八叶一刀流·六之型·绯空斩·第二次结对
结对情况
305 锦谋
403 俊
GitHub 项目链接
(其实是code.net项目链接)
设计说明
接口设计(API)
class dep2stu()
{
virtual void readdata(int studentnumber,int department) = 0;
virtual void match() = 0;
virtual void printdata() = 0;
}
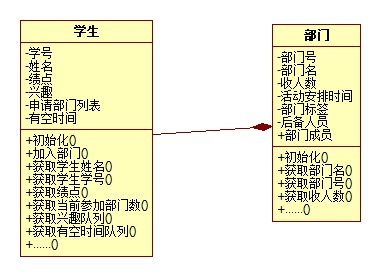
内部实现设计(类图)
学生类的属性主要包括了:学号、姓名、绩点成绩、兴趣标记、加入部门数以及申请部门列表、以及学生的时间安排。Priority是按照匹配规则所确定的学生优先度。
部门类主要属性有学号、姓名、部门人数上限、部门时间安排部门所需兴趣标签等。
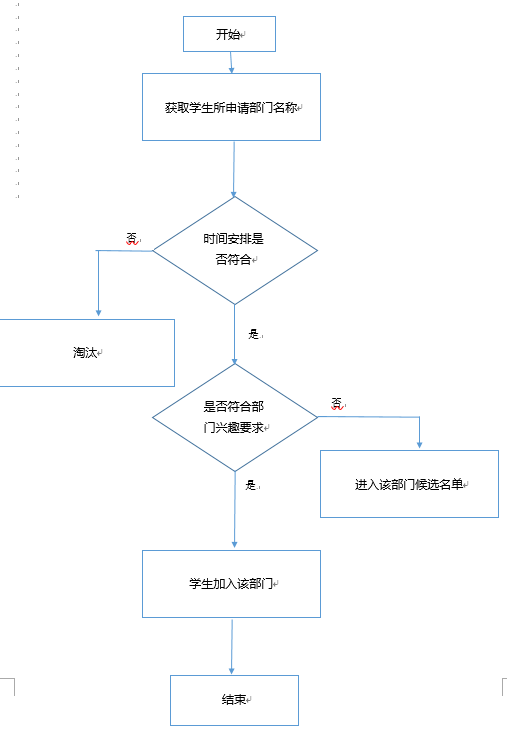
匹配算法设计(思想/流程等)
匹配的过程主要是两次筛选。
第一次从学生入手,第二次从部门开始。匹配规则主要是首先确定学生优先度。这里按照每一位学生的绩点成绩从高到低依次排列。然后再根据学生所申请部门逐个进行匹配。按照部门要求进行筛选。筛选过程主要是,对于选择该部门的学生,首先要满足至少出现一次与部门事务安排时间相符合,即确保该名学生至少能够有时间参加部门活动。然后对于符合时间要求的学生,还要视其兴趣情况而定。
分为两种情况。
-
对于满足兴趣至少一种符合该部门要求的学生,可以加入该部门
-
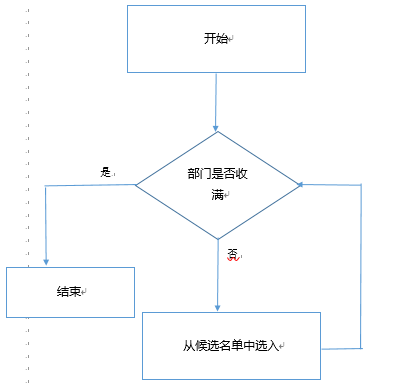
为了保证部门能够最大限度收到成员,对于兴趣没有一项满足该部门的学生,并不直接淘汰,而是将其加入部门的候选成员队列,当部门完成对所有学生的筛选过后,如果有部门还未收满成员,则可以从候选名单中依次选入部门直到部门人数达到上限。(这里仍然保证了候选成员依旧按照绩点成绩为优先级)。
两次选择过程结束后,则完成了这次匹配。
第一次筛选
第二次筛选
测试数据如何生成?
