特征抽取--标签与索引的转化: OneHotEncoder
独热编码(One-Hot Encoding) 是指把一列类别性特征(或称名词性特征,nominal/categorical features)映射成一系列的二元
连续特征的过程,原有的类别性特征有几种可能取值,这一特征就会被映射成几个二元连续特征,每一个特征代表一种取值,若该样
本表现出该特征,则取1,否则取0。
One-Hot编码适合一些期望类别特征为连续特征的算法,比如说逻辑斯蒂回归等。
首先创建一个DataFrame,其包含一列类别性特征,需要注意的是,在使用OneHotEncoder进行转换前,DataFrame需要先使用
StringIndexer将原始标签数值化:
#导入相关的类库from pyspark.sql import SparkSession
from pyspark.ml.feature import OneHotEncoder,StringIndexer
#创建SparkSession对象,配置spark
spark = SparkSession.builder.master('local').appName('OneHotEncoderDemo').getOrCreate()
#创建一个简单的DataFrame训练集
df = spark.createDataFrame([
(0, "a"),
(1, "b"),
(2, "c"),
(3, "a"),
(4, "a"),
(5, "c")
], ["id", "category"])
#创建StringIndexer对象,设置输入输出参数
indexer = StringIndexer(inputCol='category', outputCol='categoryIndex')
#生成训练模型
model = indexer.fit(df)
#利用生成的model对DataFrame进行转换
indexed = model.transform(df)
#创建OneHotEncoder对象,设置输入输出参数
onehotencoder = OneHotEncoder(inputCol='categoryIndex', outputCol='categoryVec')
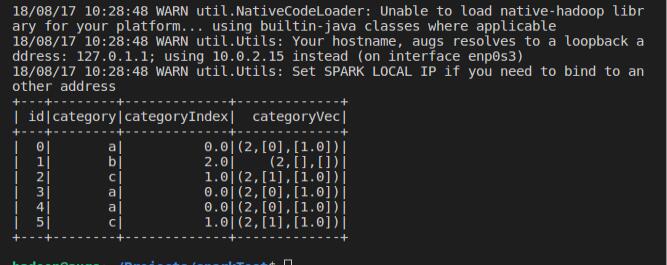
#我们创建OneHotEncoder对象对处理后的DataFrame进行编码,可以看见,编码后的二进制特征呈稀疏
#向量形式,与StringIndexer编码的顺序相同,需注意的是最后一个Category(”b”)被编码为全0向
#量,若希望”b”也占有一个二进制特征,则可在创建OneHotEncoder时指定setDropLast(false)。
oncoded = onehotencoder.transform(indexed)
oncoded.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号