Day 2 - 分治、倍增、LCA 与树链剖分
分治的延伸应用
应用场景
优化合并
假设将两个规模 \(\frac{n}{2}\) 的信息合并为 \(n\) 的时间复杂度为 \(f(n)\),用主定理分析时间复杂度 \(T(n) = 2 \times T(\frac{n}{2}) + f(n)\)。
能直观的看出优化程度还是很大的。
归并排序中 \(f(n) = O(n)\),则 \(T(n) = O(n \log n)\)。
特别的当 \(f(n) = O(n^k),k \ge 2\) 时,我们通常不会使用分治,因为无法优化时间复杂度。
优化合并通常应用于哈夫曼树、线段树。
优化计数
我们对长度为 \(n\) 的序列 \(\{a_n\}\) 统计有多少对 \((i,j)\),使得 \(i < j\) 且 \(a_i > a_j\)。
可以使用分治求解 \([l,r]\) 一段内逆序对数。
我们令 \(\text{mid} = \frac{l + r}{2}\),分别处理 \([l,\text{mid}]\) 和 \([\text{mid},r]\) 即可。
代码实现的注意事项:
-
特判分治的递归边界。
-
若用到临时数组,确保其得到清空,切勿盲目 \(\text{memset}\)。
倍增法
\(\text{RMQ}\) 是英文 \(\text{Range Maximum/Minimum Query}\) 的缩写,表示区间最大(最小)值。
而 \(\text{ST}\) 表是用于解决可重复贡献问题的数据结构。
记 \(f(l, r)\) 为 \([l, r]\) 这个区间的答案,可重复贡献问题就是对所有 \(R \ge L\),\(f(l, r)\) 可表示为 \(f(l, R)\) 与 \(f(L, r)\) 的合并。
考虑一个 \(\text{RMQ}\) 问题:
给定 \(n\) 个数,有 \(m\) 个询问,对于每个询问你需要回答区间 \([l, r]\) 中的最大值。
令 \(f(i, j)\) 表示区间 \([i, i + 2^j + 1]\) 的最大值,显然 \(f(i, 0) = a_i\)。
状态转移方程为:
对于每个询问 \([l, r]\),我们把它分成两个部分:\(f(l, l + 2^s - 1)\) 与 \(f(r - 2^s + 1, r)\),其中 $s = \left \lfloor \log_2 (r - l + 1) \right \rfloor $。
两个部分的结果的较大值就是答案。
建议预处理对数数组:\(\texttt{Log}_1 = 0\),\(\texttt{Log}_i = \texttt{Log}_{\left \lfloor \frac{i}{2} \right \rfloor} + 1\),时间复杂度 \(O(n)\)。
除了 \(\text{RMQ}\) 以外,还有其他的“可重复贡献问题”,例如“区间按位和”、“区间按位或”、“区间 \(\text{GCD}\)”,\(\text{ST}\) 表都能高效解决。
\(\text{ST}\) 表维护区间 \(\text{GCD}\) 的时间复杂度预处理 \(O(n \times (\log n + \log w))\),单次查询 \(O(\log w)\),其中 \(w\) 是值域。
最近公共祖先 LCA
定义
最近公共祖先简称 \(\text{LCA}\)(\(\text{Lowest Common Ancestor}\))。两个节点的最近公共祖先,就是这两个点的公共祖先里面,离根最远的那个。
为了方便,我们记某点集 \(S=\{v_1,v_2,\ldots,v_n\}\) 的最近公共祖先为 \(\text{LCA}(v_1,v_2,\ldots,v_n)\) 或 \(\text{LCA}(S)\)。
性质
本节 性质 部分内容翻译自 wcipeg,并做过修改。
- \(\text{LCA}(\{u\})=u\);
- \(u\) 是 \(v\) 的祖先,当且仅当 \(\text{LCA}(u,v)=u\);
