


正则表达式
转自:学无止境(http://www.cnblogs.com/xiashengwang/p/3988009.html)
下面的内容来自于微软的官网。
“正则表达式”描述在搜索文本正文时要匹配的一个或多个字符串。 该表达式可用作一个将字符模式与要搜索的字符串相匹配的模板。正则表达式包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”)。
1,特殊字符
下表包含了单字符元字符的列表以及它们在正则表达式中的行为。
注意:若要匹配这些特殊字符之一,必须首先转义字符,即,在字符前面加反斜杠字符 (\)。 例如,若要搜索“+”文本字符,可使用表达式“\+”。
|
元字符 |
行为 |
示例 |
|
*+? |
*、+、?的整体说明, 1、只对紧挨着上述三个符号的单个字符起作用 2、如果放在括号后,则对括号中的字符起作为一个整体来限制匹配次数 |
大南瓜* 只有瓜才有匹配次数说明,其他字符大南,都是匹配一次即可 |
|
\ |
转义字符,将特殊字符转为普通字符 |
\. \+ \* \? \\ 等 |
|
* |
零次或多次匹配前面的字符或子表达式。 等效于 {0,}。 |
*号前的字符可有可无,多个也算一个,例: 大南瓜* 与源文本匹配中,源文本必须有大南,至于大南后面是否有瓜,或者有多个,都匹配 大 :无匹配 |
|
+ |
一次或多次匹配前面的字符或子表达式。 等效于 {1,}。 |
zo+ 与“zo”和“zoo”匹配,但与“z”不匹配。 执行解析: +号前的字符必须有一个,例: 大南瓜+ 与源文本匹配中,源文本必须有大南,至于大南后面的瓜,至少有一个 大 :无匹配 |
|
? |
零次或一次匹配前面的字符或子表达式。 等效于 {0,1}。 当 ? 紧随任何其他限定符(*、+、?、{n}、{n,} 或 {n,m})之后时,匹配模式是非贪婪的。 非贪婪模式匹配搜索到的、尽可能少的字符串, 而默认的贪婪模式匹配搜索到的、尽可能多的字符串。 |
zo? 与“z”和“zo”匹配,但与“zoo”不匹配。 o+? 只与“oooo”中的单个“o”匹配,而 o+ 与所有“o”匹配。 do(es)? 与“do”或“does”中的“do”匹配。 执行解析: ?号前的字符可有可无,如有最多识别一个,例: 大南瓜? 与源文本匹配中,源文本必须有大南,至于大南后面的瓜,最多匹配一个: 大 :无匹配 |
|
{} |
标记限定符表达式的开始和结尾。 |
a{2,3} 与“aa”和“aaa”匹配。 |
|
{n} |
正好匹配 n 次。 n 是非负整数。 |
o{2} 与“Bob”中的“o”不匹配,但与“food”中的两个“o”匹配。 |
|
{n,} |
至少匹配 n 次。 n 是非负整数。 * 与 {0,} 相等。 + 与 {1,} 相等。 |
o{2,} 与“Bob”中的“o”不匹配,但与“foooood”中的所有“o”匹配。 |
|
{n,m} |
匹配至少 n 次,至多 m 次。 n 和 m 是非负整数,其中 n <=m。 逗号和数字之间不能有空格。 ? 与 {0,1} 相等。 |
在搜索字符串“1234567”中,\d{1,3}与“123”、“456”和“7”匹配。 |
|
| |
指示在两个或多个项之间进行选择。粒度: 东方|西方的太阳, 分两个表达式,表达式1=东方,表达式2=西方的太阳 | z|food 与“z”或“food”匹配。 (z|f)ood与“zood”或“food”匹配。 |
|
/ |
表示 JScript 中的文本正则表达式模式的开始或结尾。 在第二个“/”后添加单字符标志可以指定搜索行为。 | /abc/gi 是与“abc”匹配的 JScript 文本正则表达式。 g(全局)标志指定查找模式的所有匹配项,i(忽略大小写)标志使搜索不区分大小写。 |
|
\ |
将下一字符标记为特殊字符、文本、反向引用或八进制转义符。 | \n 与换行符匹配。 \( 与“(”匹配。 \\与“\”匹配。 |
|
() |
标记子表达式的开始和结尾。 可以保存子表达式以备将来之用。 |
A(\d) 与“A0”至“A9”匹配。 保存该数字以备将来之用。 |
