数据校验码
差错 (Error)
-
数据在计算机内部进行计算、存取和传送过程中,由于元器件故障或噪音干扰等原因,会出现差错。
-
以存储为例
- 硬故障(hard failure):永久性的物理故障,以至于受影响的存储单元不能可靠地存储数据,成为固定的“1”或“0”故障,或者在0和1之间不稳定地跳变。
- 由恶劣的环境、制造缺陷和旧损引起
- 软故障(soft error):随机非破坏性事件,它改变了某个或某些存储单元的内容,但没有损坏机器。
- 由电源问题或α粒子引起。
- 硬故障(hard failure):永久性的物理故障,以至于受影响的存储单元不能可靠地存储数据,成为固定的“1”或“0”故障,或者在0和1之间不稳定地跳变。
-
解决方案
• 从计算机硬件可靠性入手,在电路、电源、布线等方面采取必要
的措施,提高计算机的抗干扰能力
• 采取数据检错和校正措施,自动发现并纠正错误。
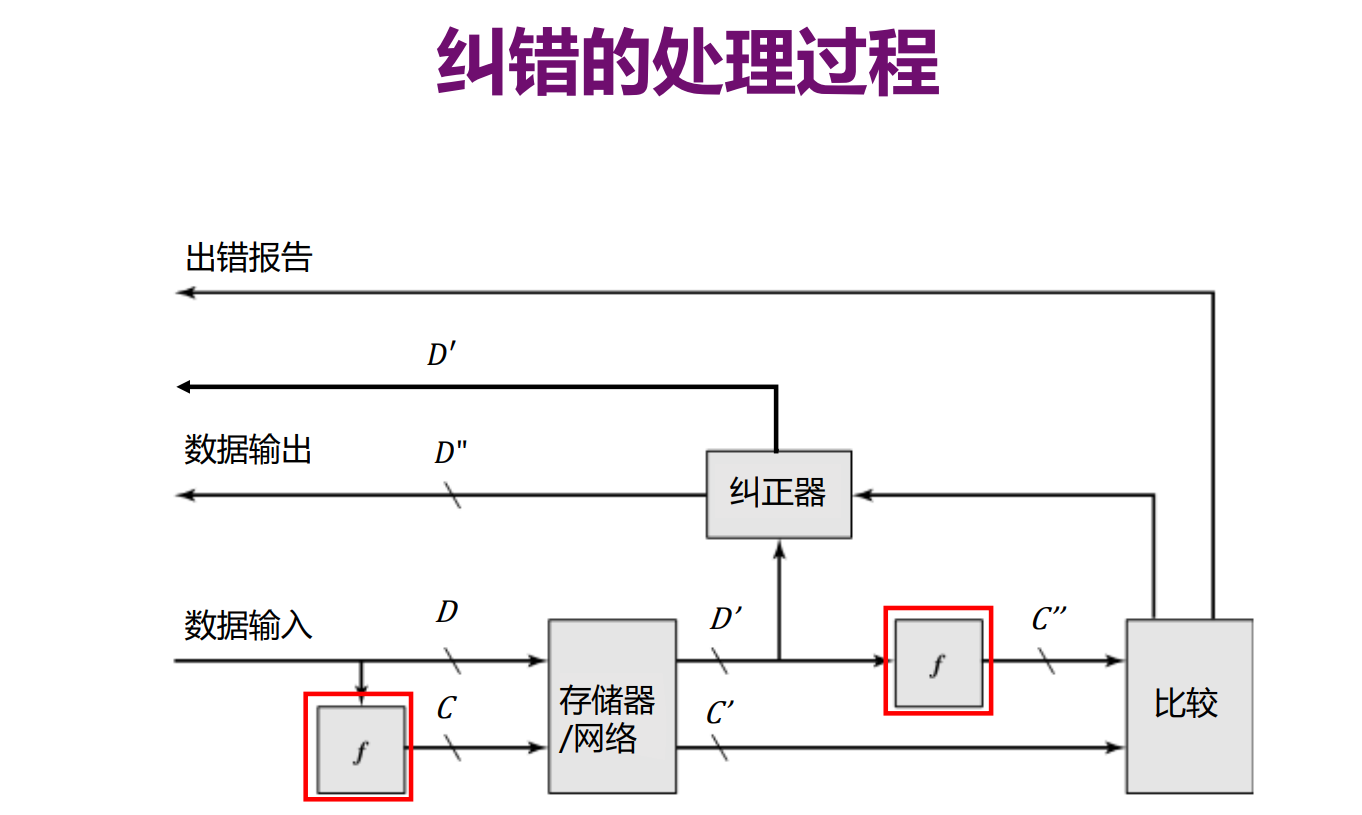
纠错(Error Correction)
-
基本思想:存储额外信息进行检错和校正。
-
处理过程:
-
数据输入:使用函数 \(f\) 在 \(M\) 位数据 \(D\) 上生成 \(K\) 位校验码 \(C\)。
-
使用函数 \(f\) 在 \(M\) 位数据 \(D'\) 上生成新的 \(K\) 位校验码 \(C''\), 并和取出的 \(K\) 位码 \(C'\) 进行比较。
-
没有检测到差错:使用 \(D'\)
-
检测到差错且可以纠正:纠正 \(D'\) 得到 \(D''\),并用 \(D''\)。
-
检测到差错但无法修复:报告。
奇偶校验码
-
基本思想:增加一位奇偶校验位来表示数据中的 1 的个数是奇数还是偶数。
-
处理过程:假设数据 \(D=D_M....D_1\)
-
数据输入:
-
奇校验:\(C = D_M\oplus D_{M-1}...\oplus D_1\oplus 1\)
-
偶校验:\(C = D_M \oplus ...\oplus D_1\)
-
数据输出:
-
奇校验:\(C'' = D'_M\oplus ...\oplus D'_1\oplus 1\)
