第二节 贪心
引入
贪心算法(英语:greedy algorithm),是用计算机来模拟一个「贪心」的人做出决策的过程。这个人十分贪婪,每一步行动总是按某种指标选取最优的操作。而且他目光短浅,总是只看眼前,并不考虑以后可能造成的影响。
可想而知,并不是所有的时候贪心法都能获得最优解,所以一般使用贪心法的时候,都要确保自己能证明其正确性。
适用范围
贪心算法在有最优子结构的问题中尤为有效。最优子结构的意思是问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。
证明
贪心算法有两种证明方法:反证法和归纳法。一般情况下,一道题只会用到其中的一种方法来证明。
- 反证法:如果交换方案中任意两个元素/相邻的两个元素后,答案不会变得更好,那么可以推定目前的解已经是最优解了。
- 归纳法:先算得出边界情况(例如 \(n\) = 1)的最优解 \(F_1\),然后再证明:对于每个 \(n\),\(F_{n+1}\) 都可以由 \(F_{n}\) 推导出结果。
题目练习
A. 异或与乘积
时间:1s 空间:256M
题目描述:
小信有 \(n\) 个数的序列 \(a_i\)。现在他想做若干次操作,每次选择两个数,把他们异或起来,之后删除这两个数,并把他们异或后的结果加入序列。
小信进行若干次操作后,会把序列中剩下的数全部乘起来。小信想知道最后的结果最大是多少。注意,小信最多操作 \(n−1\) 次,在这之后序列会只剩下一个数。
由于答案可能很大,输出对 \(1000000007\) 取模后的结果。
输入格式:
第一行包含一个整数 \(n\)。
第二行包含 \(n\) 个整数 \(a_i\)。
输出格式:
输出一行表示答案对 \(1000000007\) 取模后的结果。
样例1输入:
4
1 2 1 2
样例1输出:
9
样例2输入:
2
3 3
样例2输出:
9
样例3输入:
2
1 3
样例3输出:
3
约定:
有 \(30\%\) 的数据,\(2 \le n \le 5\), \(1 \le a_i \le 10^9\)。
对于 \(100\%\) 的数据,\(2 \le n \le 10^5\), \(1 \le a_i \le 10^9\)。
分析:
我们需要找到两个数 \(a_i\) ^ \(a_j\) > \(a_i\) * \(a_j\), 去进行异或操作才对整体有帮助。
经过一些简单数学思想可证, 这两个数需满足以下两个要求 :
-
有一个数为
1 -
另一个数为
偶数
有了这个思路, 这道题就迎刃而解了。
点击查看代码
#define MOD 1000000007
long long n, a[100005];
long long ans = 1, num = 0, sum = 0;
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> a[i];
if (a[i] == 1) num++;
}
sort(a + 1, a + n + 1);
for (int i = 1; i <= n; i++) {
if (a[i] == 1) continue;
if (a[i] % 2 == 0 && num) {
ans *= 1 ^ a[i];
ans %= MOD;
num--;
}
else ans *= a[i], ans %= MOD;
}
cout << ans;
return 0;
}
B. 平衡后缀
题目描述
给定长度为 \(n\) 的字符串 \(S\) 和一个整数 \(k\)。求 \(S\) 的任意一种重排是否是“好的”。
一个字符串是“好的”,当且仅当:它的任意一个后缀都是“平衡的”。
一个字符串是“平衡的”,当且仅当:它的任意两个字符出现次数之差不超过 k。
注意:原串中没出现的字符不需要考虑,原串中出现过的字符在每一个后缀中都需考虑。
注意:单独一个字符构成的字符串也是“平衡的”。
如果不存在某个重排是“好的”,则输出-1。
如果存在,则输出字典序最小的重排。
输入格式
第一行一个整数 \(T\) 代表数据组数。
每组数据第一行两个整数代表 \(n\) 和 \(k\),第二行一个只包含小写字母的字符串代表 \(S\)。
输出格式
每组数据输出一行,代表答案。
样例输入
4
3 1
aaa
4 2
baba
4 1
babb
7 2
abcbcac
样例输出
aaa
aabb
-1
abcabcc
数据规模
\(1 \le T \le 2000\),\(1 \le n \le 10^5\),\(1 \le k \le n\),\(∑n \le 2 × 10^5\)。
点击查看代码
struct node {
int vul;
char num;
} a[30];