|
(模式) |
与模式 匹配并保存匹配项。 您可以从由 JScript 中的 exec Method返回的数组元素中检索保存的匹配项。 若要匹配括号字符 ( ),请使用“\(”或者“\)”。 |
(Chapter|Section) [1-9] 与“Chapter 5”匹配,保存“Chapter”以备将来之用。 |
|
(?:模式) |
与模式 匹配,但不保存匹配项;即不会存储匹配项以备将来之用。 这对于用“or”字符 (|) 组合模式部件的情况很有用。 |
industr(?:y|ies) 与 industry|industries 相等。 |
|
(?=模式) |
正预测先行。 找到一个匹配项后,将在匹配文本之前开始搜索下一个匹配项。 不会保存匹配项以备将来之用。 |
^(?=.*\d).{4,8}$ 对密码应用以下限制:其长度必须介于 4 到 8 个字符之间,并且必须至少包含一个数字。 在该模式中,.*\d 查找后跟有数字的任意多个字符。 对于搜索字符串“abc3qr”,这与“abc3”匹配。 从该匹配项之前(而不是之后)开始,.{4,8}与包含 4-8 个字符的字符串匹配。 这与“abc3qr”匹配。 ^ 和 $ 指定搜索字符串的开始和结束位置。 这将在搜索字符串包含匹配字符之外的任何字符时阻止匹配。 |
|
(?!模式) |
负预测先行。 匹配与模式 不匹配的搜索字符串。 找到一个匹配项后,将在匹配文本之前开始搜索下一个匹配项。 不会保存匹配项以备将来之用。 |
\b(?!th)\w+\b 与不以“th”开头的单词匹配。 在该模式中,\b 与一个字边界匹配。 对于搜索字符串“ quick ”,这与第一个空格匹配。(?!th) 与非“th”字符串匹配。 这与“qu”匹配。 从该匹配项开始,\w+ 与一个字匹配。 这与“quick”匹配。 |
大多数特殊字符在括号表达式内出现时失去它们的意义,并表示普通字符。 有关更多信息,请参见匹配字符的列表中的“括号表达式中的字符”。
2,匹配单个字符2:特殊字符
|
^ |
匹配搜索字符串开始的位置。 如果标志中包括 m(多行搜索)字符,^ 还将匹配 \n 或 \r 后面的位置。 如果将 ^ 用作括号表达式中的第一个字符,则会对字符集求反。 其他说明:匹配单个字符, |
^\d{3} 与搜索字符串开始处的 3 个数字匹配。 [^abc] 与除 a、b 和 c 以外的任何字符匹配。 |
|
$ |
匹配搜索字符串结尾的位置。 如果标志中包括 m(多行搜索)字符,^ 还将匹配 \n 或 \r 前面的位置。 |
\d{3}$ 与搜索字符串结尾处的 3 个数字匹配。 |
|
. |
匹配除换行符 \n 之外的任何单个字符。 若要匹配包括 \n 在内的任意字符,请使用诸如 [\s\S] 之类的模式。 |
a.c 与“abc”、“a1c”和“a-c”匹配。 |
|
[] |
标记括号表达式的开始和结尾。不管中括号里多少个字符,都是与源文本中的一个字符进行匹配 |
[1-4] 与“1”、“2”、“3”或“4”匹配。[^aAeEiIoOuU] 与任何非元音字符匹配。 |
|
[xyz] |
字符集。 与任何一个指定字符匹配。 |
[abc] 与“plain”中的“a”匹配。 |
|
[a-z] |
字符范围。 匹配指定范围内的任何字符。 |
[a-z] 与“a”到“z”范围内的任何小写字母字符匹配。 |
| [^xyz] | 反向字符集。 与未指定的任何字符匹配。 | [^abc] 与“plain”中的“p”、“l”、“i”和“n”匹配。 |
| [^a-z] | 反向字符范围。 与不在指定范围内的任何字符匹配。 | [^a-z] 与不在范围“a”到“z”内的任何字符匹配。 |
2,匹配单个字符2:元字符
下表包含了多字符元字符的列表以及它们在正则表达式中的行为。
|
元字符 |
行为 |
示例 |
|
\b |
与一个字边界匹配;即字与空格间的位置。 |
er\b 与“never”中的“er”匹配,但与“verb”中的“er”不匹配。 |
|
\B |
非边界字匹配。 |
er\B 与“verb”中的“er”匹配,但与“never”中的“er”不匹配。 |