- 如果 \(u\) 不为 \(v\) 的祖先并且 \(v\) 不为 \(u\) 的祖先,那么 \(u,v\) 分别处于 \(\text{LCA}(u,v)\) 的两棵不同子树中;
- 前序遍历中,\(\text{LCA}(S)\) 出现在所有 \(S\) 中元素之前,后序遍历中 \(\text{LCA}(S)\) 则出现在所有 \(S\) 中元素之后;
- 两点集并的最近公共祖先为两点集分别的最近公共祖先的最近公共祖先,即 \(\text{LCA}(A\cup B)=\text{LCA}(\text{LCA}(A), \text{LCA}(B))\);
- 两点的最近公共祖先必定处在树上两点间的最短路上;
- \(d(u,v)=h(u)+h(v)-2h(\text{LCA}(u,v))\),其中 \(d\) 是树上两点间的距离,\(h\) 代表某点到树根的距离。
求法
朴素算法
过程
可以每次找深度比较大的那个点,让它向上跳。显然在树上,这两个点最后一定会相遇,相遇的位置就是想要求的 \(\text{LCA}\)。
或者先向上调整深度较大的点,令他们深度相同,然后再共同向上跳转,最后也一定会相遇。
性质
朴素算法预处理时需要 \(\text{dfs}\) 整棵树,时间复杂度为 \(O(n)\),单次查询时间复杂度为 \(\Theta(n)\)。如果树满足随机性质,则时间复杂度与这种随机树的期望高度有关。
倍增算法
过程
倍增算法是最经典的 \(\text{LCA}\) 求法,他是朴素算法的改进算法。通过预处理 \(\text{fa}_{x,i}\) 数组,游标可以快速移动,大幅减少了游标跳转次数。\(\text{fa}_{x,i}\) 表示点 \(x\) 的第 \(2^i\) 个祖先。\(\text{fa}_{x,i}\) 数组可以通过 \(\text{dfs}\) 预处理出来。
现在我们看看如何优化这些跳转:
在调整游标的第一阶段中,我们要将 \(u,v\) 两点跳转到同一深度。我们可以计算出 \(u,v\) 两点的深度之差,设其为 \(y\)。通过将 \(y\) 进行二进制拆分,我们将 \(y\) 次游标跳转优化为「\(y\) 的二进制表示所含 1 的个数」次游标跳转。
在第二阶段中,我们从最大的 \(i\) 开始循环尝试,一直尝试到 \(0\)(包括 \(0\)),如果 \(\text{fa}_{u,i}\not=\text{fa}_{v,i}\),则 \(u\gets\text{fa}_{u,i},v\gets\text{fa}_{v,i}\),那么最后的 LCA 为 \(\text{fa}_{u,0}\)。
性质
倍增算法的预处理时间复杂度为 \(O(n \log n)\),单次查询时间复杂度为 \(O(\log n)\)。
另外倍增算法可以通过交换 fa 数组的两维使较小维放在前面。这样可以减少 \(\text{cache miss}\) 次数,提高程序效率。
例题:HDU 2586 How far away? 树上最短路查询。
可先求出 \(\text{LCA}\),再结合性质 \(7\) 进行解答。也可以直接在求 \(\text{LCA}\) 时求出结果。
参考代码:
#include <cstdio>
#include <cstring>
#include <vector>
#define MXN 40005
using namespace std;
std::vector<int> v[MXN];
std::vector<int> w[MXN];
int fa[MXN][31], cost[MXN][31], dep[MXN];
int n, m;
int a, b, c;
// dfs,用来为 lca 算法做准备。接受两个参数:dfs 起始节点和它的父亲节点。
void dfs(int root, int fno) {
// 初始化:第 2^0 = 1 个祖先就是它的父亲节点,dep 也比父亲节点多 1。
fa[root][0] = fno;
dep[root] = dep[fa[root][0]] + 1;
// 初始化:其他的祖先节点:第 2^i 的祖先节点是第 2^(i-1) 的祖先节点的第
