
go从零开始1 [map]
go中的数据类型大致分为一下几种:
基础类型:
布尔类型:bool
整型:int, int8, int16, int32, int64, uint, uint8, uint16, uint32, uint64, uintptr, byte(同uint)
浮点型:float32, float64
复数:complex64, complex128
字符:rune(int32的别名)
错误类型:err
复杂类型:指针,切片,数组,接口,结构,通道,字典(map),函数
map的定义和初始化
# 声明map 变量
var mapName map[string]int
mapName1 := make(map[string]int)
map的key必须为可比较的类型
何为可比较的类型呢? 也就是说可以使用 == 进行逻辑判断的即为可对比类型,复杂类型中的map,切片和函数不可以进行比较。struct中如果包含了上述三种类型,就不可比较了。
map是并发不安全的
为了更好的理解map是并发不安全的,我们先看一下map是如何实现。
go中的map是采取hash table(哈希表)进行实现的,通过hmap和bmap结构。
type hmap struct {
# 记录当前map中键值对的数量,也就是有多少个元素
count int
flag uint8 //标记状态
B uint8 //B决定hash桶的数量 2^B个桶
noverflow uint16 //溢出桶的大致数量
hash0 uint32 //哈希种子
# 指向桶的数组,桶有2^B个,每个元素是bmap,如果map中没有数据,buckets为nil
buckets unsafe.Pointer
# 指向旧桶的指针,map扩容的时候用到
oldbuckets unsafe.Pointer
#标识扩容进度,小于该值的buckets表示迁移完成
nevacuate uintptr
# 为了降低QG扫描设计
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextoverflow *[]*bmap // 指向预分配的溢出桶的位置
}
type bmap struct {
// tophash是一个[8]uint8数组,存储该桶中每个键的哈希值的最高8位信息,因为该数组大小为8
// 所以也就是说每个桶能够存储的键数量有8个,注意该结构在编译期间会动态添加字段。添加字段存储
// 有8个key和8个value,还有一个*overflow字段。
tophash [bucketCnt]uint8
}
上面是静态bmap的结构,编译期间会动态的增加8个key和8个val
// 动态创建bmap
func bmap(t *types.Type) *types.Type {
...
field := make([]*types.Field, 0, 5)
// The first field is: uint8 topbits[BUCKETSIZE].
// 第一个字段是[8]uint8
arr := types.NewArray(types.Types[TUINT8], BUCKETSIZE)
