我的 Kafka 旅程 - 参数优化 · 性能调优 · 压力测试
系列目录
作者:[Sol·wang] - 博客园,原文出处:https://www.cnblogs.com/Sol-wang/p/16691614.html
一、核心配置
1.1 Producer
于 config/producer.properties 配置文件中的项
# 序列化数据压缩方式 [none/gzip/snappy/lz4/zstd]
compression.type = snappy # default=none
# 内存队列缓冲区总大小
buffer.memory = 67108864 # default=32M
# 数据块/批次 单个大小
batch.size = 32768 # default=16K
# 数据块/批次 过期毫秒
linger.ms = 5 # default=0
# Broker 分区的应答机制
acks = 1 # default=all
# 发送请求允许最大的积压数
max.in.flight.requests.per.connection = 5 # default=5
# 发送失败的重试次数
retries = 2147483647 # default=0
# 发送失败重试间隔毫秒
retry.backoff.ms = 100 # default=100ms
# 幂等性(生产者编号 + Broker分区编号 + 消息编号)
enable.idempotence = true # default=true1.2 Broker
于 config/server.properties 配置文件中的项
# JVM:初始内存/最大内存(相等时减少计算动态扩容)
# 于 kafka-server-start.sh 中调整
#KAFKA_HEAP_OPTS = "-Xms2G –Xmx2G" # default=1G
# 数据写磁盘线程数(占总核心数60%)
num.io.threads = 8 # default=8
# 副本主动拉取线程数(占总核心数10%)
num.replica.fetchers = 1 # default=1
# 数据网络传输线程数(占总核心数30%)
num.network.threads = 3 # default=3
# 不存在的Topic自动创建
auto.create.topics.enable = true # default=true
# 副本通信超时
replica.lag.time.max.ms = 30000 # default=30000
# Broker leader partition 分区再平衡
auto.leader.rebalance.enable = true # default=true
# 再平衡警戒值(%)
leader.imbalance.per.broker.percentage = 1 # default=10
# 再平衡检测间隔秒数
leader.imbalance.check.interval.seconds = 300 # default=300
# 数据分片单文件大小
log.segment.bytes = 1073741824 # default=1GB
# 数据每索引范围大小
log.index.interval.bytes = 4096 # default=4KB
# 数据保留时长
log.retention.hours = 168 # default=168 (7天)
# 数据保留分钟
log.retention.minutes # default=null
# 数据保留毫秒
log.retention.ms # default=null
# 数据保留检测间隔
log.retention.check.interval.ms = 600000 # default=300000
# 数据保留总大小
log.retention.bytes = -1 # default=-1 (无穷大)
# 数据删除策略 [compact,delete]
log.cleanup.policy = delete # default=delete1.3 Consumer
于 config/consumer.properties 配置文件中的项
# 自动提交消费偏移量
enable.auto.commit = true # default=true
# 提交消费偏移量频率间隔
auto.commit.interval.ms = 5000 # default=5000
# 缺少偏移量的处理 [latest,earliest,none]
auto.offset.reset = latest # default=latest
# 分区数
offsets.topic.num.partitions = 50 # default=50
# 与Broker间的心跳间隔
heartbeat.interval.ms = 5000 # default=3000
# 与Broker间的超时
session.timeout.ms = 45000 # default=45000
# 消息处理最大时长
max.poll.interval.ms = 300000 # default=300000
# 单次拉取数据大小
fetch.max.bytes = 57671680 # default=50M
# 单次拉取数据最大条数
max.poll.records = 500 # default=500
# 再平衡策略 # default= Range + CooperativeSticky
partition.assignment.strategy = class...RangeAssignor,class...CooperativeStickyAssignor二、整体吞吐量
2.1 生产者
- buffer.memory:增加内存缓冲区
- batch.size:增加单数据块/批次容量
- linger.ms:消息发送延迟5毫秒
- compression.type:开启压缩
2.2 Broker
- 增加分区数(按分类分区)并行处理
2.3 消费者
- fetch.max.bytes:每次消费数据最大容量
- max.poll.recodes:每次消费数据最大条数
三、数据精确一次
生产者:acks = all,幂等性 + 事务
Broker:分区副本至少大于2,防丢失
消费者:手动提交offset + 事务
四、压力测试
4.1 生产者端测试效果
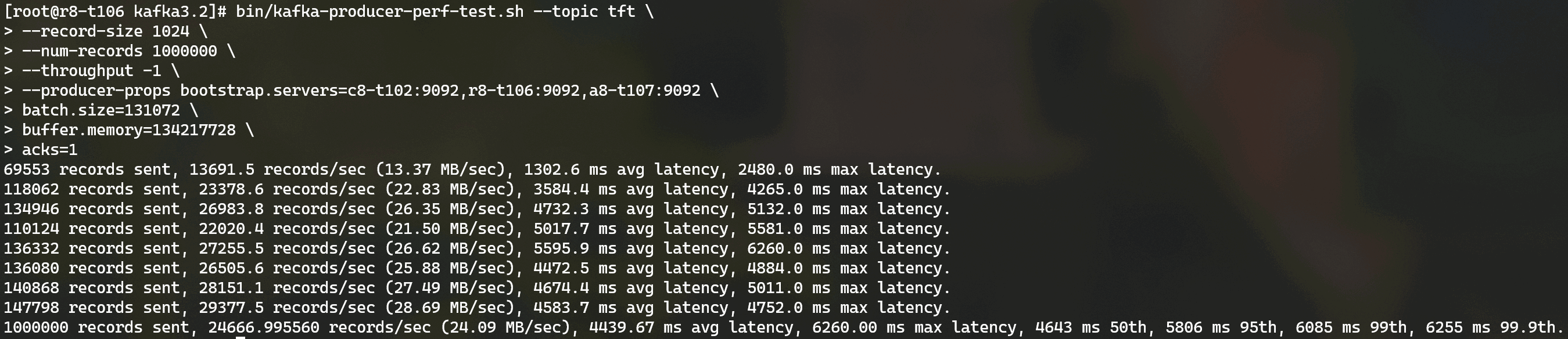
4.2 消费者端测试效果

鄙人拙见,有不妥望指出,让我纠正,万分感谢⭐⭐⭐
作者:Sol·wang - 博客园
出处:https://www.cnblogs.com/Sol-wang/p/16691614.html
声明:本文版权归作者和[博客园]共有,未经作者同意,不得转载。
作者:Sol·wang - 博客园
出处:https://www.cnblogs.com/Sol-wang/p/16691614.html
声明:本文版权归作者和[博客园]共有,未经作者同意,不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号