int T, n, k, maxn = -1e9, minn = 1e9;
string str, s;
//bool cmp(node x, node y) { return x.vul < y.vul; }
int main() {
cin >> T;
while (T--) {
maxn = -1e9, minn = 1e9;
s = "";
for (int i = 0; i < 26; i++) a[i].vul = 0;
cin >> n >> k >> str;
for (int i = 0; i < n; i++) a[str[i] - 'a'].vul++;
for (int i = 0; i < 26; i++) {
a[i].num = char(i + 'a');
maxn = max(maxn, a[i].vul);
if(a[i].vul != 0) minn = min(minn, a[i].vul);
}
if (maxn - minn > k) { cout << "-1\n"; continue; }
//sort(a, a + 26, cmp);
for (int i = 0; i < n; i++) {
for (int j = 0; j < 26; j++) {
if (a[j].vul == 0) continue;
if (maxn - a[j].vul + 1 > k) continue;
s += a[j].num;
a[j].vul--;
maxn = -1e9;
for (int k = 0; k < 26; k++) maxn = max(maxn, a[k].vul);
break;
}
}
cout << s << endl;
}
return 0;
}
C. 国王游戏
题目描述
恰逢 H 国国庆,国王邀请 \(n\) 位大臣来玩一个有奖游戏。首先,他让每个大臣在左、右手上面分别写下一个整数,国王自己也在左、右手上各写一个整数。然后,让这 \(n\) 位大臣排成一排,国王站在队伍的最前面。排好队后,所有的大臣都会获得国王奖赏的若干金币,每位大臣获得的金币数分别是:排在该大臣前面的所有人的左手上的数的乘积除以他自己右手上的数,然后向下取整得到的结果。
国王不希望某一个大臣获得特别多的奖赏,所以他想请你帮他重新安排一下队伍的顺序,使得获得奖赏最多的大臣,所获奖赏尽可能的少。注意,国王的位置始终在队伍的最前面。
输入格式
第一行包含一个整数 \(n\),表示大臣的人数。
第二行包含两个整数 \(a\) 和 \(b\),之间用一个空格隔开,分别表示国王左手和右手上的整数。
接下来 \(n\) 行,每行包含两个整数 \(a\) 和 \(b\),之间用一个空格隔开,分别表示每个大臣左手和右手上的整数。
输出格式
一个整数,表示重新排列后的队伍中获奖赏最多的大臣所获得的金币数。
样例输入 #1
3
1 1
2 3
7 4
4 6
样例输出 #1
2
输入输出样例说明
按 \(1\)、\(2\)、\(3\) 这样排列队伍,获得奖赏最多的大臣所获得金币数为 \(2\);
按 \(1\)、\(3\)、\(2\) 这样排列队伍,获得奖赏最多的大臣所获得金币数为 \(2\);
按 \(2\)、\(1\)、\(3\) 这样排列队伍,获得奖赏最多的大臣所获得金币数为 \(2\);
按$ 2$、\(3\)、$1 $这样排列队伍,获得奖赏最多的大臣所获得金币数为 \(9\);
按 \(3\)、\(1\)、$2 $这样排列队伍,获得奖赏最多的大臣所获得金币数为 \(2\);
按$ 3$、\(2\)、\(1\) 这样排列队伍,获得奖赏最多的大臣所获得金币数为 \(9\)。
因此,奖赏最多的大臣最少获得 \(2\) 个金币,答案输出 \(2\)。
数据范围
对于 \(20\%\) 的数据,有 \(1≤ n≤ 10,0 < a,b < 8\);
对于 \(40\%\) 的数据,有$ 1≤ n≤20,0 < a,b < 8$;
对于 \(60\%\) 的数据,有 \(1≤ n≤100\);
对于 \(60\%\) 的数据,保证答案不超过 \(10^9\);
对于 \(100\%\) 的数据,有 \(1 ≤ n ≤1,000,0 < a,b < 10000\)。
分析

点击查看代码
#include<cstdio>
#include<algorithm>//用到sort
#include<cstring>//用到memset
using namespace std;
const int MAXN=1010,MAXM=10010;//注意高精数组开到10000
struct Node{//一个人
int l,r;
}a[MAXN];
int pro[MAXM],ans[MAXM],tmp[MAXM];//左手乘积,答案,临时数组