根据
输入的数据,另外写生成程序随机实现
写了个生成程序,部分函数实现如下
string tags[10] = { "writing", "management", "dancing", "singing", "running","photography", "painting", "broadcast", "edit", "contact"........};
vector<string>departments;//部门数组
/**
* \brief 生成范围内随机数
* \param m 范围最小值
* \param n 范围最大值
* \return 范围内随机数
*/
int rand_int(int m, int n)
{
const auto result = rand() % (n - m + 1) + m;
return result;
}
/**
* \brief 生成随机小数
* \param min 随机下限
* \param max 随机上限
* \return 生成的范围内随机浮点数
*/
double rand_double(int min, int max)
{// 计算 0,1之间的随机小数,得到的值域近似为(0,1)
const auto m1 = double(rand() % 101) / 101;
//将 区间变为(min+1,max)
min++;
//计算 min+1,max 之间的随机整数,得到的值域为[min+1,max]
auto m2 = double((rand() % (max - min + 1)) + min);
//令值域为[min,max-1]
m2 = m2 - 1;
return m1 + m2; //返回值域为(min,max),为所求随机浮点数
}
/**
* \brief 生成随机部门名
* \return 部门名
*/
string rand_depname()
{
string result = "XXXXXXXX";
for (auto i = 0; i < result.size(); i++)
{
result[i] = char(rand_int('A', 'z'));
if (result[i] > 'Z' && result[i] < 'a')
{
result[i] += 6;
}
}
departments.push_back(result);
/*cout << departments.back() << endl;
Sleep(1500);*/
return result;
}
string rand_charactertics()
{
const auto flag = rand_int(0, 9);
return tags[flag];
}
/**
* \brief 得到部门标签字符串
* \return 返回部门标签
*/
string rand_deptags()
{
const auto interest_number = rand_int(1, 3);
int flag[10] = { 0 };
auto order = rand_int(0, 9);
string result = "[";
flag[order] = 1;
result = result + "\"" + tags[order] + "\"";
for (auto i = 1; i < interest_number; i++)
{
result = result + ",\"";
while (flag[order])
{
order = rand_int(0, 9);
}
result = result + tags[order] + "\"";
flag[order] = true;
}
result = result + "]";
return result;
}
/**
* \brief 姓名
* \return 姓名
*/
string rand_stuname()
{
return get_name();
}
/**
* \brief 生成随机部门字符串
* \return 申请的部门列表
*/
string rand_applies()
{
const auto apply_number = rand_int(1, 5);//申请的部门数
bool flag[100] = { false };//部门是否已申请的标志
auto order = rand_int(0, departments.size()-1);//申请的部门的序号
auto result = "[\"" + departments.at(order) + "\"";//申请的部门名
flag[order] = true;
for (auto i = 1; i < apply_number; i++)
{
result = result + ",\"";
while (flag[order])
{
order = rand_int(0, departments.size()-1);
}
result = result + departments.at(order) + "\"";
flag[order] = true;
}
result += "]";
return result;
}
完全就是文本文档的生成方法啊!是不是会被打!
如何评价自己的匹配算法?
对于这个算法,大体上还是实现了我们一开始的想法。
首先,对于学生优先度按照绩点确立。主要是利用了快速排序算法,这个算法在数据结构课上学习过了,用起来还是比较顺手的,而且在大量数据的情况下还是可以比较稳定的,算法复杂度在nlogn。
对于第一次筛选的过程,采用了笨办法。即一次次去遍历访问每个学生的申请列表每次访问学生申请的时候还都要访问部门名称,这个部分有太多的重复操作,且耗时最大,没有能够做到相应的精简。在最坏的情况下这个算法复杂度达到了n的三次方。
对于第二次筛选的过程,在快排之后记录每个学生的优先度并作为其成员。第二次筛选是针对未收满的部门,时间主要花费在对每个部门的遍历以及未满部门成员队列的操作,最坏情况下复杂度达到n的平方。
关键代码解释
快排
这个快排算法主要思想就是分块排序。首先选取最左端学生的绩点作为关键字。遍历这个块,当访问到绩点大于关键字的学生,将其与原来的最左端所处的位置调换位置。这样每次分块都实现了标记的那个学生前面的都是大于他的绩点的学生,后面都是绩点小于他的学生,实现了块内的相对有序。然后将块逐渐变小最后实现整个块的相对降序。
int par(int l, int r)
{
const double key = student_s[l].getgpa();
Student temp;
auto i = l, j = r;
