web自动化5-补充:xpath定位/CSS定位
补充:xpath定位
(1)逻辑匹配
1.xpath有一个比较强的功能,可以多个属性逻辑运算,支持与(and)、或(or)、非(not)
2.and,同时满足两个属性

(2)模糊匹配,基本都可以定位到
比如百度页面的超链接“hao123”,在上面写了可以通过by_link,也可以通过by_partial_link,模糊匹配定位到。当然xpath也可以有同样的功能,并且更为强大。

补充:css定位
(1)css:属性定位
1.通过元素的id、class、标签这三个常规属性直接定位到
2.如下是小红书搜索框的的html代码:

3.css用#号表示id属性,如:#xxx
有id的时候就用#id即可,无id就换其他的
4.css用.表示class属性,如:.search-input

(2)css:其它属性
写法是"[属性名=‘对应的名称’]"
比如type属性,对应的是text,即,有name属性的时候,也可以用name

1.还可以通过标签与属性的组合来定位元素

#标签是input,class属性的元素,.号表示的是class属性

#标签是input,id是kw的元素

#标签是input,其他属性的组合,这里的id可以更换成name,class等等
(3)css:层级关系
如xpath://form[@id='form']/span/input和//form[@class='fm']/span/input也可以用css实现
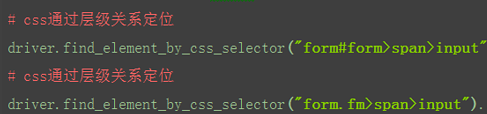
(4)css:索引
有很多一样的标签,到底选择哪一个,那就要根据索引来操作

2.css也可以通过索引option:nth-child(1)来定位子元素,这点与xpath写法用很大差异,其实很好理解,直接翻译过来就是第几个小孩

(5)css:逻辑运算
1.有的时候会遇到单个属性都不是唯一的,但是两个属性是唯一的,那么就需要同时匹配两个属性,这里跟xpath不一样,无需写and关键字

(6)css:模糊匹配
[name^="def"] 选择name 属性值以 "def" 开头的所有元素
[name$="def"] 选择name 属性值以 "def" 结尾的所有元素
[name*="def"] 选择name 属性值中包含子串 "def" 的所有元素
本文来自博客园,作者:小排顾,转载请注明原文链接:https://www.cnblogs.com/SparkProgram/p/17377347.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号