int read(){//快读
int x=0,f=1;//记录数和符号
char c=getchar();//读入字符
while(c<'0'||c>'9'){//只要不是数
if(c=='-') f=-1;//是负号就记录
c=getchar();
}
while(c>='0'&&c<='9'){//只要是数
x=x*10+c-'0';//挪位再加
c=getchar();
}
return x*f;//返回数乘符号
}
bool cmp(Node aa,Node bb){//排序的比较函数
return aa.l*aa.r<bb.l*bb.r;//按左右手数的乘积从小到大
}
void copy(int *aa,int *bb){//复制
for(int i=0;i<MAXM;i++) aa[i]=bb[i];
}
bool more(int *aa,int *bb){//比较
for(int i=MAXM-1;i>=0;i--){
if(aa[i]>bb[i]) return 1;
if(aa[i]<bb[i]) return 0;
}
return 0;//注意这里也要写上,写0写1随便
}
void times(int *aa,int num){//乘法
for(int i=MAXM-2;i>=0;i--) aa[i]*=num;//先乘
for(int i=0;i<MAXM-1;i++){//再进位
aa[i+1]+=(aa[i]/10);//先加前一位
aa[i]%=10;//在处理这一位
}
}
void div(int *aa,int *bb,int num){//除法
memset(bb,0,sizeof(bb));//赋为0
int x=0;
for(int i=MAXM-1;i>=0;i--){//从高位到低位
x=x*10+aa[i];//挪位再加
bb[i]=x/num;//记录
x%=num;//模上
}
}
void print(int *aa){//输出
bool flag=0;//记录是否能输出
for(int i=MAXM-1;i>=0;i--){
if(!flag){//如果不能
if(aa[i]) flag=1;//找到第一个不是0的位,可以输出了
else continue;//还是不能
}
printf("%d",aa[i]);//输出,不用空格或换行
}
}
int main(){//主函数
int n=read();
for(int i=0;i<=n;i++) a[i].l=read(),a[i].r=read();
sort(a+1,a+n+1,cmp);//排序
pro[0]=1;//注意乘积数组初始值为1
for(int i=0;i<=n;i++){//注意从0开始,国王
div(pro,tmp,a[i].r);//先除到tmp上
if(more(tmp,ans)) copy(ans,tmp);//比较,满足就复制
times(pro,a[i].l);//自乘
}
print(ans);
return 0;
}
以上题解复制于洛谷, 在此声明 qwq(因为我没写高精)
D. CCC
时间:1s 空间:256M
题目描述:
\(C\) 是一个变量,一开始 \(C = 0\),给你包含 \(n\) 个数的 \(a\) 数组,取其中任意 \(k\) 个数的排列\(a_1\), \(a_2\),..., \(a_k\),并依次运算 \(C = (C + a_i) / 2\).
你的任务是使得最终的 \(C\) 尽可能大
输入格式:
第一行两个数 \(n\) \(k\) (\(1 \le k \le n \le 100\))
第二行n个数,\(a_1\), \(a_2\),...,\(a_k\)(\(1 \le a_i \le 5000\))
输出格式:
输出 \(C\),保留 \(5\) 位小数
样例输入1:
2 2
1000 1500
样例输出1:
1000.00000
样例输入2:
2 1
1000 1500
样例输出2:
750.00000
样例输入3:
10 5
2604 2281 3204 2264 2200 2650 2229 2461 2439 2211
样例输出3:
2820.03125
点击查看代码
double C;
int n, k, a[105];
int main() {
cin >> n >> k;
for (int i = 1; i <= n; i++) cin >> a[i];
sort(a + 1, a + n + 1);
for (int i = n - k + 1; i <= n; i++) C = (C + a[i]) / 2;
printf("%0.5lf", C);
return 0;
}