// 2^(i-1) 的祖先节点。
for (int i = 1; i < 31; ++i) {
fa[root][i] = fa[fa[root][i - 1]][i - 1];
cost[root][i] = cost[fa[root][i - 1]][i - 1] + cost[root][i - 1];
}
// 遍历子节点来进行 dfs。
int sz = v[root].size();
for (int i = 0; i < sz; ++i) {
if (v[root][i] == fno) continue;
cost[v[root][i]][0] = w[root][i];
dfs(v[root][i], root);
}
}
// lca。用倍增算法算取 x 和 y 的 lca 节点。
int lca(int x, int y) {
// 令 y 比 x 深。
if (dep[x] > dep[y]) swap(x, y);
// 令 y 和 x 在一个深度。
int tmp = dep[y] - dep[x], ans = 0;
for (int j = 0; tmp; ++j, tmp >>= 1)
if (tmp & 1) ans += cost[y][j], y = fa[y][j];
// 如果这个时候 y = x,那么 x,y 就都是它们自己的祖先。
if (y == x) return ans;
// 不然的话,找到第一个不是它们祖先的两个点。
for (int j = 30; j >= 0 && y != x; --j) {
if (fa[x][j] != fa[y][j]) {
ans += cost[x][j] + cost[y][j];
x = fa[x][j];
y = fa[y][j];
}
}
// 返回结果。
ans += cost[x][0] + cost[y][0];
return ans;
}
void Solve() {
// 初始化表示祖先的数组 fa,代价 cost 和深度 dep。
memset(fa, 0, sizeof(fa));
memset(cost, 0, sizeof(cost));
memset(dep, 0, sizeof(dep));
// 读入树:节点数一共有 n 个,查询 m 次,每一次查找两个节点的 lca 点。
scanf("%d %d", &n, &m);
// 初始化树边和边权
for (int i = 1; i <= n; ++i) {
v[i].clear();
w[i].clear();
}
for (int i = 1; i < n; ++i) {
scanf("%d %d %d", &a, &b, &c);
v[a].push_back(b);
v[b].push_back(a);
w[a].push_back(c);
w[b].push_back(c);
}
// 为了计算 lca 而使用 dfs。
dfs(1, 0);
for (int i = 0; i < m; ++i) {
scanf("%d %d", &a, &b);
printf("%d\n", lca(a, b));
}
}
int main() {
int T;
scanf("%d", &T);
while (T--) Solve();
return 0;
}
Tarjan 算法
过程
\(\text{Tarjan}\) 算法是一种 离线算法,需要使用并查集记录某个结点的祖先结点。做法如下:
- 首先接受输入边(邻接链表)、查询边(存储在另一个邻接链表内)。查询边其实是虚拟加上去的边,为了方便,每次输入查询边的时候,将这个边及其反向边都加入到
queryEdge数组里。 - 然后对其进行一次 \(\text{DFS}\) 遍历,同时使用
visited数组进行记录某个结点是否被访问过、parent记录当前结点的父亲结点。 - 其中涉及到了 回溯思想,我们每次遍历到某个结点的时候,认为这个结点的根结点就是它本身。让以这个结点为根节点的 \(\text{DFS}\) 全部遍历完毕了以后,再将这个结点的根节点设置为这个结点的父一级结点。