|
\d |
数字字符匹配。 等效于 [0-9]。 |
在搜索字符串“12 345”中,\d{2}与“12”和“34”匹配。 \d与“1”、“2”、“3”、“4”和“5”匹配。 |
|
\D |
非数字字符匹配。 等效于 [^0-9]。 |
\D+ 与“abc123 def”中的“abc”和“def”匹配。 |
|
\w |
与以下任意字符匹配:A-Z、a-z、0-9 和下划线。 等效于 [A-Za-z0-9_]。 |
在搜索字符串“The quick brown fox…”中,\w+与“The”、“quick”、“brown”和“fox”匹配。 |
|
\W |
与除 A-Z、a-z、0-9 和下划线以外的任意字符匹配。 等效于 [^A-Za-z0-9_]。 |
在搜索字符串“The quick brown fox…”中,\W+ 与“…”和所有空格匹配。 |
|
\cx |
匹配 x 指示的控制字符。 x 的值必须在 A-Z 或 a-z 范围内。如果不是这样,则假定 c 就是文本“c”字符本身。 |
\cM 与 Ctrl+M 或一个回车符匹配。 |
|
\xn |
匹配 n,此处的 n 是一个十六进制转义码。 十六进制转义码必须正好是两位数长。 允许在正则表达式中使用 ASCII 代码。 |
\x41 与“A”匹配。 \x041 等效于后跟有“1”的“\x04”(因为 n 必须正好是两位数)。 |
|
\num |
匹配 num,此处的 num 是一个正整数。 这是对已保存的匹配项的引用。 |
(.)\1 与两个连续的相同字符匹配。 |
|
\n |
标识一个八进制转义码或反向引用。 如果 \n 前面至少有 n 个捕获子表达式,那么 n 是反向引用。 否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。 |
(\d)\1 与两个连续的相同数字匹配。 |
|
\nm |
标识一个八进制转义码或反向引用。 如果 \nm 前面至少有 nm个捕获子表达式,那么 nm 是反向引用。 如果 \nm 前面至少有n 个捕获子表达式,则 n 是反向引用,后面跟有文本 m。 如果上述情况都不存在,当 n 和 m 是八进制数字 (0-7) 时,\nm匹配八进制转义码 nm。 |
\11 与制表符匹配。 |
|
\nml |
当 n 是八进制数字 (0-3),m 和 l 是八进制数字 (0-7) 时,匹配八进制转义码 nml。 |
\011 与制表符匹配。 |
|
\un |
匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。 |
\u00A9 与版权符号 (©) 匹配。 |
3、零宽断言
| 序号 |
表达式 |
模型 | 模型含义 |
|
1 |
(?= 子表达式) |
表达式a(?=表达式b) | 表达式a后面必须跟表达式b,但是匹配时不返回表达式b |
|
2 |
(?<=表达式) |
(?<=表达式b)表达式a | 表达式前面必须有表达式b,但匹配时不返回表达式b |
|
3 |
(?!表达式) |
表达式a(?!表达式b) | 表达式a后面不能跟表达式b |
|
4 |
(?<!表达式) |
(?<!表达式b)(表达式a) | 表达式a前面不能有表达式b |
|
5 |
嵌套:上面四个表达式可以嵌套使用,例: 取一个日期数据,但是日期数据前必须有开标时间:,但是开标时间:前不能有错误 |
1、按照最近规则,首先写表达式:开标时间:前不能有错误 1.1 套用第4个表达式:(?<!表达式) 1.2 根据第4个表达式改造:(?<!错误)开标时间: 1.3 根据表达式2:(?<=表达式) 1.4 改造1.3表达式:把红色部分使用1.2 表达式替换 (?<=(?<!错误)开标时间:)日期表达式 就可以提取日期数据,日期数据前必须有开标时间,而且开标时间前不能有错误 |
|
|
6 |
括号中三个字符总结:上述4个表达式 1.第一个字符:开头必须使用:? 2.第二个字符:如果修饰左边(放到左边),必须用<,如果放到右边则不需要< 3.三个字符:如果包含=,如果不包含!