E. 飞刀传承
时间:1s 空间:256M
题目描述:
李家自古以来就是飞刀名门,每一任家主都唤作小李。这一代的小李更是青出于蓝,将祖传的飞刀绝技使得出神入化,年纪轻轻便继承了李家祖传的招式,担下了家主之位。不料有日凶兽来袭,李家满门几尽被灭,只剩少数流落在外的弟子得以幸存。他一度想要自尽,却因李家飞刀绝技不能在他手上断绝的信念支撑了下来,残余一口气。现在他将飞刀之术传于你,希望道力高深的你能够帮助他斩灭凶兽。将来遇到漂泊在外的李家弟子能够将飞刀绝技传承下去。
现在你手里有 \(n\) 把刀,每把刀可飞可砍,对于第 \(i\) 把刀,
如果你用刀砍,将会给凶兽造成 \(x_i\) 点伤害
如果你使用飞刀之术,将会给凶兽造成 \(y_i\) 点伤害,但飞出去之后,这把刀就没了
凶兽的血量为 \(h\),问如果将凶兽消灭最少需要几次操作。
输入格式:
第一行输入两个整数,\(n\),\(h\) (\(1 \le n \le 10^5\), \(1 \le h \le 10^9\))
接下去 \(n\) 行,每行两个整数 \(a_i\), \(b_i\) 分别代表砍的伤害和飞的伤害。(\(1 \le a_i \le b_i \le 10^9\))
输出格式:
输出一行一个整数,代表最少需要几次操作。
样例输入1:
1 10
3 5
样例输出1:
3
样例输入2:
2 10
3 5
2 6
样例输出2:
2
点击查看代码
struct node {
bool x = false, y = false;
int num, i;
} a[200005];
int n, h, ans = 0, sum;
bool cmp(node x, node y) { return x.num > y.num; }
int main() {
cin >> n >> h;
for (int i = 1; i <= n; i++) {
cin >> a[i].num >> a[i + n].num;
a[i].x = true; a[i + n].y = true;
}
sort(a + 1, a + 2 * n + 1, cmp);
//for (int i = 1; i <= 2 * n; i++) cout << a[i].num << " ";
for (int i = 1; i <= 2 * n; i++) {
if (h <= 0) break;
if (a[i].x) { sum = i; break; }
if (a[i].y) h -= a[i].num, ans++;
}
//cout << sum << " " << ans << " ";
if(h > 0) ans += (h + a[sum].num - 1) / a[sum].num;
cout << ans;
return 0;
}
F. 奶牛玩杂技
题目背景
Farmer John 养了 \(N\) 头牛,她们已经按 \(1 ∼ N\) 依次编上了号。FJ 所不知道的是,他的所有牛都梦想着从农场逃走,去参加马戏团的演出。可奶牛们很快发现她们那笨拙的蹄子根本无法在钢丝或晃动的的秋千上站稳(她们还尝试过把自己装在大炮里发射出去,但可想而知,结果是悲惨的) 。最终,她们决定练习一种最简单的杂技:把所有牛都摞在一起, 比如说, 第一头牛站在第二头的身上, 同时第二头牛又站在第三头牛的身上...最底下的是第 \(N\) 头牛。
题目描述
每头牛都有自己的体重以及力量,编号为 \(i\) 的奶牛的体重为 \(W_i\),力量为 \(S_i\)。
当某头牛身上站着另一些牛时它就会在一定程度上被压扁,我们不妨把它被压扁的程度叫做它的压扁指数。对于任意的牛,她的压扁指数等于摞在她上面的所有奶牛的总重(当然不包括她自己)减去它的力量。奶牛们按照一定的顺序摞在一起后, 她们的总压扁指数就是被压得最扁的那头奶牛的压扁指数。
你的任务就是帮助奶牛们找出一个摞在一起的顺序,使得总压扁指数最小。
输入格式
第一行一个整数 \(N\)。
接下来 \(N\) 行,每行两个整数 \(W_i\) 和 \(S_i\)。
输出格式
一行一个整数表示最小总压扁指数。
样例输入 #1
3
10 3
2 5
3 3
样例输出 #1
2
提示
对于 \(100\%\) 的数据,\(1 \le N \le 5 × 10^4\),\(1 \le W_i \le 10^4\),\(1 \le S_i \le 10^9\)。
点击查看代码
struct node {
int w, s;
long long num;
} a[50005];
long long n, ans = -1e9;
bool cmp(node x, node y) { return x.w + x.s > y.w + y.s; }