- 回溯的时候,如果以该节点为起点,
queryEdge查询边的另一个结点也恰好访问过了,则直接更新查询边的 \(\text{LCA}\) 结果。 - 最后输出结果。
性质
\(\text{Tarjan}\) 算法需要初始化并查集,所以预处理的时间复杂度为 \(O(n)\)。
朴素的 \(\text{Tarjan}\) 算法处理所有 \(m\) 次询问的时间复杂度为 \(O(m \alpha(m+n, n) + n)\)。但是 Tarjan 算法的常数比倍增算法大。存在 \(O(m + n)\) 的实现。
注意:
并不存在「朴素 \(\text{Tarjan LCA}\) 算法中使用的并查集性质比较特殊,单次调用 find() 函数的时间复杂度为均摊 \(O(1)\)」这种说法。
以下的朴素 \(\text{Tarjan}\) 实现复杂度为 \(O(m \alpha(m+n, n) + n)\)。如果需要追求严格线性,可以参考 Gabow 和 Tarjan 于 1983 年的论文。其中给出了一种复杂度为 \(O(m + n)\) 的做法。
例题
例题 Luogu P3379【模板】最近公共祖先(LCA)。
参考代码:
#include<iostream>
using namespace std;
#define MAXN 500010
struct node {
int t, nex;
} e[MAXN << 1];
int head[MAXN], tot;
int n, m, s;
int depth[MAXN], fa[MAXN][30], lg[MAXN];
void add(int x, int y) {
e[++ tot].t = y;
e[tot].nex = head[x];
head[x] = tot;
return;
}
void dfs(int now, int fath) {
fa[now][0] = fath; depth[now] = depth[fath] + 1;
for(int i = 1; i <= lg[depth[now]]; i ++)
fa[now][i] = fa[fa[now][i - 1]][i - 1];
for(int i = head[now]; i; i = e[i].nex)
if(e[i].t != fath) dfs(e[i].t, now);
return;
}
int LCA(int x, int y) {
if(depth[x] < depth[y]) swap(x, y);
while(depth[x] > depth[y])
x = fa[x][lg[depth[x] - depth[y]] - 1];
if(x == y) return x;
for(int k = lg[depth[x]] - 1; k >= 0; k --)
if(fa[x][k] != fa[y][k]) x = fa[x][k], y = fa[y][k];
return fa[x][0];
}
int main() {
cin >> n >> m >> s;
for(int i = 1, x, y; i <= n - 1; i ++) {
cin >> x >> y;
add(x, y); add(y, x);
}
// 预处理 log_2(i) + 1 的值
for(int i = 1; i <= n; i ++)
lg[i] = lg[i - 1] + (1 << lg[i - 1] == i);
dfs(s, 0);
for(int i = 1, x, y; i <= m; i ++) {
cin >> x >> y;
cout << LCA(x, y) << "\n";
}
return 0;
}
树链剖分
树链剖分的思想及能解决的问题
树链剖分用于将树分割成若干条链的形式,以维护树上路径的信息。
具体来说,将整棵树剖分为若干条链,使它组合成线性结构,然后用其他的数据结构维护信息。