field = append(field, makefield("topbits", arr))
// 添加8个key
arr = types.NewArray(keytype, BUCKETSIZE)
arr.SetNoalg(true)
keys := makefield("keys", arr)
field = append(field, keys)
// 添加8个value
arr = types.NewArray(elemtype, BUCKETSIZE)
arr.SetNoalg(true)
elems := makefield("elems", arr)
field = append(field, elems)
...
return bucket
}
综上,可以得到bucket(桶)的内存结构,这里画了一张bucket的结构图,方便读者理解,图中每个tophash称之为一个槽位,一共有8个槽位。每个槽位对应了一个存放key和value的位置,每个tophash、key和value占用的内存空间都是固定的,所以根据tophash结合偏移量很容易得到key和value的位置。

内部结构已经理解的差不多,当我们查找,赋值是怎么做的呢?
在分析查找实现前,我们先来看一个key的定位问题,就是给一个key怎么确定它在哪个桶的哪位槽位。理解了这个,下面的mapaccess1就很好理解了。假设hmap中的B为5,即map的桶有(2^5 = 32)个,对添加的key通过哈希函数计算后得到的值为64bit数据。现在有一个键值对{k,v}被添加到map中,对k计算出来的哈希值为hash(k),现在如果是你设计一个方法将hash(k)放在哪个桶,你会采用什么方法?对hash(k)取模就可以,非常棒。官方作者就是这么实现的,落在桶的公式为hash(k)%32=hash(k)%( 2^B ), 就是将对key计算出来的哈希值模与桶的数量,得到的余数肯定是在(0,2^B)中。实现的时候,作者并没有采用%运算,而是更巧妙的对二进制进行&运算。bucketMask计算的是通的掩码,它的返回值是 2^B-1, 对 hash(k) &bucketMask实际就是hash(k)%( 2^B ). 那落在桶内的哪个槽位是怎么确定的呢?因为桶内的槽位有8个,取哈希值的最高8bit对应的值放在tophash中,8bit的最大值为255,tophash是uint8类型是完全可用放入的。具体放在哪个槽位,是根据从小到大顺序。先放到槽位0即tophash0的位置,如果该位置已放有数据,就继续看一下个位置tophash1,如果tophahs0到tophash7都有数据了,那说明当前桶已经满了,继续看它的溢出桶即overflow指向的桶。这里注意一点,怎么判断一个槽位是否被占用。采用的方法是判断tophash值,tophash值的0到4是状态标志。最小有效的值为高8bit的值+5.具体状态标志见下面的tophash值特殊含义。
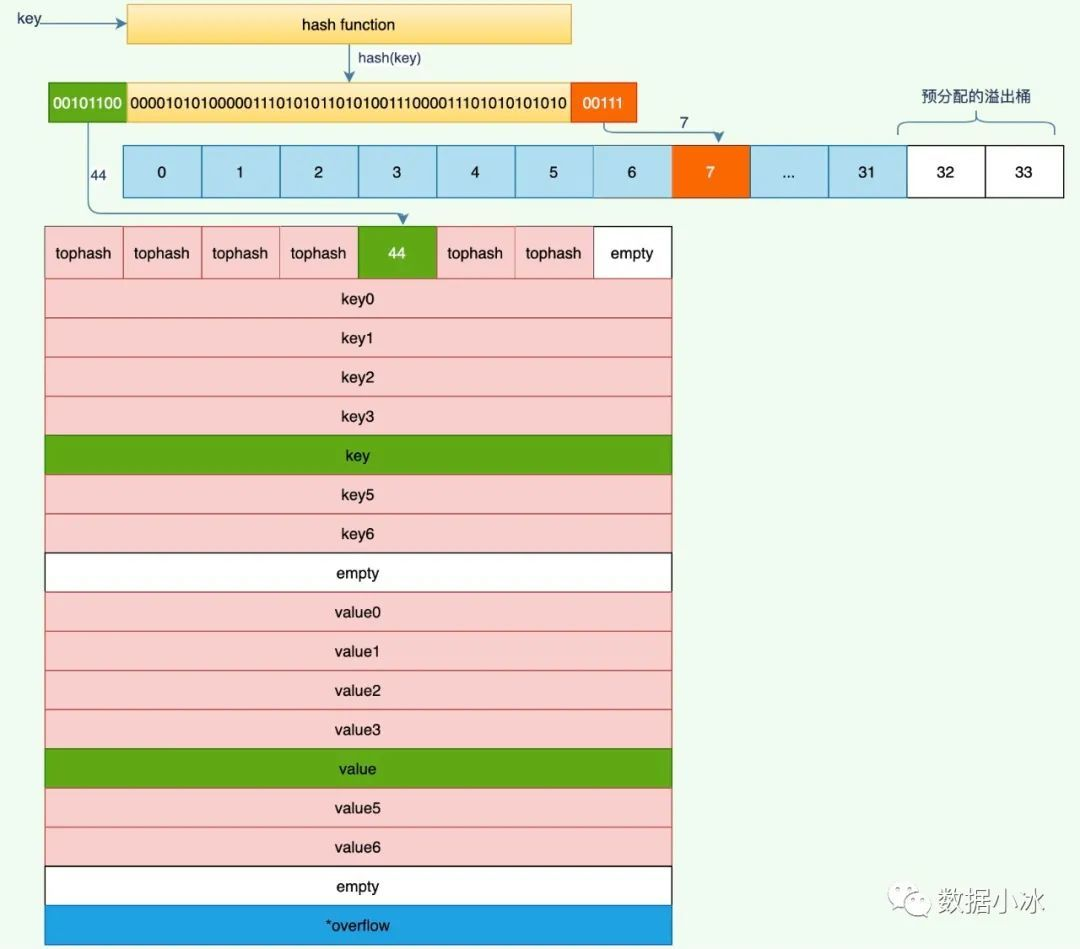
也就是说多进程在修改时,会同时修改同一份数据。所以说是线程不安全的。
如何实现线程安全呢?
1.在使用map时进行加锁操作
2.使用sync.map来操作
sync.map 是如何实现线程安全的呢?