-
偶校验:\(C'' = D'_M\oplus ...\oplus D_1\)
-
检错
\(S = C'\oplus C''\)
当 S = 0:没有差错或者差错个数为偶数个。
当 S = 1:差错个数为奇数个。 -
优点
只需要 1 位额外位,代价低。 -
缺点
无法发现偶数个差错的情况,而且无法校正。(因为并不能定位差错的位置) -
适用于较短的数据(比如1个字节)的检错:因为在短数据内出现多个差错的可能性较小。
在奇偶校验码的基础上,我们对一个数据的位分组,分别使用奇偶校验码,就得到了海明码。
海明码
- 基本思想:把数据分成 K 组,对每一组都使用奇偶校验码进行纠错。
- 处理过程:
为输入数据 D 的每组产生一位奇偶校验码,得到 K 位奇偶校验码 C 。
为输出数据 D' 的每组产生一位奇偶校验码,得到 K 位奇偶校验码 C'' - 检错:将 C'' 和取出的 C' 按位异或得到 K 位故障字 (syndrome word)
接下来要考虑的问题就是,如何分组,要分多少组。
我们先来考虑要分多少组。
对于检错结果有以下的情况:
- 校验位中出现 1 位错误。 K 种情况
- 数据中出现 1 位错误 M 种
- 没有错误 1 种情况
因此,要表示这么多情况,K,M 必然满足如下不等式 \(2^K \ge M+K+1\)
故障字的作用
• 每种取值都反映一种情形(数据出错 / 校验码出错 / 未出错)
• 规则
• 全部是0:没有检测到错误
• 有且仅有1位是1:错误发生在校验码中的某一位,不需要纠正
• 有多位为1:错误发生在数据中的某一位,将𝐷′中对应数据位
取反即可纠正(得到𝐷")
那么接下来的一个重要的问题是:如何对数据进行划分?
• 数据位划分
• 假定数据位为8位 𝐷 = 𝐷8 … 𝐷2𝐷1, 校验码为4位𝐶 = 𝐶4𝐶3𝐶2𝐶1
• 数据位/校验码与故障字的关系

• 数据位划分
𝐶1 = 𝐷1 ⊕ 𝐷2 ⊕ 𝐷4 ⊕ 𝐷5 ⊕ 𝐷7
𝐶2 = 𝐷1 ⊕ 𝐷3 ⊕ 𝐷4 ⊕ 𝐷6 ⊕ 𝐷7
𝐶3 = 𝐷2 ⊕ 𝐷3 ⊕ 𝐷4 ⊕ 𝐷8
𝐶4 = 𝐷5 ⊕ 𝐷6 ⊕ 𝐷7 ⊕ 𝐷8
该如何理解以上的公式呢?