树链剖分(树剖/链剖)有多种形式,如 重链剖分,长链剖分 和用于 \(\text{Link/cut Tree}\) 的剖分(有时被称作「实链剖分」),大多数情况下(没有特别说明时),「树链剖分」都指「重链剖分」。
重链剖分可以将树上的任意一条路径划分成不超过 \(O(\log n)\) 条连续的链,每条链上的点深度互不相同(即是自底向上的一条链,链上所有点的 \(\text{LCA}\) 为链的一个端点)。
重链剖分还能保证划分出的每条链上的节点 \(\text{DFS}\) 序连续,因此可以方便地用一些维护序列的数据结构(如线段树)来维护树上路径的信息。
如:
- 修改 树上两点之间的路径上 所有点的值。
- 查询 树上两点之间的路径上 节点权值的 和/极值/其它(在序列上可以用数据结构维护,便于合并的信息)。
除了配合数据结构来维护树上路径信息,树剖还可以用来 \(O(\log n)\)(且常数较小)地求 \(\text{LCA}\)。在某些题目中,还可以利用其性质来灵活地运用树剖。
重链剖分
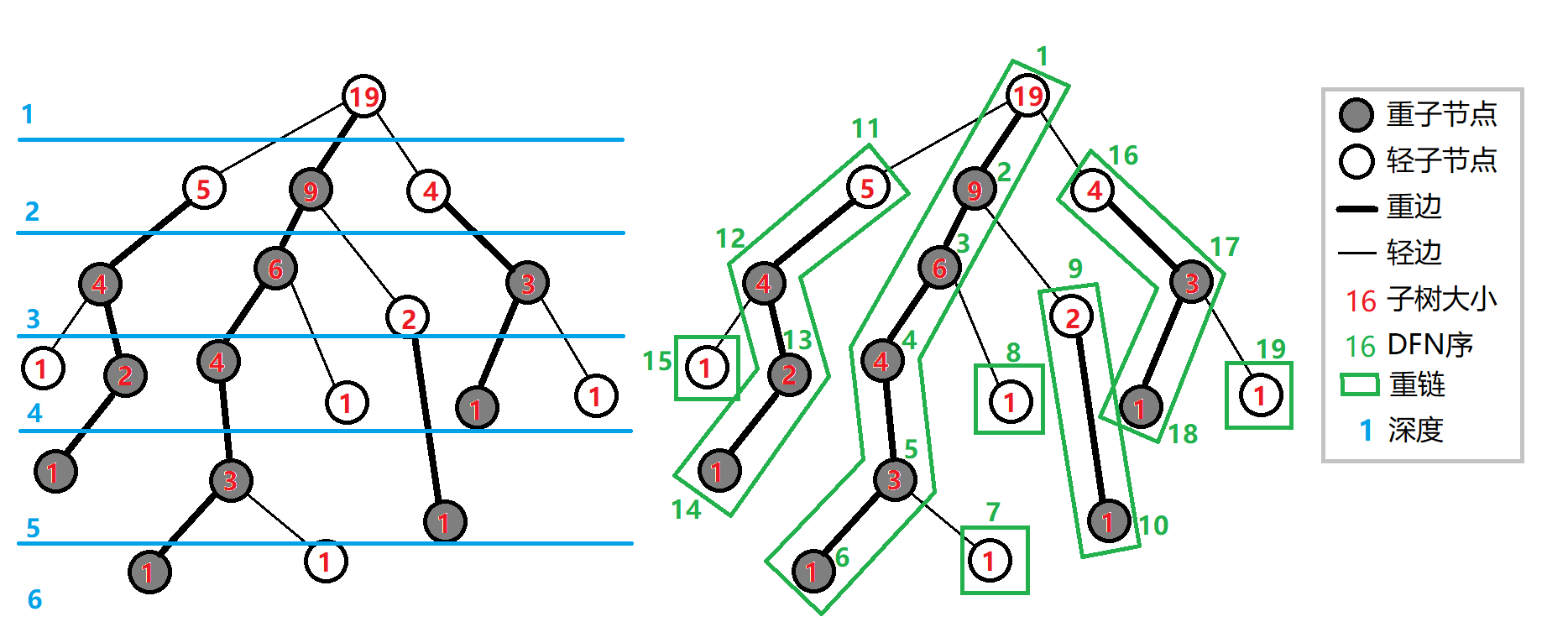
我们给出一些定义:
定义 重子节点 表示其子节点中子树最大的子结点。如果有多个子树最大的子结点,取其一。如果没有子节点,就无重子节点。
定义 轻子节点 表示剩余的所有子结点。
从这个结点到重子节点的边为 重边。
到其他轻子节点的边为 轻边。
若干条首尾衔接的重边构成 重链。
把落单的结点也当作重链,那么整棵树就被剖分成若干条重链。
如图:
实现
树剖的实现分两个 \(\text{DFS}\) 的过程。伪代码如下:
第一个 \(\text{DFS}\) 记录每个结点的父节点(\(\text{father}\))、深度(\(\text{deep}\))、子树大小(\(\text{size}\))、重子节点(\(\text{hson}\))。
第二个 \(\text{DFS}\) 记录所在链的链顶(\(\text{top}\),应初始化为结点本身)、重边优先遍历时的 \(\text{DFS}\) 序(\(\text{dfn}\))、\(\text{DFS}\) 序对应的节点编号(\(\text{rank}\))。
以下为代码实现。
我们先给出一些定义:
- \(fa(x)\) 表示节点 \(x\) 在树上的父亲。
- \(dep(x)\) 表示节点 \(x\) 在树上的深度。
- \(siz(x)\) 表示节点 \(x\) 的子树的节点个数。
- \(son(x)\) 表示节点 \(x\) 的 重儿子。
- \(top(x)\) 表示节点 \(x\) 所在 重链 的顶部节点(深度最小)。
- \(dfn(x)\) 表示节点 \(x\) 的 DFS 序,也是其在线段树中的编号。
- \(rnk(x)\) 表示 \(\text{DFS}\) 序所对应的节点编号,有 \(rnk(dfn(x))=x\)。
我们进行两遍 \(\text{DFS}\) 预处理出这些值,其中第一次 \(\text{DFS}\) 求出 \(fa(x)\),\(dep(x)\),\(siz(x)\),\(son(x)\),第二次 \(\text{DFS}\) 求出 \(top(x)\),\(dfn(x)\),\(rnk(x)\)。
void dfs1(int o) {
son[o] = -1;
siz[o] = 1;
for (int j = h[o]; j; j = nxt[j])
if (!dep[p[j]]) {
dep[p[j]] = dep[o] + 1;
fa[p[j]] = o;
dfs1(p[j]);
siz[o] += siz[p[j]];
if (son[o] == -1 || siz[p[j]] > siz[son[o]]) son[o] = p[j];
}
}
void dfs2(int o, int t) {
top[o] = t;
cnt++;
dfn[o] = cnt;
rnk[cnt] = o;
if (son[o] == -1) return;
dfs2(son[o], t); // 优先对重儿子进行 DFS,可以保证同一条重链上的点 DFS 序连续
