
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 在Github上学会fork仓库、学会git的使用、学习python的统计和分析方法 |
| 学号 | 051803216 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 50 | 90 |
| Estimate | 估计这个任务需要多少时间 | 40 | 60 |
| Development | 开发 | 0 | 0 |
| Analysis | 需求分析 (包括学习新技术) | 90 | 100 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 10 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| Design | 具体设计 | 0 | 0 |
| Coding | 具体编码 | 0 | 0 |
| Code Review | 代码复审 | ||
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 20 | 30 |
| Test Report | 测试报告 | 10 | 20 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 0 | 0 |
二、解题思路
刚看到题目就傻掉了,然后第一个想法就是先看懂助教给的实例,于是我踏上了自学python的路。花了两天把python大概学习之后,
我发现还是看不懂助教的代码。于是就把代码一行行去搜索,学习OS,argparse,json模块,还有相关的函数,最后发现自己用C++
写不出来,就只能做一个对助教代码的分析了。对不起了....
三、流程图
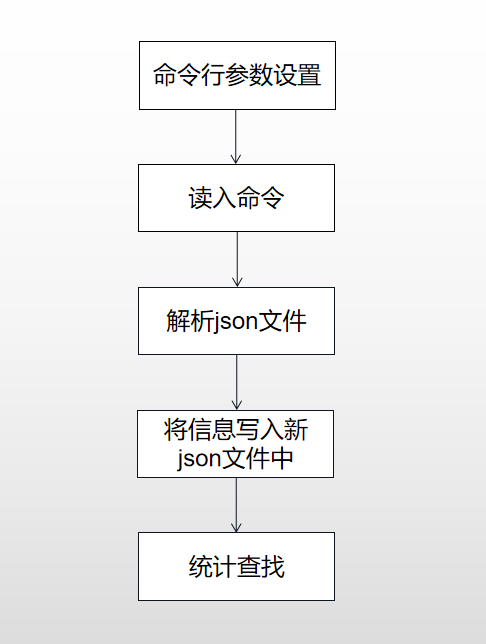
四、代码说明
json文件的读取
class Data:
def __init__(self, dict_address: int = None, reload: int = 0):
if reload == 1:
self.__init(dict_address)
if dict_address is None and not os.path.exists('1.json') and not os.path.exists('2.json') and not os.path.exists('3.json'): #判断括号里的文件是否存在的意思,括号内的可以是文件路径
raise RuntimeError('error: init failed')
x = open('1.json', 'r', encoding='utf-8').read() #open(路径+文件名, 读写模式, 编码) ‘r’为只读模式
self.__4Events4PerP = json.loads(x) #用户事件数量
x = open('2.json', 'r', encoding='utf-8').read()
self.__4Events4PerR = json.loads(x) #项目事件数量
x = open('3.json', 'r', encoding='utf-8').read()
self.__4Events4PerPPerR = json.loads(x) #用户项目事件数量
原json文件的解析
def __init(self, dict_address: str):
json_list = []
for root, dic, files in os.walk(dict_address): #遍历获取文件,遍历文件夹、根目录、目录文件夹、目录里的文件
for f in files:
if f[-5:] == '.json':
json_path = f #记录下后缀名为json的地址
x = open(dict_address+'\\'+json_path,
'r', encoding='utf-8').read() #打开.json文件,‘r’为只读,readline返回其中一行元素
str_list = [_x for _x in x.split('\n') if len(_x) > 0] #split()对字符串进行分割
for i, _str in enumerate(str_list): #enumerate函数将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
try:
json_list.append(json.loads(_str)) #append() 方法用于在列表末尾添加新的对象,将文件数据由json格式转化为python字典。
except:
pass
records = self.__listOfNestedDict2ListOfDict(json_list)
在新json文件中写入需要的关键字
for i in records:
if not self.__4Events4PerP.get(i['actor__login'], 0): #Python 字典 get() 函数返回指定键的值,如果键不在字典中返回默认值,所以0为默认值,用来判断是否有'actor__login'。
self.__4Events4PerP.update({i['actor__login']: {}}) #update() 方法用于更新字典中的键/值对,可以修改存在的键对应的值,也可以添加新的键/值对到字典中。没有'actor__login'则添加。
self.__4Events4PerPPerR.update({i['actor__login']: {}})
self.__4Events4PerP[i['actor__login']][i['type']