|
||
|
7 |
平衡组参考:https://blog.csdn.net/zm2714/article/details/7946437
|
||
|
8 |
java中使用零宽断言注意事项,断言中1-4在java中不能使用无上限的数量修饰符号:*,+,{x,},必须有具体的上限,例如:{x,y} 比如:(?<=现浇\s+)混凝土,在java中一般无法通过,需要改为:(?<=现浇\s{0,20})混凝土 |
||

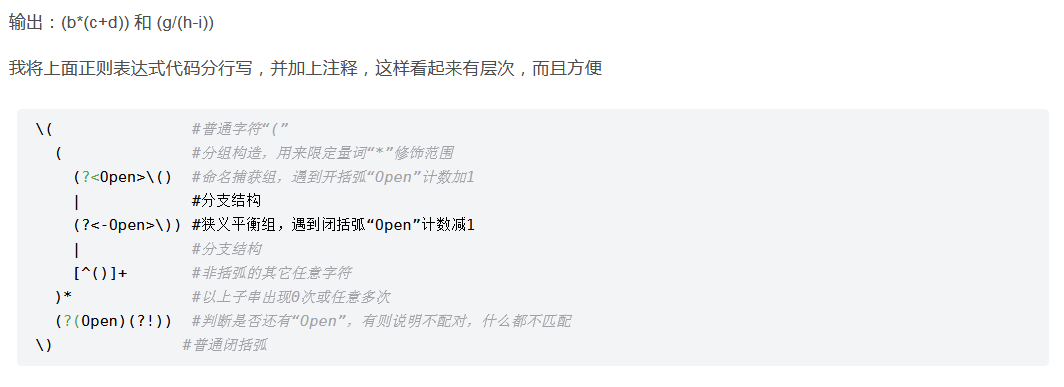
3,非打印字符
下表包含表示非打印字符的转义序列。
|
字符 |
匹配 |
等效于 |
|
\f |
换页符。 |
\x0c 和 \cL |
|
\n |
换行符。 |
\x0a 和 \cJ |
|
\r |
回车符。 |
\x0d 和 \cM |
|
\s |
任何空白字符。 其中包括空格、制表符和换页符。 |
[ \f\n\r\t\v] |
|
\S |
任何非空白字符。 |
[^ \f\n\r\t\v] |
|
\t |
Tab 字符。 |
\x09 和 \cI |
|
\v |
垂直制表符。 |
\x0b 和 \cK |
4,优先级顺序
正则表达式的计算方式与算术表达式非常类似;即从左到右进行计算,并遵循优先级顺序。
下表按从高到低的顺序包含了正则表达式运算符的优先级顺序。
|
运算符 |
说明 |
|
\ |
转义符 |
|
(), (?:), (?=), [] |
括号和中括号 |
|
*、+、?、{n}、{n,}、{n,m} |
限定符 |
|
^、$、\任何元字符 |
定位点和序列 |
|
| |
替换 |
字符具有高于替换运算符的优先级,例如,允许“m|food”匹配“m”或“food”。
5,语法补充
1)(?<捕获组名称>)\k<捕获组名称>——用名称来引用分组
关于分组的详细用法,可以参考整理的这篇文章:http://www.cnblogs.com/xiashengwang/p/3988573.html
2)设置正则表达式的选项
i——所执行的匹配是不区分大小写的(.net中的属性为IgnoreCase)
m——指定多行模式(.net中的属性为Multiline)
n——只捕获显示命名或编号的组(.net中的属性为ExplicitCapture)
c——编译正则表达式,这样会产生较快的执行速度,但启动会变慢(.net中的属性为Compiled)
s——指定单行模式(.net中的属性为SingleLine)
x——消除非转义空白字符和注释(.net中的属性为IgnorePatternWhitespace)
r——搜索从右到左进行(.net中的属性为RightToLeft)
-——表示禁用。
eg.(?im-r:sophia)允许不区分大小写匹配sophia,使用多行模式,但禁用了从右到左的匹配。
注意:
1.m会影响如何解析起始元字符(^)和结束元字符($)。
在默认情况^和$只匹配整个字符串的开头,即使字符串包含多行文本。如果启用了m,那么它们就可以匹配每行文本的开头和结尾。
2.s会影响如何解析句点元字符(.)。通常一个句点能匹配除了换行符以外的所有字符。但在单行模式下,句点也能匹配一个换行符。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!