for (int j = h[o]; j; j = nxt[j])
if (p[j] != son[o] && p[j] != fa[o]) dfs2(p[j], p[j]);
}
重链剖分的性质
树上每个节点都属于且仅属于一条重链。
重链开头的结点不一定是重子节点(因为重边是对于每一个结点都有定义的)。
所有的重链将整棵树 完全剖分。
在剖分时 重边优先遍历,最后树的 \(\text{DFS}\) 序上,重链内的 \(\text{DFS}\) 序是连续的。按 \(\text{DFN}\) 排序后的序列即为剖分后的链。
一颗子树内的 \(\text{DFS}\) 序是连续的。
可以发现,当我们向下经过一条 轻边 时,所在子树的大小至少会除以二。
因此,对于树上的任意一条路径,把它拆分成从 \(\text{LCA}\) 分别向两边往下走,分别最多走 \(O(\log n)\) 次,因此,树上的每条路径都可以被拆分成不超过 \(O(\log n)\) 条重链。
常见应用
路径上维护
用树链剖分求树上两点路径权值和,伪代码如下:
链上的 \(\text{DFS}\) 序是连续的,可以使用线段树、树状数组维护。
每次选择深度较大的链往上跳,直到两点在同一条链上。
同样的跳链结构适用于维护、统计路径上的其他信息。
子树维护
有时会要求,维护子树上的信息,譬如将以 \(x\) 为根的子树的所有结点的权值增加 \(v\)。
在 \(\text{DFS}\) 搜索的时候,子树中的结点的 \(\text{DFS}\) 序是连续的。
每一个结点记录 \(\text{bottom}\) 表示所在子树连续区间末端的结点。
这样就把子树信息转化为连续的一段区间信息。
求最近公共祖先
不断向上跳重链,当跳到同一条重链上时,深度较小的结点即为 \(\text{LCA}\)。
向上跳重链时需要先跳所在重链顶端深度较大的那个。
参考代码:
int lca(int u, int v) {
while (top[u] != top[v]) {
if (dep[top[u]] > dep[top[v]])
u = fa[top[u]];
else
v = fa[top[v]];
}
return dep[u] > dep[v] ? v : u;
}
怎么有理有据地卡树剖
一般情况下树剖的 \(O(\log n)\) 常数不满很难卡,如果要卡只能建立二叉树深度低。
于是我们可以考虑折中方案。
我们建立一颗 \(\sqrt{n}\) 个节点的二叉树。对于每个节点到其儿子的边,我们将其替换成一条长度为 \(\sqrt{n}\) 的链。
这样子我们可以将随机询问轻重链切换次数卡到平均 \(\frac{\log n}{2}\) 次,同时有 \(O(\sqrt{n} \log n)\) 的深度。
加上若干随机叶子看上去可以卡树剖。但是树剖常数小有可能卡不掉。
树链剖分求 \(\text{LCA}\) 参考代码:
#include <bits/stdc++.h>
using namespace std;
const int N = 5e5 + 10;
int n, m, s;
vector<int> G[N];
int fa[N], dep[N], siz[N], son[N];
int top[N], dfn[N], rnk[N], id;
void dfs(int u, int p = 0) { //parent
fa[u] = p;
dep[u] = dep[p] + 1;
siz[u] = 1;
son[u] = 0;
for(int v: G[u])
if(v != p) {
dfs(v, u);
siz[u] += siz[v];
if(siz[v] > siz[son[u]]) son[u] = v;
}
return;
}
void dfs2(int u, int t) { //top
top[u] = t;
dfn[u] = ++id;
rnk[id] = u;
if(!son[u]) return;
dfs2(son[u], t);
for(int v: G[u])