int main() {
cin >> n;
for (int i = 1; i <= n; i++) cin >> a[i].w >> a[i].s;
sort(a + 1, a + n + 1, cmp);
for (int i = 1; i <= n; i++) {
for (int j = i + 1; j <= n; j++) a[i].num += a[j].w;
a[i].num -= a[i].s;
ans = max(ans, a[i].num);
}
cout << ans;
return 0;
}
G. 货仓选址
时间:0.2s 空间:64M
题目描述
在一条数轴上有 \(N\) 家商店,他们的坐标分别为 \(A_1 − A_N\)。现在需要在数轴上建立一家货仓,每天清晨,从货仓到每家商店都要运送一车商品。为了提高效率,求把货仓建在何处,可以使得货仓到每家商店的距离之和最小,输出最短距离之和。
输入描述
第一行输入一个数 \(N\)。(\(1 \le N \le 10^5\))
接下来一行,输入 \(N\) 个数,表示商店的坐标。
输出描述
输出最短距离之和。
样例输入
5
1 3 5 6 10
样例输出
12
点击查看代码
int n, a[100005], ans1, ans2;
int main() {
cin >> n;
for (int i = 1; i <= n; i++) cin >> a[i];
sort(a + 1, a + n + 1);
if (n % 2) {
int num = n / 2 + 1;
for (int i = 1; i < num; i++) ans1 += a[i];
for (int i = num + 1; i <= n; i++) ans2 += a[i];
cout << ans2 - ans1;
}
else {
int num = n / 2;
for (int i = 1; i <= num; i++) ans1 += a[i];
for (int i = num + 1; i <= n; i++) ans2 += a[i];
cout << ans2 - ans1;
}
return 0;
}
H. 替换字母
时间:1s 空间:256M
题目描述:
有长度为 \(n\) 的字符串,仅包含小写字母。
小信想把字符串变成只包含一种字母。他每次可以选择一种字符 \(c\),然后把长度最多为 \(m\) 的子串中的字符都替换成 \(c\)。
小信想知道最少需要操作几次能让字符串只包含一种字母。
输入格式:
第一行包含两个整数 \(n\), \(m\)。
第二行包含一个长度为 \(n\) 的字符串,只有小写字符。
输出格式:
对于每组测试数据,输出一个整数表示答案。
样例1输入:
5 4
abcab
样例1输出:
1
样例2输入:
5 3
abcab
样例2输出:
2
约定与提示:
对于 \(100\%\) 的数据,\(1 \le m \le n \le 2 * 10^5\)。
对于样例1:把子串 \([1,4]\) 中的字符都变成 '\(b\)',或者把子串 \([2,5]\) 中的字符都变成 '\(a\)'。
点击查看代码
int n, k, ans = 1e9, num = 0;
string str;
int main() {
cin >> n >> k >> str;
for (int i = 0; i < 26; i++) {
char s = i + 'a';
num = 0;
for (int j = 0; j < n; j++) {
if (str[j] == s) continue;
j += k - 1;
num++;
}
ans = min(ans, num);
}
cout << ans;
return 0;
}
I. 排座椅
时间限制:1S 空间限制: 128M
题目描述
上课的时候总有一些同学和前后左右的人交头接耳,这是令小学班主任十分头疼的一件事情。不过,班主任小雪发现了一些有趣的现象,当同学们的座次确定下来之后,只有有限的D对同学上课时会交头接耳。同学们在教室中坐成了 \(M\) 行 \(N\) 列,坐在第 \(i\) 行第 \(j\) 列的同学的位置是(\(i\),\(j\)),为了方便同学们进出,在教室中设置了 \(K\) 条横向的通道,\(L\) 条纵向的通道。于是,聪明的小雪想到了一个办法,或许可以减少上课时学生交头接耳的问题:她打算重新摆放桌椅,改变同学们桌椅间通道的位置,因为如果一条通道隔开了两个会交头接耳的同学,那么他们就不会交头接耳了。
请你帮忙给小雪编写一个程序,给出最好的通道划分方案。在该方案下,上课时交头接耳的学生对数最少。
输入格式:
