
分类与监督学习,朴素贝叶斯分类算法
分类与监督学习,朴素贝叶斯分类算法
1.理解分类与监督学习、聚类与无监督学习。
(1) 简述分类与聚类的联系与区别。
分类是按照某种标准给对象贴标签,再根据标签来区分归类。
聚类是指事先没有“标签”而通过某种成团分析找出事物之间存在聚集性原因的过程。
区别是,分类是事先定义好类别 ,类别数不变 。分类器需要由人工标注的分类训练得到,属于有指导学习范畴。聚类则没有事先预定的类别,类别数不确定。 聚类不需要人工标注和预先训练分类器,类别在聚类过程中自动生成 。分类适合类别或分类体系已经确定的场合,比如按照国图分类法分类图书;聚类则适合不存在分类体系、类别数不确定的场合,一般作为某些应用的前端,比如多文档文摘、搜索引擎结果后聚类(元搜索)等。
(2) 简述什么是监督学习与无监督学习。
监督学习中在给予计算机学习样本的同时,还告诉计算各个样本所属的类别。若所给的学习样本不带有类别信息,就是无监督学习。任何一种学习都有一定的目的,对于模式识 别来说,就是要通过有限数量样本的学习,使分类器在对无限多个模式进行分类时所产生的错误概率最小。
在无监督学习的情况下,用全部学习样本可以估计混合概率密度函数,若认为每一模式类的概率密度函数只有一个极大值,则可以根据混合概率密度函数的形状求出用来把各类分开的分界面。
2.朴素贝叶斯分类算法 实例
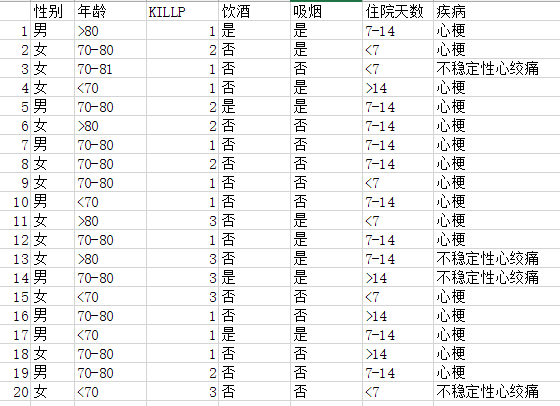
利用关于心脏情患者的临床数据集,建立朴素贝叶斯分类模型。
有六个分类变量(分类因子):性别,年龄、KILLP评分、饮酒、吸烟、住院天数
目标分类变量疾病:–心梗–不稳定性心绞痛
新的实例:–(性别=‘男’,年龄<70, KILLP=‘I',饮酒=‘是’,吸烟≈‘是”,住院天数<7)
最可能是哪个疾病?
实例数据如下表:
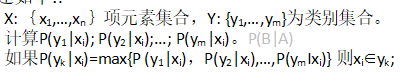
实例结果:

3.编程实现朴素贝叶斯分类算法
利用训练数据集,建立分类模型。
输入待分类项,输出分类结果。
可以心脏病情患者的临床数据为例,但要对数据预处理。
import numpy as np import pandas data=pandas.read_excel('心脏病患者临床数据.xlsx') data #对性别进行处理,男为0,女为1 xingbie=[] for i in data['性别']: if i =='男': xingbie.append(0) else: xingbie.append(1) #对年龄段进行预处理,年龄小于70为1,70-80之间为2,大于80为3 ages=[] for j in data['年龄']: if j =='<70': ages.append(1) elif j =='70-80': ages.append(2) else: ages.append(3) #对住院天数进行处理,小于7天为1,7-14之间为2,大于14天为3 days=[] for k in data['住院天数']: if k=='<7': days.append(1) elif k=='7-14': days.append(2) else: days.append(3) #处理后的数据 data1=data data1['性别']=xingbie data1['年龄']=ages data1['住院天数']=days #将数据转成数组 data_arr=np.array(data1) data_arr #利用贝叶斯算法对给定的组别进行分类 def NB(xingbie, ages, KILLP, drink, smoke, days): #初始化值 x1_y1,x2_y1,x3_y1,x4_y1,x5_y1,x6_y1 = 0,0,0,0,0,0 x1_y2,x2_y2,x3_y2,x4_y2,x5_y2,x6_y2 = 0,0,0,0,0,0 y1 = 0 y2 = 0 #计算为心梗的概率 for a in data_arr: if a[6]=='心梗': y1+=1 if a[0]==xingbie: x1_y1+=1 if a[1]==ages: x2_y1+=1 if a[2]==KILLP: x3_y1+=1 if a[3]==drink: x4_y1+=1 if a[4]==smoke: x5_y1+=1 if a[5]==days: x6_y1+=1 else:#计算患有不稳定性心绞痛的概率 y2+=1 if a[0]==xingbie: x1_y2+=1 if a[1]==ages: x2_y2+=1 if a[2]==KILLP: x3_y2+=1 if a[3]==drink: x4_y2+=1 if a[4]==smoke: x5_y2+=1 if a[5]==days: x6_y2+=1 #计算每种症状在心梗下的概率 x1_y1, x2_y1, x3_y1, x4_y1, x5_y1, x6_y1 = x1_y1/y1, x2_y1/y1, x3_y1/y1, x4_y1/y1, x5_y1/y1, x6_y1/y1 #计算每种症状在不稳定性心绞痛的概率 x1_y2, x2_y2, x3_y2, x4_y2, x5_y2, x6_y2 = x1_y2/y2, x2_y2/y2, x3_y2/y2, x4_y2/y2, x5_y2/y2, x6_y2/y2 #多个症状在心梗下的概率 x_y1 = x1_y1 * x2_y1 * x3_y1 * x4_y1 * x5_y1 * x6_y1 #多个症状在不稳定性心绞痛下的概率 x_y2 = x1_y2 * x2_y2 * x3_y2 * x4_y2 * x5_y2 * x6_y2 ##初始化各个特征x的值 x1,x2,x3,x4,x5,x6=0,0,0,0,0,0 for a in data_arr: if a[0]==xingbie: x1+=1 if a[1]==ages: x2+=1 if a[2]==KILLP: x3+=1 if a[3]==drink: x4+=1 if a[4]==smoke: x5+=1 if a[5]==days: x6+=1 lens = len(data_arr) #所有x的可能性 x = x1/lens * x2/lens * x3/lens * x4/lens * x5/lens* x6/lens # 分别计算心梗和不稳定性心绞痛的概率 y1_x = (x_y1)*(y1/lens)/x print(y1_x) y2_x = (x_y2)*(y2/lens)/x print(y2_x) # 判断是哪种疾病的可能性更大 if y1_x > y2_x: print('病人患心梗的可能性更大,可能性为:',y1_x) else: print('病人患不稳定性心绞痛的可能性更大,可能性为:',y2_x) # 判断:性别=‘男’,年龄<70, KILLP=1,饮酒=‘是’,吸烟=‘是”,住院天数<7 NB(0,1,1,'是','是',1)
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号