if(v != fa[u] && v != son[u]) dfs2(v, v);
return;
}
int LCA(int u, int v) {
while(top[u] != top[v]) {
if(dep[top[u]] < dep[top[v]]) swap(u, v);
u = fa[top[u]];
}
return dep[u] < dep[v] ? u : v;
}
int main() {
cin >> n >> m >> s;
for (int i = 1, u, v; i < n; i ++) {
cin >> u >> v;
G[u].push_back(v); G[v].push_back(u);
}
dfs(s); dfs2(s, s);
for(int i = 0, u, v; i < m; i ++) {
cin >> u >> v;
cout << LCA(u, v) << endl;
}
return 0;
}
长链剖分
长链剖分本质上就是另外一种链剖分方式。
定义 重子节点 表示其子节点中子树深度最大的子结点。如果有多个子树最大的子结点,取其一。如果没有子节点,就无重子节点。
定义 轻子节点 表示剩余的子结点。
从这个结点到重子节点的边为 重边。
到其他轻子节点的边为 轻边。
若干条首尾衔接的重边构成 重链。
把落单的结点也当作重链,那么整棵树就被剖分成若干条重链。
如图(这种剖分方式既可以看成重链剖分也可以看成长链剖分):
长链剖分实现方式和重链剖分类似,这里就不再展开。
常见应用
首先,我们发现长链剖分从一个节点到根的路径的轻边切换条数是 \(\sqrt{n}\) 级别的。
如何构造数据将轻重边切换次数卡满
我们可以构造这么一颗二叉树 T:
假设构造的二叉树参数为 \(D\)。
若 \(D \neq 0\), 则在左儿子构造一颗参数为 \(D-1\) 的二叉树,在右儿子构造一个长度为 \(2D-1\) 的链。
若 \(D = 0\), 则我们可以直接构造一个单独叶节点,并且结束调用。
这样子构造一定可以将单独叶节点到根的路径全部为轻边且需要 \(D^2\) 级别的节点数。
取 \(D=\sqrt{n}\) 即可。
长链剖分优化 DP
一般情况下可以使用长链剖分来优化的 \(\text{DP}\) 会有一维状态为深度维。
我们可以考虑使用长链剖分优化树上 \(\text{DP}\)。
具体的,我们每个节点的状态直接继承其重儿子的节点状态,同时将轻儿子的 \(\text{DP}\) 状态暴力合并。
CF1009F
我们设 \(f_{i,j}\) 表示在子树 \(i\) 内,和 \(i\) 距离为 \(j\) 的点数。
直接暴力转移时间复杂度为 \(O(n^2)\)
我们考虑每次转移我们直接继承重儿子的 \(\text{DP}\) 数组和答案,并且考虑在此基础上进行更新。
首先我们需要将重儿子的 \(\text{DP}\) 数组前面插入一个元素 1, 这代表着当前节点。
然后我们将所有轻儿子的 \(\text{DP}\) 数组暴力和当前节点的 \(\text{DP}\) 数组合并。
注意到因为轻儿子的 \(\text{DP}\) 数组长度为轻儿子所在重链长度,而所有重链长度和为 \(n\)。
也就是说,我们直接暴力合并轻儿子的总时间复杂度为 \(O(n)\)。
注意,一般情况下 \(\text{DP}\) 数组的内存分配为一条重链整体分配内存,链上不同的节点有不同的首位置指针。
\(\text{DP}\) 数组的长度我们可以根据子树最深节点算出。
例题参考代码:
#include <bits/stdc++.h>
using namespace std;
const int N = 1000005;
struct edge {
int to, next;
} e[N * 2];
int head[N], tot, n;
int d[N], fa[N], mx[N];
int *f[N], g[N], mxp[N];
int dfn[N];
void add(int x, int y) {
e[++tot] = (edge){y, head[x]};