输入文件第一行,有5各用空格隔开的整数,分别是 \(M\),\(N\),\(K\),\(L\),\(D\)(\(2 \le N, M \le 1000\),\(0 \le K < M\),\(0 \le L < N\),\(D \le 2000\))。
接下来 \(D\) 行,每行有 \(4\) 个用空格隔开的整数,第 \(i\) 行的 \(4\) 个整数 \(X_i\),\(Y_i\),\(P_i\),\(Q_i\),表示坐在位置(\(X_i\),\(Y_i\)) 与 (\(P_i\),\(Q_i\))的两个同学会交头接耳(输入保证他们前后相邻或者左右相邻)。
输入数据保证最优方案的唯一性。
输出格式:
输出文件共两行。
第一行包含 \(K\) 个整数,\(a_1, a_2……a_K\),表示第 \(a_1\) 行和 \(a_1 + 1\) 行之间、第 \(a_2\) 行和第 \(a_2 + 1\) 行之间、…、第 \(a_K\) 行和第 \(a_K + 1\) 行之间要开辟通道,其中 \(a_i < a_i + 1\),每两个整数之间用空格隔开(行尾没有空格)。
第二行包含 \(L\) 个整数,\(b_1, b_2……b_k\),表示第 \(b_1\) 列和 \(b_1 + 1\) 列之间、第 \(b_2\) 列和第 \(b_2 + 1\) 列之间、…、第 \(b_L\) 列和第 \(b_L + 1\) 列之间要开辟通道,其中 \(b_i < b_i + 1\),每两个整数之间用空格隔开(行尾没有空格)。
样例输入:
4 5 1 2 3
4 2 4 3
2 3 3 3
2 5 2 4
样例输出:
2
2 4
提示:

上图中用符号*、※、+ 标出了3对会交头接耳的学生的位置,图中3条粗线的位置表示通道,图示的通道划分方案是唯一的最佳方案。
点击查看代码
struct node {
int n, p;
} k[1005], l[1005];
bool cmp(node x, node y) { return x.n > y.n; }
bool cmp1(node x, node y) { return x.p < y.p; }
int d, n, m, p, q, x1, x2, y3, y2;
int main() {
cin >> m >> n >> p >> q >> d;
for (int i = 1; i <= d; i++) {
cin >> x1 >> y3 >> x2 >> y2;
if (x1 == x2) { l[min(y3, y2)].p = min(y3, y2); l[min(y3, y2)].n++; }
else { k[min(x1, x2)].p = min(x1, x2); k[min(x1, x2)].n++; }
}
sort(l + 1, l + n + 1, cmp);
sort(k + 1, k + m + 1, cmp);
sort(l + 1, l + q + 1, cmp1);
sort(k + 1, k + p + 1, cmp1);
for (int i = 1; i <= p; i++) cout << k[i].p << " ";
cout << endl;
for (int i = 1; i <= q; i++) cout << l[i].p << " ";
return 0;
}
初赛内容 : 进制与信息编码
进制
- 字母表示进制
| 进制 | 表示 |
|---|---|
| 二进制 | B |
| 八进制 | O |
| 十进制 | D |
| 十六进制 | H |
- 表示
- 十进制: 都是以0-9这九个数字组成,不能以0开头。
- 二进制: 由0和1两个数字组成。
- 八进制: 由0-7数字组成,为了区分与其他进制的数字区别,开头都是以0开始。
- 十六进制:由0-9和A-F组成。为了区分于其他数字的区别,开头都是以0x开始。
如:\(027\) 表示 八进制下的 \(27\)
- 进制转换
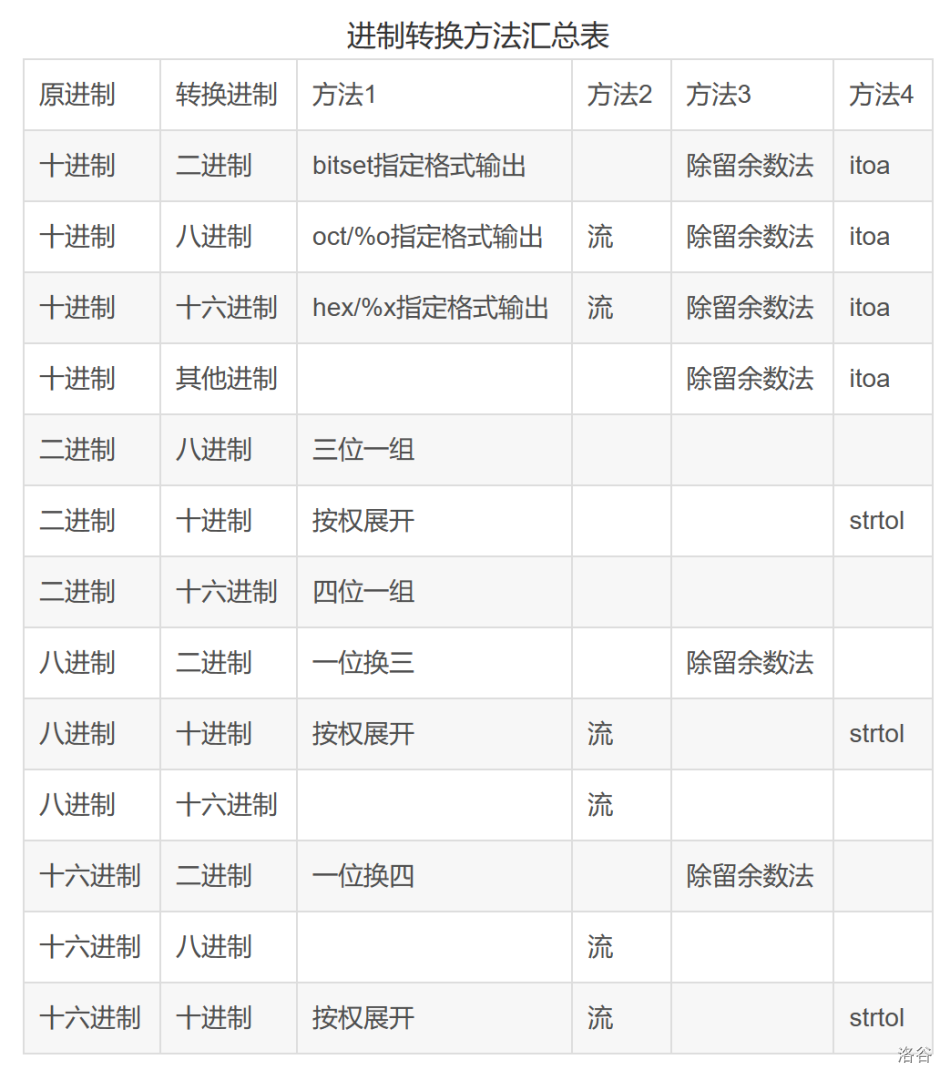
进制转换是人们利用符号来计数的方法。进制转换由一组数码符号和两个基本因素"基数"与"位权"构成。基数是指,进位计数制中所采用的数码(数制中用来表示"量"的符号)的个数。位权是指,进位制中每一固定位置对应的单位值。
计算机的基本单位
计算机中的信息用二进制表示,常用的单位有位、字节和字。
-
位(bit):是计算机中最小的数据单位,存放一位二进制数,即0或1。它也是存储器存储信息的最小单位,通常用“b”来表示。
-
字节(Byte):字节是计算机中表示存储容量的最常用的基本单位。一个字节由8位二进制数组成,通常用“B”表示。一个字符占一个字节,一个汉字占两个字节。其它常见的存储单位有:
