store for each Region for the table)
Block (Blocks within a StoreFile within a Store for each Region for the table)
一个HBase表由很多Region负责存储,每个Region包含很多Store,一个Store负责存储一个CF的数据。每一个Store会存在一个MemStore,数据会先写入到MemStore,然后Size达到阈值的时候,会Dump到磁盘上,这样做是为了减少磁盘的IO。数据写入的可靠性保证是通过先写HLog日志,再写到MemStore中,类似于数据库中先写日志,再提交事务。一个Store包含0或多个StoreFile(HFile), StoreFile就是对应的实际的存储文件,一个StoreFile包含多个Block,StoreFile的可靠性和容错性就交由HDFS文件系统来保证。
从物理视角来看,Region是HBase Table可用性和分布式的基本单元。
逻辑视角和物理视角的对应关系,有如下示意图:
HBase架构OverView
HBase包含如下几个主要模块:
- Master:协调各个Region Server完成存储请求,也负责分配Region给不同的Region Server;
- Region Server:管理多个Region,每个Region存储着表格。Client直接和Region Server通信,region负责数据的实际读写;当表的列特别多的时候,不同的Column Family CF会存储在不同的region;因此Region是HBase最小的可用性和分布式的基本单位。
- Zookeeper:保证Master的可用性,提供Region Sever的注册和发现功能;
下图是HBase的架构示意图:
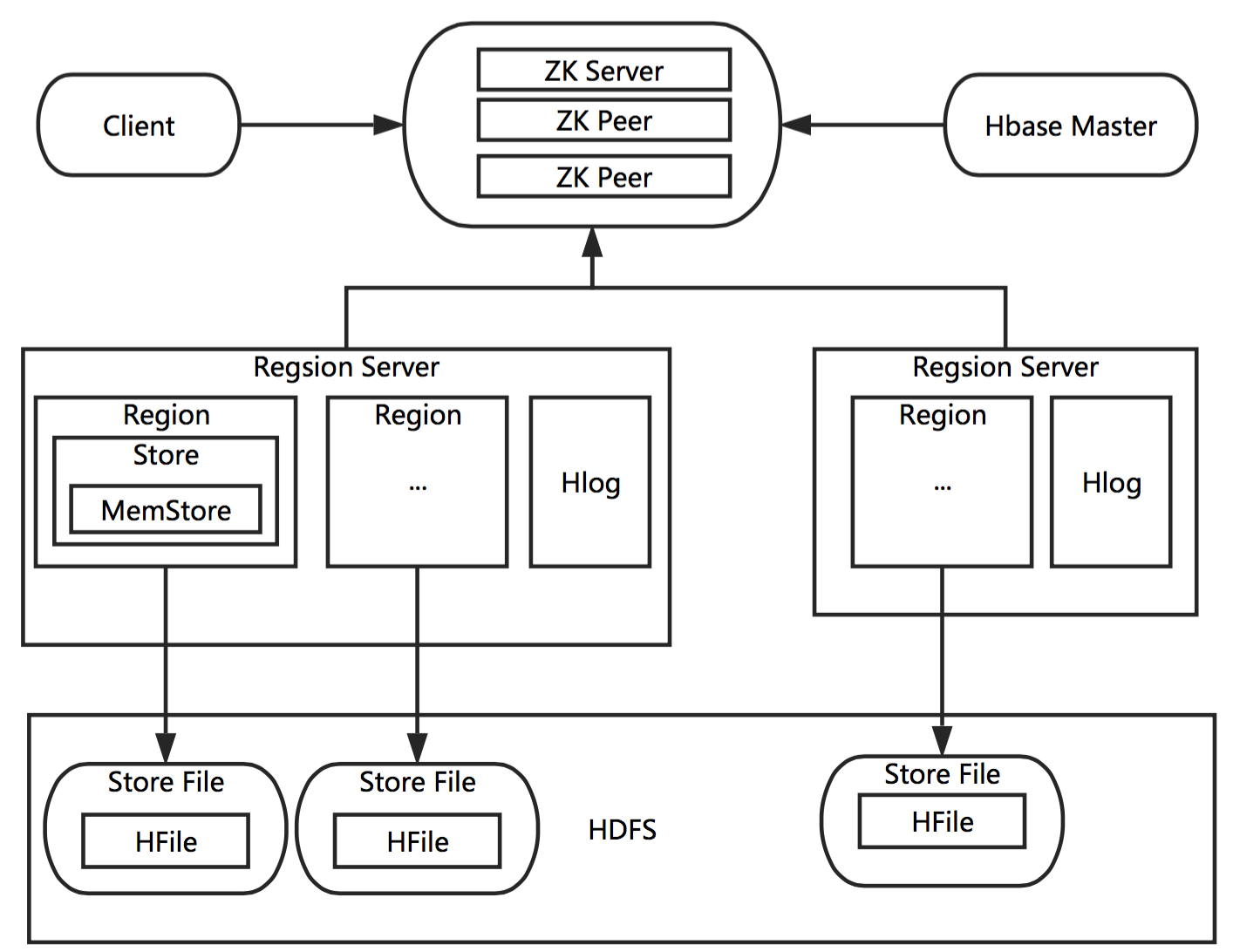
当客户端访问HBase时,会通过Zookeeper找到对应的Region Sever,并访问到对应的Region。Region是HBase可用性和并行化的基本单元,包含一个MemStore,0或多个StoreFile。
Reference
[1]. HBase 深入浅出
[2]. 分布式系统漫谈一Google三驾马车: GFS,mapreduce,Bigtable
[3]. Data Models

 浙公网安备 33010602011771号
浙公网安备 33010602011771号