head[x] = tot;
}
void dfs1(int x) { // 第一次插入一个1
d[x] = 1;
for (int i = head[x]; i; i = e[i].next)
if (e[i].to != fa[x]) {
fa[e[i].to] = x;
dfs1(e[i].to);
d[x] = max(d[x], d[e[i].to] + 1);
if (d[e[i].to] > d[mx[x]]) mx[x] = e[i].to;
}
}
void dfs2(int x) { // 第二次合并
dfn[x] = ++*dfn;
f[x] = g + dfn[x];
if (mx[x]) dfs2(mx[x]);
for (int i = head[x]; i; i = e[i].next)
if (e[i].to != fa[x] && e[i].to != mx[x]) dfs2(e[i].to);
}
void getans(int x) { // 暴力合并算答案
if (mx[x]) {
getans(mx[x]);
mxp[x] = mxp[mx[x]] + 1;
}
f[x][0] = 1;
if (f[x][mxp[x]] <= 1) mxp[x] = 0;
for (int i = head[x]; i; i = e[i].next)
if (e[i].to != fa[x] && e[i].to != mx[x]) {
getans(e[i].to);
int len = d[e[i].to];
for (int j = 0; j <= len - 1; j++) {
f[x][j + 1] += f[e[i].to][j];
if (f[x][j + 1] > f[x][mxp[x]]) mxp[x] = j + 1;
if (f[x][j + 1] == f[x][mxp[x]] && j + 1 < mxp[x]) mxp[x] = j + 1;
}
}
}
int main() {
scanf("%d", &n);
for (int i = 1; i < n; i++) {
int x, y;
scanf("%d%d", &x, &y);
add(x, y);
add(y, x);
}
dfs1(1);
dfs2(1);
getans(1);
for (int i = 1; i <= n; i++) printf("%d\n", mxp[i]);
}
当然长链剖分优化 \(\text{DP}\) 技巧非常多,包括但是不仅限于打标记等等。这里不再展开。
参考 租酥雨的博客。
长链剖分求 k 级祖先
即询问一个点向父亲跳 \(k\) 次跳到的节点。
首先我们假设我们已经预处理了每一个节点的 \(2^i\) 级祖先。
现在我们假设我们找到了询问节点的 \(2^i\) 级祖先满足 \(2^i \le k < 2^{i+1}\)。
我们考虑求出其所在重链的节点并且按照深度列入表格。假设重链长度为 \(d\)。
同时我们在预处理的时候找到每条重链的根节点的 \(1\) 到 \(d\) 级祖先,同样放入表格。
根据长链剖分的性质,\(k-2^i \le 2^i \leq d\), 也就是说,我们可以 \(O(1)\) 在这条重链的表格上求出的这个节点的 \(k\) 级祖先。
预处理需要倍增出 \(2^i\) 次级祖先,同时需要预处理每条重链对应的表格。
预处理复杂度 \(O(n\log n)\), 询问复杂度 \(O(1)\)。
练习
「洛谷 P3379」【模板】最近公共祖先(LCA)(树剖求 LCA 无需数据结构,可以用作练习)
「JLOI2014」松鼠的新家(当然也可以用树上差分)
「POI2014」Hotel 加强版(长链剖分优化 DP)
攻略(长链剖分优化贪心)
本文来自博客园,作者:So_noSlack,转载请注明原文链接:https://www.cnblogs.com/So-noSlack/p/18291034

 浙公网安备 33010602011771号
浙公网安备 33010602011771号