要想理解透彻,必须先理解sync.map的底层结构是什么
type Map struct {
mu Mutex //互斥锁
read atomic.Value // 指向实际结构 readonly
dirty map[interface{}]*entry //dirty map,对此操作需要加mu锁
misses int // 从read map中获取值,未命中的次数
}
type readonly struct {
m map[interface{}]*entry //read map, 该结构使用原子操作
amended bool //为true 代表dirty map中包含read map不包含的数据
}
type extry struct {
# 代表执行实际值的指针
# p的取值有三种 1. p=nil 2. p=expunged(理解为 一个不可达的地址) 3. p = *interface{} (存在map中的一个值的地址)。
# 看到这里是不是有点懵,what?为啥p有那么多值,其实这是为map设置k-v对准备的,代表了value在不同流程下状态
p unsafe.Pointer // *interface{}
}
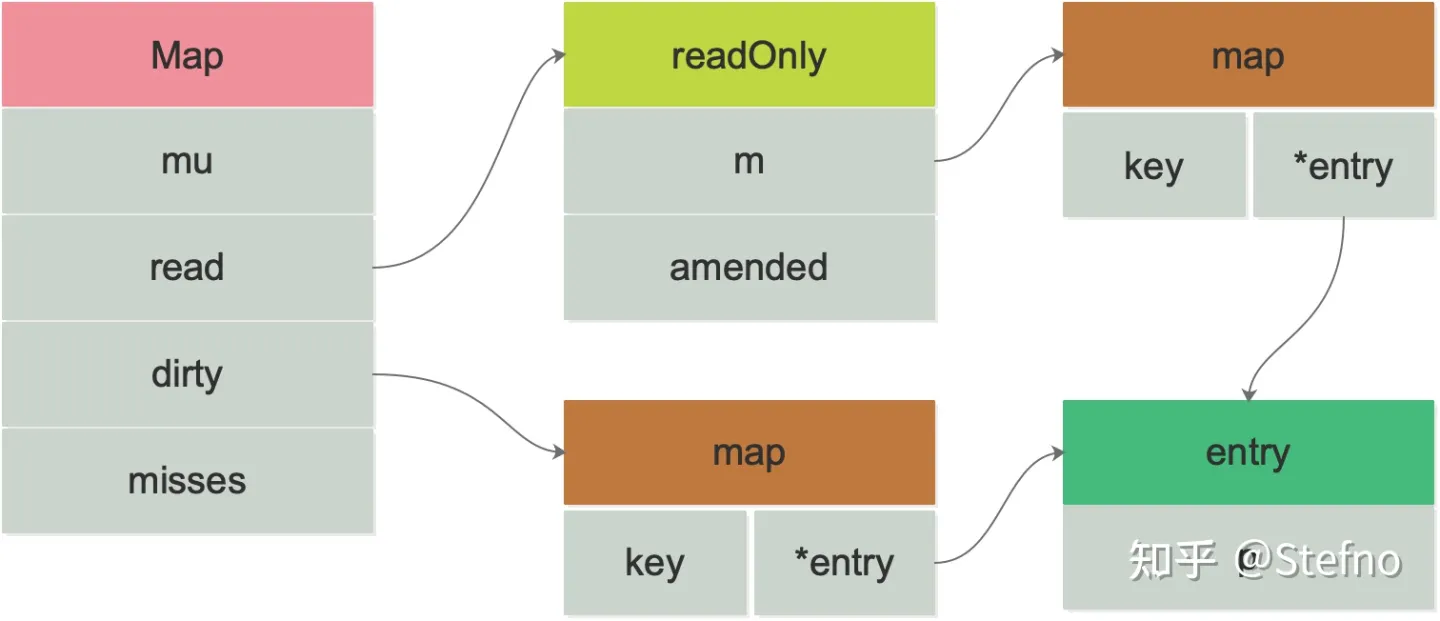
可以看下这个图,理解他们的结构,注意value 在ditry和read中是同一个哦
废话少说,开整~
map的基本操作操作和使用如下
package main
import (
"fmt"
"sync"
)
func main() {
var m sync.Map
m.Store("name", "test")
m.Store("age", "111")
m.Store("abc", "abc")
a, _ := m.Load("name") //
a, _ = m.Load("name")
a, _ = m.Load("name") //dirty 和 read 互换
m.Delete("name") // name = nil
m.Store("a", "a") //name = expunged
fmt.Println(a)
}
现在我们说下每个方法的具体做了啥,首先是load方法,先从read map中查找key,如果key存在,直接返回;key不存在,且read.amended为true(ditry比read有更多的数据),就会ditry map中查找,然后返回value的值,不管要查找的key存不存在,map.misses都要加一哦。因为每次到ditry map查找都要导致misses加一,当misses的值不小于len(ditry)时,就要做ditry和read的变换,ditry中所有值放到read中,ditry设置为nil,misses重置为0。
这时大伙会问了,p干嘛啦,哎~ 这时正常存进来的k-v对的values的地址就是p,也就是p= *interface{} 。
我们接着说下 delete做了啥,还是从read中查找,如果存在,就把这个key的p,设置成nil。如果不存在,则去ditry中直接删除该k-v对。
最后是store方法,这个方法是设置k-v的,设置前要先查找key,这里有三种情况:
- read 存在,p == expunged, 需要先将p设置成nil,然后再修改值,若p != expunged 直接修改值即可
- read 不存在,ditry中存在,直接修改value即可
- read不存在,ditry也不存在,遍历read的所有值,把p=nil 设置成p= expunged,并且存在的于read,不存在ditry的k-v复制到ditry中。
为了便于理解上面的流程,上图
![image]()

了解了以上三步操作,基本就可以理解map是如何运作的。最后重申下,read中使用原子操作,ditry中加锁操作 保证了并发安全
感谢大佬的文章,站在大佬们的肩膀上去理解,果然轻松很多
引用 原生map详解:
https://www.jianshu.com/p/ae90570b463a
https://cloud.tencent.com/developer/article/2072904
sync.map 引用:
https://www.cnblogs.com/ricklz/p/13659397.html
https://zhuanlan.zhihu.com/p/344834329

 浙公网安备 33010602011771号
浙公网安备 33010602011771号