首先我们需要引入一个假设,那就是数据位和校验码加起来形成的信息最多只有一位出错,这是合理的,因为在这种短数据里,如果硬件没问题,多位出错的概率很小。
如果 4 位故障字中只有一个 1,那么说明 C',C'' 有且仅有 1 位不同,再结合假设,可知是对应校验位出错。
要明白如何分组,我们看 \(D_i\) 对应的故障字,比如 \(D_1\), 它对应的故障字是 0011,第一个数据位出错会导致这种故障字的产生,可知 \(D_1\) 会影响 \(C_1,C_2\),因此在 \(C_1,C_2\) 的计算式中要包含 \(D_1\), 其他的也是以此类推。
• 位安排
• 将位设置在与其故障字值相同的位置
• 示例
• 假定8位数据字为𝐷=01101010,在生成海明码时采用偶校验
• 校验位计算如下
𝐶1 = 𝐷1 ⊕ 𝐷2 ⊕ 𝐷4 ⊕ 𝐷5 ⊕ 𝐷7 = 0 ⊕ 1 ⊕ 1 ⊕ 0 ⊕ 1 = 1
𝐶2 = 𝐷1 ⊕ 𝐷3 ⊕ 𝐷4 ⊕ 𝐷6 ⊕ 𝐷7 = 0 ⊕ 0 ⊕ 1 ⊕ 1 ⊕ 1 = 1
𝐶3 = 𝐷2 ⊕ 𝐷3 ⊕ 𝐷4 ⊕ 𝐷8 = 1 ⊕ 0 ⊕ 1 ⊕ 0 = 0
𝐶4 = 𝐷5 ⊕ 𝐷6 ⊕ 𝐷7 ⊕ 𝐷8 = 0 ⊕ 1 ⊕ 1 ⊕ 0 = 0
• 存储时的12位内容
011001010011
• 获取时的12位内容
• 情形1: 011001010011
𝐷′=01101010 𝐶′′=0011, 𝐶′=0011
𝑆 = 𝐶′′ ⊕ 𝐶
′
= 0011⨁0011 = 0000
• 情形2: 011101010011
𝐷′=01111010 𝐶′′=1010, 𝐶′=0011
𝑆 = 𝐶′′ ⊕ 𝐶
′
= 1010⨁0011 = 1001
• 情形3: 011011010011
𝐷′=01101010 𝐶′′=0011, 𝐶′=1011
𝑆 = 𝐶′′ ⊕ 𝐶
′
= 0011⨁1011 = 1000
循环冗余校验
• 奇偶校验问题: 额外成本很大,要求将数据分成字节
• 循环冗余校验(Cyclic Redundancy Check, CRC)
• 适用于以流格式存储和传输大量数据
• 用数学函数生成数据和校验码之间的关系
• 基本思想
• 假设数据有M位,左移数据K位(右侧补0),并用K+1位生成多项
式除它(模2运算)
• 采用K位余数作为校验码
• 把校验码放在数据(不含补的0)后面,一同存储或传输
• 校错
• 如果M+K位内容可以被生成多项式除尽,则没有检测到错误
• 否则,发生错误
NOTE: MOD2 除法
MOD 2 除法的一种理解方法是用 MOD2 减法来实现,在 MOD 2 减法中,1-0=0-1=1,1-1=0-0=0,可以看出,其实就是异或运算。每次减去除数的一个若干倍数,最后直到无法再相减,即被减数有效位数小于减数。
例:110011000/1001
110011000-100100000 = 111000
111000 - 100100 = 11100
11100 - 10010 = 1110
1110 - 1001 = 111
因此最后余数为 111
总结
•纠错
•数据出错的原因,纠错的原理和处理过程
•常用的数据校验码
•奇偶校验码
•海明码
•循环 冗余校验码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号