存储容量的计量单位有字节B、千字节KB、兆字节MB以及十亿字节GB等。它们之间的换算关系如下:
1KB (Kilobyte 千字节)=1024B,
1MB (Megabyte 兆字节 简称“兆”)=1024KB,
1GB (Gigabyte 吉字节 又称“千兆”)=1024MB,
1TB (Trillionbyte 万亿字节 太字节)=1024GB,
1PB(Petabyte 千万亿字节 拍字节)=1024TB,
1EB(Exabyte 百亿亿字节 艾字节)=1024PB,
1ZB (Zettabyte 十万亿亿字节 泽字节)= 1024 EB,
1YB (Jottabyte 一亿亿亿字节 尧字节)= 1024 ZB,
1BB (Brontobyte 一千亿亿亿字节)= 1024 YB
- 字(Word)与字长:字是指在计算机中作为一个整体被存取、传送、处理的一组二进制数。一个字的位数(即字长)是计算机系统结构中的一个重要特性。字长是由CPU的类型所决定,不同的计算机系统的字长是不同的,常见的有8位、16位、32位、64位等,字长越长,计算机一次处理的信息位就越多,精度就越高,字长是计算机性能的一个重要指标,目前主流微机正在由32位机向64位机转变。
注意字与字长的区别,字是单位,而字长是指标。
机器的字长也会影响机器的运算速度。倘若CPU字长较短,又要运算位数较多的数据,那么需要经过两次或多次的运算才能完成,这样势必影响整机的运行速度。
机器的字长对硬件的造价也有较大的影响。它将直接影响加法器(或ALU),数据总线以及存储字长的位数。所以机器字长的确不能单从精度和数的表示范围来考虑。
为了适应不同的要求及协调运算精度和硬件造价间的关系,大多数计算机均支持变字长运算,即机内可实现半字长、全字长(或单字长)和双倍字长运算。
计算机的编码方式
- 表示方式
符号位 + 二进制数
- 原码、反码、补码
- 原码
原码就是符号位加上真值的绝对值,即用第一位表示符号,其余位表示值。比如:如果是 \(8\) 位二进制:
\([+1]_原\) = 0000 0001
\([-1]原\) = 1000 0001
第一位是符号位,因为第一位是符号位,所以8位二进制数的取值范围就是:(即第一位不表示值,只表示正负。)
\([1111 1111 , 0111 1111]\) 即 \([-127 , 127]\)
原码是人脑最容易理解和计算的表示方式。
- 反码
反码的表示方法是:
正数的反码是其本身;
负数的反码是在其原码的基础上,符号位不变,其余各个位取反。
\([+1]\) = \([0000 0001]_原\) = \([0000 0001]_反\)
\([-1]\) = \([1000 0001]_原\) = \([1111 1110]_反\)
可见如果一个反码表示的是负数,人脑无法直观的看出来它的数值。通常要将其转换成原码再计算。
- 补码
补码的表示方法是:
正数的补码就是其本身;
负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1。(也即在反码的基础上+1)
\([+1]\) = \([0000 0001]_原\) = \([0000 0001]_反\) = \([0000 0001]_补\)
\([-1]\) = \([1000 0001]_原\) = \([1111 1110]_反\) = \([1111 1111]_补\)
对于负数,补码表示方式也是人脑无法直观看出其数值的。通常也需要转换成原码再计算其数值。
位运算
- 位运算概述
从现代计算机中所有的数据二进制的形式存储在设备中。即 0、1 两种状态,计算机对二进制数据进行的运算(+、-、*、/)都是叫位运算,即将符号位共同参与运算的运算。
口说无凭,举一个简单的例子来看下 CPU 是如何进行计算的,比如这行代码:
int a = 35;
int b = 47;
int c = a + b;
计算两个数的和,因为在计算机中都是以二进制来进行运算,所以上面我们所给的 int 变量会在机器内部先转换为二进制在进行相加:
35: 0 0 1 0 0 0 1 1
47: 0 0 1 0 1 1 1 1
————————————————————
82: 0 1 0 1 0 0 1 0
所以,相比在代码中直接使用(+、-、*、/)运算符,合理的运用位运算更能显著提高代码在机器上的执行效率。
- 位运算概览
| 符号 | 描述 | 运算规则 |
|---|---|---|
| & | 与 | 两个位都为 \(1\) 时,结果才为 \(1\) |
| \ | 或 | 两个位都为 \(0\) 时,结果才为 \(0\) |
| ^ | 异或 | 两个位相同为 \(0\),相异为 \(1\) |
| ~ | 取反 | \(0\) 变 \(1\),\(1\) 变 \(0\) |