while (i < j)
{
while (i < j&&student_s[j].getgpa() <= key)
j--;
temp = student_s[j];
student_s[j] = student_s[i];
student_s[i] = temp;
while (i < j&&student_s[i].getgpa() >= key)
i++;
if (i == j)
{
return i;
}
temp = student_s[j];
student_s[j] = student_s[i];
student_s[i] = temp;
}
}
void quicksort(int l, int r)
{
if (l < r)
{
const auto i = par(l, r);
quicksort(l, i - 1);
quicksort(i + 1, r);
}
}
第一次筛选代码
//遍历学生和部门
for (auto i = 0; i < students_number; i++)
{
while (!student_s[i].apply.empty())
{//申请队列为空说明完成匹配退出
for (auto j = 0; j < department_number; j++)
{
if (student_s[i].apply.empty())
break;
if (student_s[i].apply.front() == department_d[j].getDname())
{//如果学生申请列表与当前部门名称匹配
if (department_d[j].member.size() < department_d[j].getlimit() && Issuit(student_s[i], department_d[j]))
{ //如果部门成员数量没有达到上限
if (Istags(student_s[i], department_d[j]))
{//加入该成员
department_d[j].member.push(student_s[i].getSname());
student_s[i].Setp();//学生参加部门数+1
}
else
department_d[j].bPush(student_s[i]);
}
if (!student_s[i].apply.empty())student_s[i].apply.pop();//无论是否学生能加入部门,都要讲该部门从申请列表推出 ,确保循环可以终止
}
}
}
}
第二次筛选算法
for (int i = 0; i < department_number; i++)
{
while (!department_d[i].bEmpty())
{
if (department_d[i].getlimit() > department_d[i].member.size())
{
const int snub = department_d[i].bFront().getpr();//用于记录候选成员的优先值
department_d[i].member.push(student_s[snub].getSname());
student_s[snub].Setp();
department_d[i].bPop();//候选加入推出
}
if (department_d[i].getlimit() == department_d[i].member.size())break;
}
}
运行及测试结果展示
说明:(有关测试时间的代码在上传源码里没有)
在解决方案配置为debug时消耗有一定的时间,数据5000-100的时候达到20S。
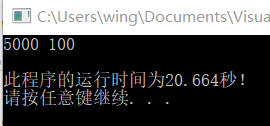
但是在release下,数据5000-100不需1S!
神奇

- 输入情况
{
"departments":
[
{
"department_no":"FZU_1905",
"department_name":"jRaDYxXL",
"member_limit": 14,
"tags":["painting","singing","photography"],
"event_schedules":["Fri.21:00-22:00"]
},
……
]
"students":
[
{
"student_no":"161708261",
"student_name":"Jorge Wagner",
"student_GPA":2.02,
"apply_departments":["tXZDfoaP"],
"tags":["contact"],
"available_schedules":["Mon.19:00-20:00","Thu.20:00 - 21:00","Fri.21:00-22:00","Set.21:00-22:00","Tue.20:00 - 21:00"……]
},
……
]
}
- 测试200位同学,20个部门的情况
{
"matched_department_view":
[
{
"department_name":"jRaDYxXL",
"members":["Dale Butler","Aaron Ellis","Randall White","Janice Webb","Dorothy Reyes","Julia Ross","Keith Allen","Josephine Weaver","Warren Hudson","Rita Franklin","JeanneJames Wallace","Willie Torres","Justin Clark","Jesus Ferguson"]
},
……
],
"matched_student_view":
[
{
"student_name":"Dale Butler",
"departments":["qlEFHBVr","jRaDYxXL","aBHXcebW"]
},
……
],
"standalone_departments":
[
"tXZDfoaP",
"rlYJPezy",
"xdaEEMyr",
"IqExCZha"
]
"standalone_students":
[
"Irene Lee",
"George Gonzalez",
"Melissa Torres",
……
]
- 测试500位同学,30个部门的情况
{
"matched_department_view":
[
{
"department_name":"FPfjMnLY",
"members":["Leonard Washington","Michael Richardson","Eddie Lawson"]