] = self.__4Events4PerP[i['actor__login']].get(i['type'], 0)+1 # 获取到相应type的值+1,type没有为0
if not self.__4Events4PerR.get(i['repo__name'], 0):
self.__4Events4PerR.update({i['repo__name']: {}})
self.__4Events4PerR[i['repo__name']][i['type']
] = self.__4Events4PerR[i['repo__name']].get(i['type'], 0)+1
if not self.__4Events4PerPPerR[i['actor__login']].get(i['repo__name'], 0):
self.__4Events4PerPPerR[i['actor__login']].update({i['repo__name']: {}})
self.__4Events4PerPPerR[i['actor__login']][i['repo__name']][i['type']
] = self.__4Events4PerPPerR[i['actor__login']][i['repo__name']].get(i['type'], 0)+1
with open('1.json', 'w', encoding='utf-8') as f:
json.dump(self.__4Events4PerP,f) #将序列化的str保存到文件中,存入个人事件。
with open('2.json', 'w', encoding='utf-8') as f:
json.dump(self.__4Events4PerR,f) #存入项目事件。
with open('3.json', 'w', encoding='utf-8') as f:
json.dump(self.__4Events4PerPPerR,f) #存入每人每项目事件。
查询统计
class Run:
def __init__(self):
self.parser = argparse.ArgumentParser() #创建一个 ArgumentParser 对象
self.data = None
self.argInit()
print(self.analyse())
def argInit(self):
self.parser.add_argument('-i', '--init') #添加参数
self.parser.add_argument('-u', '--user')
self.parser.add_argument('-r', '--repo')
self.parser.add_argument('-e', '--event')
def analyse(self):
if self.parser.parse_args().init: #解析参数
self.data = Data(self.parser.parse_args().init, 1)
return 0
else:
if self.data is None:
self.data = Data()
if self.parser.parse_args().event:
if self.parser.parse_args().user:
if self.parser.parse_args().repo:
res = self.data.getEventsUsersAndRepos(
self.parser.parse_args().user, self.parser.parse_args().repo, self.parser.parse_args().event) # 查询某用户在某项目某事件
else:
res = self.data.getEventsUsers(
self.parser.parse_args().user, self.parser.parse_args().event) #查询某用户某事件
elif self.parser.parse_args().repo:
res = self.data.getEventsRepos(
self.parser.parse_args().reop, self.parser.parse_args().event) # 查询某项目某事件
else:
raise RuntimeError('error: argument -l or -c are required')
else:
raise RuntimeError('error: argument -e is required')
return res
四、测试
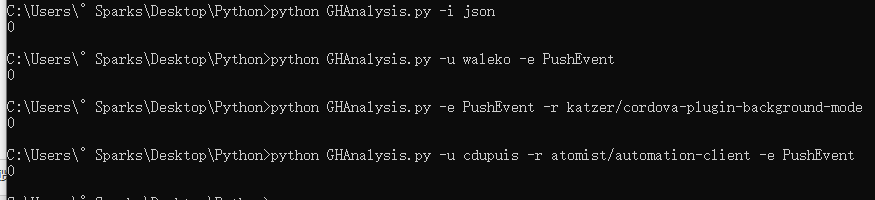
感觉结果有点奇怪。。但是不知道哪里出了问题。
五、单元测试覆盖率优化和性能测试
六、代码规范链接
https://github.com/Sparks-fzu/2020-second-work/tree/master
七、个人总结
这次的作业完成得不是很理想。首先就是做的太墨迹了,时间分配并不合理。这次作业让我意识到自己与其他大佬
们的差距,以前都只停留在作业层次上的完成,没有再去课外提升自己的能力,对于助教给的代码我都一知半解,不
有一个比较全面的理解,还是一行行去百度,去看模块和函数的大概内容,所以也就没有自己能够独立编写甚至改进
这个代码的能力。不过在这次的学习中,我对python和json有了一个大概的认识,也知道了github如何fork一个自
己的仓库,然后也通过csdn知道了Git的使用方法,对本地仓库和远程仓库的连接有了一个大概的理解。最后我也知
道了自己在后面的学习中应该用什么样的态度去面对,希望能在下次的作业中做得更好。