| << | 左移 | 各二进位全部左移若干位,高位丢弃,低位补 \(0\) |
| >> | 右移 | 各二进位全部右移若干位,对无符号数,高位补 \(0\),有符号数,各编译器处理方法不一样,有的补符号位(算术右移),有的补 \(0\)(逻辑右移) |
- 异或交换两个数
int x = 5, y = 3;
x ^= y;
y ^= x;
x ^= y;
cout << x << " " << y;
以上代码输出 3 5
- 交换符号
int reversal(int x) {
return ~x + 1;
}
- 求平均值
int average(int x, int y) {
return (x & y) + ((x ^ y) >> 1);
}
- 判断是否为 \(2\) 的幂
int power2(int x) {
return ((x & (x - 1) == 0) && (x != 0);
}
- 求绝对值
int abs(int x) {
int i = x >> 31;
return (x ^ i) - i;
}
- 按位枚举
int sum(unsigned int x) {
int count = 0;
while(x != 0) {
x = x & (x - 1);
++count;
}
return count;
}
格雷码
典型的二进制格雷码(Binary Gray Code)简称格雷码,因1953年公开的弗兰克·格雷(Frank Gray,18870913-19690523)专利“Pulse Code Communication”而得名,当初是为了通信,现在则常用于模拟-数字转换和位置-数字转换中。
在一组数的编码中,若任意两个相邻的代码只有一位二进制数不同,则称这种编码为格雷码(Gray Code),另外由于最大数与最小数之间也仅一位数不同,即“首尾相连”,因此又称循环码或反射码。在数字系统中,常要求代码按一定顺序变化。例如,按自然数递增计数,若采用 \(8421\) 码,则数 \(0111\) 变到 \(1000\) 时四位均要变化,而在实际电路中,\(4\) 位的变化不可能绝对同时发生,则计数中可能出现短暂的其它代码(\(1100\)、 \(1111\) 等)。在特定情况下可能导致电路状态错误或输入错误。使用格雷码可以避免这种错误。格雷码有多种编码形式。
| 十进制数 | 4位自然二进制码 | 4位典型格雷码 | 十进制余三格雷码 | 十进制空六格雷码 | 十进制跳六格雷码 | 步进码 |
|---|---|---|---|---|---|---|
| 0 | 0000 | 0000 | 0010 | 0000 | 0000 | 00000 |
| 1 | 0001 | 0001 | 0110 | 0001 | 0001 | 00001 |
| 2 | 0010 | 0011 | 0111 | 0011 | 0011 | 00011 |
| 3 | 0011 | 0010 | 0101 | 0010 | 0010 | 00111 |
| 4 | 0100 | 0110 | 0100 | 0110 | 0110 | 01111 |
| 5 | 0101 | 0111 | 1100 | 1110 | 0111 | 11111 |
| 6 | 0110 | 0101 | 1101 | 1010 | 0101 | 11110 |
| 7 | 0111 | 0100 | 1111 | 1011 | 0100 | 11100 |
| 8 | 1000 | 1100 | 1110 | 1001 | 1100 | 11000 |
| 9 | 1001 | 1101 | 1010 | 1000 | 1000 | 10000 |
| 10 | 1010 | 1111 | ---- | ---- | ---- | ---- |
| 11 | 1011 | 1110 | ---- | ---- | ---- | ---- |
| 12 | 1100 | 1010 | ---- | ---- | ---- | ---- |
| 13 | 1101 | 1011 | ---- | ---- | ---- | ---- |
| 14 | 1110 | 1001 | ---- | ---- | ---- | ---- |
| 15 | 1111 | 1000 | ---- | ---- | ---- | ---- |
本文来自博客园,作者:So_noSlack,转载请注明原文链接:https://www.cnblogs.com/So-noSlack/p/17542842.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号