},
……
]
"matched_student_view":
[
{
"student_name":"Crystal Rose",
"departments":["ZbkWhWSe"]
},
……
]
"standalone_departments":
[
"qZkKNLiV",
"vWYCXFXb",
"RIGouufg"
]
"standalone_students":
[
"Judy Cox",
"Phyllis Stephens",
"Kenneth Nichols",
……
]
- 测试1000位同学,50个部门的情况
{
"matched_department_view":
[
{
"department_name":"LdatYlty",
"members":["Tina Freeman","Lawrence Green","Roger Hudson","Sheila Kelly"]
},
……
]
"matched_student_view":
[
{
"student_name":"kexiao Spencer",
"departments":["YXfRAPLx","fodAHEeT","wftWyfnN"]
},
……
]
"standalone_departments":
[
"ivylCYEl",
"uaUeeadc"
]
"standalone_students":
[
"Eugene Murray",
"Jesus Carter",
……
]
- 测试5000位同学,100个部门的情况
{
"matched_department_view":
[
{
"department_name":"YBsdwiIm",
"members":["Manuel Lane","Sharon Ferguson","Sherry Dixon","Sylvia Berry","Pauline Carter","Patrick Reyes","Dean Lawrence","Carol Hudson","Sandra Walker","Joyce Price","Leroy Palmer"]
},
……
]
"matched_student_view":
[
{
"student_name":"Melvin Graham",
"departments":["XJaukdbN","LRnecZhP","fXZlYqbb","ftvNpJfw","DEcLDigr"]
},
……
]
"standalone_departments":
[
"cktIToQc",
"JWGXzbhE",
"ofVXRuMX",
"nxongGef",
"SiEuaziE"
]
"standalone_students":
[
"Rodney Perkins",
"Raymond Duncan",
"Audrey Grant",
……
]
效能分析
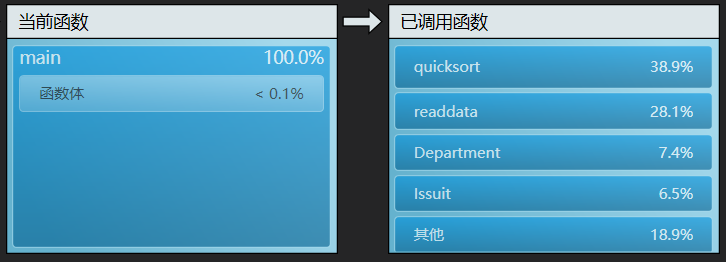
从上图来看,最耗时间的是就是花在了快排上面,然后是读入数据。
很奇怪最耗时间的部分居然不是在匹配而是在排序上面,那么这排序是多耗时间啊。
快排用在了给学生按照绩点排序上,如果不按照绩点排序,纯粹按照最原始的顺序来的话,想必会省下很多时间来做其他的运算。
之后是读入文件信息,我们采用的方法是将文件内容读入字符串,再将字符串做成JSON变量。可是文件本身就是JSON,这样的转化无形之种就导致了多余的时间消耗。
遇到的困难及解决方法
遇到的困难主要有两点。第一点就是对于学生按照绩点进行排序。第二点就是对于学生申请与部门名称的对应。
-
首先最直观的是两次循环两次遍历,但是太过于麻烦。然后尝试冒泡排序算法。但是冒泡排序复杂度仍然过高。于是使用快速排序算法解决这个问题。
-
尝试过使用哈希函数。但是由于哈希函数的制定不过完善,容易出现不同名字出现相同哈希值的情况,这时候就出现了巨大的bug所以对这一部分还需要后续对哈希更深入的了解与学习解决这个问题。
收获就是复习了算法课学习的内容,加深了快速排序算法的印象,也复习了像queue这类容器的使用,算是对C++基础内容的巩固吧。
对队友的评价
- 优点和值得学习的地方
- 说了就做,完成及时
- 其实编码能力不错嘛
- 缺点和需要改进的地方
- 编码风格,说了前花括号要放到下一行还是没有换,if/while/for之后一定要要花括号就算是一行的代码还是没有遵守。
- 函数名和变量名尽量取得有意义一点吧,n1/n2什么的……
- 注释注释!
- (都是编码风格太难改了)
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 5 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 205+∞ | 305+∞ |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 10 |
| · Design | · 具体设计 | 60 | 120 |
| · Coding | · 具体编码 | +∞ | +∞ |
| · Code Review | · 代码复审 | 30 | 45 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 10 | 30 |
| Reporting | 报告 | 105 | 140 |
| · Test Report | · 测试报告 | 30 | 45 |
| · Size Measurement | · 计算工作量 | 15 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 75 |
| 合计 | 315+∞ | 495+∞ |
学习进度条
| 第 N 周 | 新增代码(行) | 累计代码(行) | 学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 第 0 周 | 192 | 192 | 31 | 31 | 复习C++语法、学习VS2017操作、了解回溯 |
| 第 1 周 | 0 | 192 | 7 | 38 | 原型设计、合作探讨、学习需求分析 |
| 第 2 周 | 0 | 192 | 2 | 42 | 团队作业、NABCD |
| 第 3/4 周 | 309 | 501 | 13 | 55 | JSON、文件操作.国庆 |
| 第 5 周 | 176 | 677 | 12 | 67 | 配和队友输入输出 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号